Visão materializada
Assim como a visualização padrão, a visualização materializada são os resultados de uma consulta e você os acessa da mesma forma que acessaria uma tabela. Diferentemente da visualização padrão, que recalcula os resultados em cada consulta, a visualização materializada armazena os resultados em cache e os atualiza em um intervalo especificado. Como uma view materializada é pré-computada, as consultas nela podem ser executadas muito mais rápido do que em uma visão regular.
Uma view materializada é um objeto pipeline declarativo. Inclui uma consulta que o define, um fluxo para atualizá-lo e os resultados armazenados em cache para acesso rápido. Uma view materializada:
- Rastreia alterações em dados upstream.
- No gatilho, processa incrementalmente os dados alterados e aplica as transformações necessárias.
- Mantém a tabela de saída sincronizada com os dados de origem, com base em um intervalo refresh especificado.
As visualizações materializadas são uma boa escolha para muitas transformações:
- Você aplica o raciocínio sobre resultados armazenados em cache em vez de linhas. Na verdade, você simplesmente escreve uma consulta.
- Eles estão sempre certos. Todos os dados necessários são processados, mesmo que cheguem atrasados ou fora de ordem.
- Elas geralmente são incrementais. Databricks tentará escolher a estratégia apropriada que minimize o custo de atualização de uma view materializada.
Como funciona a visualização materializada
O diagrama a seguir ilustra como a visualização materializada funciona.

As visões materializadas são definidas e atualizadas por um único pipeline. Você pode definir explicitamente a visualização materializada no código-fonte do pipeline. Tabelas definidas por um pipeline não podem ser alteradas ou atualizadas por nenhum outro pipeline.
Ao criar uma view materializada fora de um pipeline, usando Databricks SQL, Databricks cria um pipeline que é usado para atualizar a view. Você pode visualizar o pipeline selecionando "Tarefas e pipeline" na navegação à esquerda do seu workspace. Você pode adicionar a coluna do tipo de pipeline à sua view. A visão materializada definida em um pipeline tem um tipo de ETL. A visão materializada criada no Databricks SQL tem um tipo de MV/ST.
Databricks usa Unity Catalog para armazenar metadados sobre a view, incluindo a consulta e a visualização adicional do sistema que são usadas para atualizações incrementais. Os dados armazenados em cache são materializados no armazenamento cloud .
O exemplo a seguir une duas tabelas e mantém o resultado atualizado usando uma view materializada.
- Python
- SQL
from pyspark import pipelines as dp
@dp.materialized_view
def regional_sales():
partners_df = spark.read.table("partners")
sales_df = spark.read.table("sales")
return (
partners_df.join(sales_df, on="partner_id", how="inner")
)
CREATE OR REPLACE MATERIALIZED VIEW regional_sales
AS SELECT *
FROM partners
INNER JOIN sales ON
partners.partner_id = sales.partner_id;
Atualizações incrementais automáticas
Quando o pipeline que define uma view materializada é acionado, a view é automaticamente mantida atualizada, geralmente de forma incremental. Databricks tenta processar apenas os dados que precisam ser processados para manter a view materializada atualizada. Uma view materializada sempre mostra o resultado correto, mesmo que exija o recálculo completo do resultado da consulta do zero, mas muitas vezes Databricks faz apenas atualizações incrementais em uma view materializada, o que pode ser muito menos custoso do que um recálculo completo.
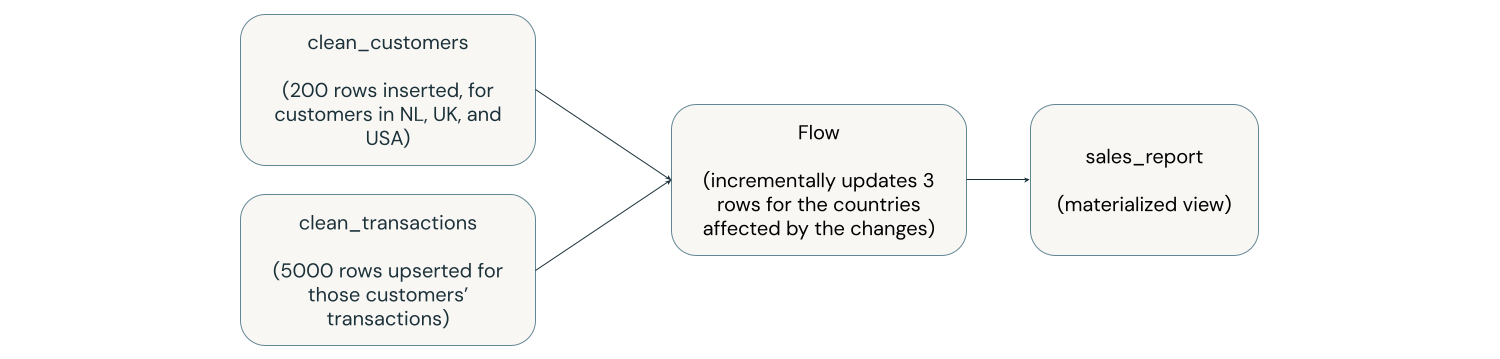
O diagrama abaixo mostra uma view materializada chamada sales_report, que é o resultado da junção de duas tabelas upstream chamadas clean_customers e clean_transactions e do agrupamento por país. Um processo upstream insere 200 linhas em clean_customers em três países (EUA, Holanda, Reino Unido) e atualiza 5.000 linhas em clean_transactions correspondentes a esses novos clientes. A view materializada sales_report é atualizada incrementalmente apenas para os países que têm novos clientes ou transações correspondentes. Neste exemplo, vemos três linhas atualizadas em vez do relatório de vendas inteiro.
Para obter mais detalhes sobre como refresh incremental funciona na visualização materializada, consulte refresh incremental para visualização materializada.
Limitações da visualização materializada
A visualização materializada tem as seguintes limitações:
- Como as atualizações criam consultas corretas, algumas alterações nas entradas exigirão um recomputamento completo de uma view materializada, o que pode ser caro.
- Eles não foram projetados para casos de uso de baixa latência. A latência de atualização de uma view materializada é em segundos ou minutos, não em milissegundos.
- Nem todos os cálculos podem ser feitos de forma incremental.