Brilhante na Databricks
Shiny é um pacote R, disponível no CRAN, usado para criar aplicativos e painéis interativos em R. O senhor pode usar o Shiny dentro do RStudio Server hospedado no Databricks clustering. O senhor também pode desenvolver, hospedar e compartilhar aplicativos Shiny diretamente de um Notebook Databricks.
Para começar a usar o Shiny, consulte o tutorial do Shiny. O senhor pode executar esse tutorial em Databricks Notebook.
Este artigo descreve como executar aplicativos Shiny em Databricks e usar Apache Spark dentro de aplicativos Shiny.
Notebook brilhante dentro do R
Comece a usar o Shiny no R Notebook
O pacote Shiny está incluído no Databricks Runtime. O senhor pode desenvolver e testar interativamente aplicativos Shiny dentro do Databricks R Notebook de forma semelhante ao RStudio hospedado.
Siga estas etapas para começar:
-
Criar um R Notebook.
-
Importe o pacote Shiny e execute o aplicativo de exemplo
01_helloda seguinte forma:Rlibrary(shiny)
runExample("01_hello") -
Quando o aplicativo estiver pronto, o resultado incluirá o URL do aplicativo Shiny como um link clicável que abre um novo site tab. Para compartilhar esse aplicativo com outros usuários, consulte Compartilhar URL do aplicativo Shiny.
- As mensagens de registro aparecem no resultado do comando, semelhante à mensagem default log (
Listening on http://0.0.0.0:5150) mostrada no exemplo. - Para interromper o aplicativo Shiny, clique em Cancelar .
- O aplicativo Shiny usa o processo do Notebook R. Se o usuário desconectar o Notebook do clustering ou se cancelar a célula que está executando o aplicativo, o aplicativo Shiny será encerrado. O senhor não pode executar outras células enquanto o aplicativo Shiny estiver em execução.
execução de aplicativos Shiny a partir de Databricks Git pastas
O senhor pode executar aplicativos Shiny que foram verificados nas pastasDatabricks Git.
-
execução do aplicativo.
Rlibrary(shiny)
runApp("006-tabsets")
execução de aplicativos Shiny a partir de arquivos
Se o código do seu aplicativo Shiny fizer parte de um projeto gerenciado pelo controle de versão, o senhor poderá executá-lo dentro do Notebook.
Você deve usar o caminho absoluto ou definir o diretório de trabalho com setwd().
-
Confira o código de um repositório usando um código semelhante a:
%sh git clone https://github.com/rstudio/shiny-examples.git
cloning into 'shiny-examples'... -
Para executar o aplicativo, digite um código semelhante ao seguinte em outra célula:
Rlibrary(shiny)
runApp("/databricks/driver/shiny-examples/007-widgets/")
Compartilhe o URL do aplicativo Shiny
O URL do aplicativo Shiny gerado quando o usuário inicia um aplicativo pode ser compartilhado com outros usuários. Qualquer usuário do Databricks com permissão CAN ATTACH TO no clustering pode view e interagir com o aplicativo, desde que o aplicativo e o clustering estejam em execução.
Se o clustering no qual o aplicativo está sendo executado for encerrado, o aplicativo não poderá mais ser acessado. O senhor pode desativar o encerramento automático nas configurações de clustering.
Se o senhor anexar e executar o Notebook que hospeda o aplicativo Shiny em um clustering diferente, o URL do Shiny será alterado. Além disso, se o senhor reiniciar o aplicativo no mesmo clustering, o Shiny poderá escolher uma porta aleatória diferente. Para garantir um URL estável, o senhor pode definir a opção shiny.port ou, ao reiniciar o aplicativo no mesmo clustering, pode especificar o argumento port.
Shiny no RStudio Server hospedado
Requisitos
Com o RStudio Server Pro, o senhor deve desativar a autenticação proxy.
Certifique-se de que auth-proxy=1 não esteja presente em /etc/rstudio/rserver.conf.
Comece a usar o Shiny em um servidor RStudio hospedado
-
Abra o RStudio na Databricks.
-
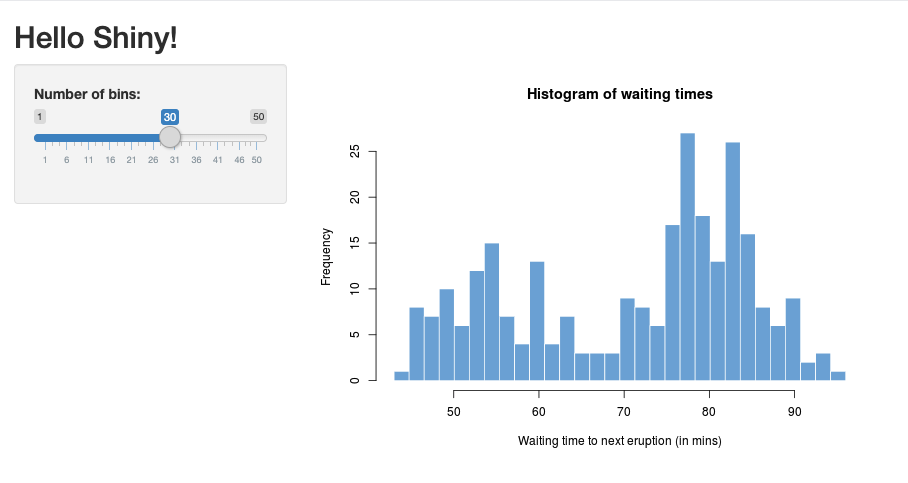
Em RStudio, importe o pacote Shiny e execute o aplicativo de exemplo
01_helloda seguinte forma:R> library(shiny)
> runExample("01_hello")
Listening on http://127.0.0.1:3203Uma nova janela aparece, exibindo o aplicativo Shiny.
executar um aplicativo Shiny a partir de um script R
Para executar um aplicativo Shiny a partir de um script R, abra o script R no editor RStudio e clique no botão Executar aplicativo no canto superior direito.
Usar o Apache Spark em aplicativos Shiny
O senhor pode usar Apache Spark dentro de aplicativos Shiny com SparkR ou Sparklyr.
Use SparkR com Shiny em um Notebook
library(shiny)
library(SparkR)
sparkR.session()
ui <- fluidPage(
mainPanel(
textOutput("value")
)
)
server <- function(input, output) {
output$value <- renderText({ nrow(createDataFrame(iris)) })
}
shinyApp(ui = ui, server = server)
Use Sparklyr com Shiny em um Notebook
library(shiny)
library(sparklyr)
sc <- spark_connect(method = "databricks")
ui <- fluidPage(
mainPanel(
textOutput("value")
)
)
server <- function(input, output) {
output$value <- renderText({
df <- sdf_len(sc, 5, repartition = 1) %>%
spark_apply(function(e) sum(e)) %>%
collect()
df$result
})
}
shinyApp(ui = ui, server = server)
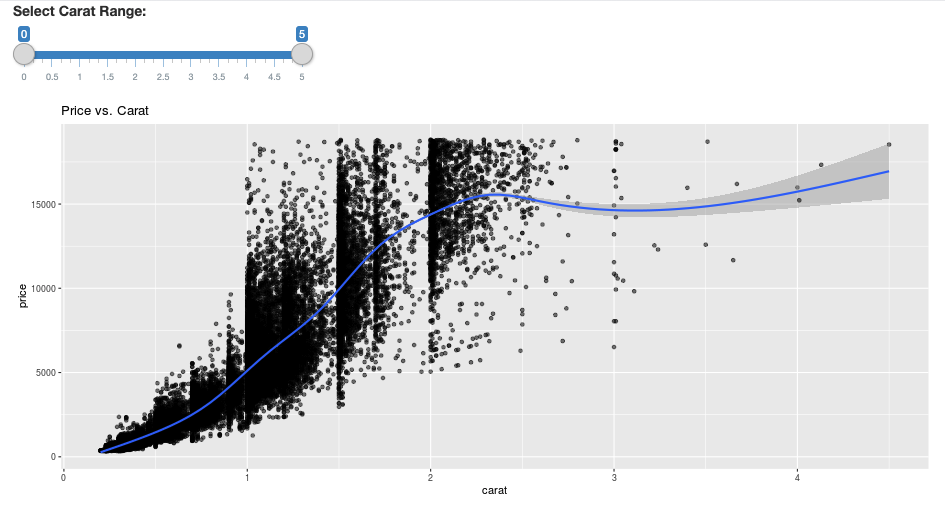
library(dplyr)
library(ggplot2)
library(shiny)
library(sparklyr)
sc <- spark_connect(method = "databricks")
diamonds_tbl <- spark_read_csv(sc, path = "/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
# Define the UI
ui <- fluidPage(
sliderInput("carat", "Select Carat Range:",
min = 0, max = 5, value = c(0, 5), step = 0.01),
plotOutput('plot')
)
# Define the server code
server <- function(input, output) {
output$plot <- renderPlot({
# Select diamonds in carat range
df <- diamonds_tbl %>%
dplyr::select("carat", "price") %>%
dplyr::filter(carat >= !!input$carat[[1]], carat <= !!input$carat[[2]])
# Scatter plot with smoothed means
ggplot(df, aes(carat, price)) +
geom_point(alpha = 1/2) +
geom_smooth() +
scale_size_area(max_size = 2) +
ggtitle("Price vs. Carat")
})
}
# Return a Shiny app object
shinyApp(ui = ui, server = server)
Perguntas frequentes (FAQ)
- Por que meu aplicativo Shiny fica acinzentado depois de algum tempo?
- Por que minha janela do Shiny Viewer desaparece depois de um tempo?
- Por que o senhor nunca mais volta a trabalhar no site Spark?
- Como posso evitar o tempo limite?
- Meu aplicativo trava imediatamente após o lançamento, mas o código parece estar correto. O que está acontecendo?
- Quantas conexões podem ser aceitas para um link do aplicativo Shiny durante o desenvolvimento?
- Posso usar uma versão do pacote Shiny diferente da que está instalada no Databricks Runtime?
- Como posso desenvolver um aplicativo Shiny que possa ser publicado em um servidor Shiny e acessar dados no Databricks?
- Posso desenvolver um aplicativo Shiny dentro de um notebook Databricks?
- Como posso salvar os aplicativos Shiny que desenvolvi no RStudio Server hospedado?
Por que meu aplicativo Shiny fica acinzentado depois de algum tempo?
Se não houver interação com o aplicativo Shiny, a conexão com o aplicativo será fechada após cerca de 10 minutos.
Para se reconectar, acesse refresh a página do aplicativo Shiny. O estado do painel Reset.
Por que minha janela do Shiny Viewer desaparece depois de um tempo?
Se a janela do Shiny Viewer desaparecer após ficar inativa por vários minutos, isso ocorre devido ao mesmo tempo limite do cenário de “esgotamento cinza”.
Por que o senhor nunca mais volta a trabalhar no site Spark?
Isso também se deve ao tempo limite do parado. Qualquer trabalho do Spark executado por mais tempo do que os tempos limite mencionados anteriormente não poderá renderizar seu resultado porque a conexão será fechada antes do retorno do trabalho.
Como posso evitar o tempo limite?
-
Há uma solução alternativa sugerida na solicitação de recurso: fazer com que o cliente envie uma mensagem de keep alive para evitar o tempo limite do TCP em alguns balanceadores de carga no Github. A solução alternativa envia heartbeats para manter a conexão WebSocket ativa quando o aplicativo é parado. No entanto, se o aplicativo for bloqueado por uma computação de longa duração, essa solução alternativa não funcionará.
-
O Shiny não oferece suporte a tarefas de longa duração. Uma postagem do Shiny no blog recomenda o uso de promises e futures para executar tarefas longas de forma assíncrona e manter o aplicativo desbloqueado. Aqui está um exemplo que usa heartbeats para manter o aplicativo Shiny ativo e executa um trabalho Spark de longa duração em uma construção
future.R# Write an app that uses spark to access data on Databricks
# First, install the following packages:
install.packages('future')
install.packages('promises')
library(shiny)
library(promises)
library(future)
plan(multisession)
HEARTBEAT_INTERVAL_MILLIS = 1000 # 1 second
# Define the long Spark job here
run_spark <- function(x) {
# Environment setting
library("SparkR", lib.loc = "/databricks/spark/R/lib")
sparkR.session()
irisDF <- createDataFrame(iris)
collect(irisDF)
Sys.sleep(3)
x + 1
}
run_spark_sparklyr <- function(x) {
# Environment setting
library(sparklyr)
library(dplyr)
library("SparkR", lib.loc = "/databricks/spark/R/lib")
sparkR.session()
sc <- spark_connect(method = "databricks")
iris_tbl <- copy_to(sc, iris, overwrite = TRUE)
collect(iris_tbl)
x + 1
}
ui <- fluidPage(
sidebarLayout(
# Display heartbeat
sidebarPanel(textOutput("keep_alive")),
# Display the Input and Output of the Spark job
mainPanel(
numericInput('num', label = 'Input', value = 1),
actionButton('submit', 'Submit'),
textOutput('value')
)
)
)
server <- function(input, output) {
#### Heartbeat ####
# Define reactive variable
cnt <- reactiveVal(0)
# Define time dependent trigger
autoInvalidate <- reactiveTimer(HEARTBEAT_INTERVAL_MILLIS)
# Time dependent change of variable
observeEvent(autoInvalidate(), { cnt(cnt() + 1) })
# Render print
output$keep_alive <- renderPrint(cnt())
#### Spark job ####
result <- reactiveVal() # the result of the spark job
busy <- reactiveVal(0) # whether the spark job is running
# Launch a spark job in a future when actionButton is clicked
observeEvent(input$submit, {
if (busy() != 0) {
showNotification("Already running Spark job...")
return(NULL)
}
showNotification("Launching a new Spark job...")
# input$num must be read outside the future
input_x <- input$num
fut <- future({ run_spark(input_x) }) %...>% result()
# Or: fut <- future({ run_spark_sparklyr(input_x) }) %...>% result()
busy(1)
# Catch exceptions and notify the user
fut <- catch(fut, function(e) {
result(NULL)
cat(e$message)
showNotification(e$message)
})
fut <- finally(fut, function() { busy(0) })
# Return something other than the promise so shiny remains responsive
NULL
})
# When the spark job returns, render the value
output$value <- renderPrint(result())
}
shinyApp(ui = ui, server = server) -
Há um limite rígido de 12 horas desde o carregamento inicial da página, após o qual qualquer conexão, mesmo que ativa, será encerrada. O senhor deve acessar refresh o aplicativo Shiny para se reconectar nesses casos. No entanto, a conexão WebSocket subjacente pode ser fechada a qualquer momento por diversos fatores, inclusive instabilidade da rede ou modo de suspensão do computador. A Databricks recomenda reescrever os aplicativos Shiny de modo que eles não exijam uma conexão de longa duração e não dependam excessivamente do estado da sessão.
Meu aplicativo trava imediatamente após o lançamento, mas o código parece estar correto. O que está acontecendo?
Há um limite de 50 MB para a quantidade total de dados que podem ser exibidos em um aplicativo Shiny na Databricks. Se o tamanho total dos dados do aplicativo exceder esse limite, ele falhará imediatamente após o lançamento. Para evitar isso, a Databricks recomenda reduzir o tamanho dos dados, por exemplo, diminuindo a amostragem dos dados exibidos ou reduzindo a resolução das imagens.
Quantas conexões podem ser aceitas para um link do aplicativo Shiny durante o desenvolvimento?
A Databricks recomenda até 20.
Posso usar uma versão do pacote Shiny diferente da que está instalada no Databricks Runtime?
Sim. Consulte Corrigir a versão do pacote R.
Como posso desenvolver um aplicativo Shiny que possa ser publicado em um servidor Shiny e acessar dados no Databricks?
Embora o senhor possa acessar os dados naturalmente usando SparkR ou Sparklyr durante o desenvolvimento e os testes em Databricks, depois que um aplicativo Shiny é publicado em um serviço de hospedagem autônomo, ele não pode acessar diretamente os dados e as tabelas em Databricks.
Para permitir que seu aplicativo funcione fora do Databricks, o senhor deve reescrever como acessa os dados. Há algumas opções:
- Use JDBC/ODBC para enviar consultas a um Databricks clustering.
- Use o Databricks Connect.
- Acesse diretamente os dados no armazenamento de objetos.
Databricks recomenda que o senhor trabalhe com sua equipe de soluções Databricks para encontrar a melhor abordagem para sua arquitetura analítica e de dados existente.
Posso desenvolver um aplicativo Shiny dentro de um notebook Databricks?
Sim, o senhor pode desenvolver um aplicativo Shiny dentro de um Databricks Notebook.
Como posso salvar os aplicativos Shiny que desenvolvi no RStudio Server hospedado?
O senhor pode salvar o código do aplicativo no DBFS ou verificar o código no controle de versão.