Introdução aos objetos do site workspace
Este artigo apresenta uma introdução de alto nível dos objetos do workspace do Databricks. Você pode criar, visualizar e organizar objetos do workspace no navegador do workspace entre personas.
Observação sobre como nomear workspace ativo
O nome completo de um workspace ativo consiste em seu nome de base e sua extensão de arquivo . Por exemplo, a extensão de arquivo de um Notebook pode ser .py, .sql, .scala, .r e .ipynb, dependendo do idioma e do formato do Notebook.
Quando o senhor cria um Notebook ativo, seu nome básico e seu nome completo (o nome básico concatenado com a extensão do arquivo) devem ser exclusivos em qualquer pasta do site workspace. Quando o senhor nomeia um ativo, o Databricks verifica se ele atende a esse critério, adicionando a extensão de arquivo a ele. Se o nome completo corresponder a um arquivo existente na pasta, esse nome não será permitido e o senhor deverá escolher um novo nome para o Notebook. Por exemplo, se o senhor tentar criar um Notebook Python (no formato de fonte Python ) chamado test na mesma pasta que um arquivo Python chamado test.py, isso não será permitido.
agrupamento
Databricks ciência de dados & engenharia e Databricks Mosaic AI clustering fornecem uma plataforma unificada para vários casos de uso, como a execução do pipeline de produção ETL, transmissão analítica, análise ad-hoc e aprendizado de máquina. Um clustering é um tipo de Databricks compute recurso . Outros tipos de recurso compute incluem Databricks SQL warehouse.
Para obter informações detalhadas sobre como gerenciar e usar o clustering, consulte computação.
Caderno de anotações
Um Notebook é uma interface baseada na Web para documentos que contêm uma série de células executáveis (comando) que operam em arquivos e tabelas, visualizações e texto narrativo. comando pode ser executado em sequência, referindo-se à saída de um ou mais comandos executados anteriormente.
O notebook é um mecanismo para executar o código em Databricks. O outro mecanismo é o Job.
Para obter informações detalhadas sobre como gerenciar e usar o Notebook, consulte Databricks Notebook.
Empregos
Os jobs são um mecanismo para executar código no Databricks. O outro mecanismo é notebooks.
Para obter informações detalhadas sobre como gerenciar e usar o Job, consulte LakeFlow Jobs.
biblioteca
Uma biblioteca disponibiliza códigos de terceiros ou criados localmente para notebooks e jobs executados em seus clusters.
Para obter informações detalhadas sobre como gerenciar e usar o biblioteca, consulte Instalar o biblioteca.
Dados
Você pode importar dados para um sistema de arquivos distribuído montado em um workspace do Databricks e trabalhar com eles em notebooks e clusters do Databricks. Você também pode usar uma grande variedade de fontes de dados do Apache Spark para acessar os dados.
Para obter informações detalhadas sobre o carregamento de dados, consulte Conectores padrão em LakeFlow Connect.
Arquivos
Visualização
Esse recurso está em Public Preview.
Em Databricks Runtime 11.3 LTS e acima, o senhor pode criar e usar arquivos arbitrários no Databricks workspace. Os arquivos podem ser de qualquer tipo de arquivo. Exemplos comuns de tipos de arquivo incluem:
.pyarquivos utilizados em módulos personalizados..mdarquivos comoREADME.md..csvou outros pequenos arquivos de dados..txtarquivos.- Arquivos de log.
Para obter informações detalhadas sobre o uso de arquivos, consulte Work with files em Databricks. Para obter informações sobre como usar arquivos para modularizar o código à medida que o senhor desenvolve com o Databricks Notebook, consulte Compartilhar código entre o Databricks Notebook
Pastas do Git
As pastas Git são pastas do Databricks cujo conteúdo é convertido em conjunto, sincronizando-as com um repositório Git remoto. Usando as pastas Databricks Git , é possível desenvolver o Notebook em Databricks e usar um repositório remoto Git para colaboração e controle de versão.
Para obter informações detalhadas sobre o uso de repositórios, consulte Pastas Git Databricks.
Modelos
Modelo refere-se a um modelo registrado no MLflow Model Registry. O Registro de Modelo é um repositório de modelos centralizado que permite gerenciar todo o ciclo de vida dos modelos MLflow. Ele fornece a linhagem cronológica do modelo, o controle de versão do modelo, as transições de estágio e as anotações e descrições do modelo e da versão do modelo.
Para obter informações detalhadas sobre como gerenciar e usar modelos, consulte gerenciar o ciclo de vida do modelo em Unity Catalog.
Experimentos
Um experimento MLflow é a principal unidade de organização e controle de acesso para MLflow modelo do machine learning treinamento execução. Todas as MLflow execuções pertencem a um experimento. Cada experimento permite que o senhor visualize, pesquise e compare a execução, e download e artefatos de execução ou metadados para análise em outras ferramentas.
Para obter informações detalhadas sobre o gerenciamento e o uso de experimentos, consulte Organize treinamento execution with MLflow experiments.
Consultas
As consultas são instruções SQL que permitem que o senhor interaja com seus dados. Para obter mais informações, consulte Acessar e gerenciar consultas salvas.
Painéis
Os painéis são apresentações de visualizações e comentários de consultas. Consulte Painéis ou painéis legados.
alerta
alerta são notificações de que um campo retornado por uma consulta atingiu um limite. Para obter mais informações, consulte Databricks SQL alerta.
Referências a objetos workspace
Historicamente, os usuários eram obrigados a incluir o prefixo do caminho /Workspace para algumas APIs da Databricks (%sh), mas não para outras (%run, entradas da API REST).
Os usuários podem usar os caminhos workspace com o prefixo /Workspace em qualquer lugar. Referências antigas a caminhos sem o prefixo /Workspace são redirecionadas e continuam funcionando. Recomendamos que todos os caminhos workspace tenham o prefixo /Workspace para diferenciá-los dos caminhos Volume e DBFS.
O pré-requisito para o comportamento consistente do prefixo de caminho /Workspace é o seguinte: Não pode haver uma pasta /Workspace no nível raiz do site workspace. Se o senhor tiver uma pasta /Workspace no nível raiz e quiser ativar esse aprimoramento de UX, exclua ou renomeie a pasta /Workspace que criou e entre em contato com a equipe Databricks account .
Compartilhar um arquivo, pasta ou URL do Notebook
Em seu Databricks workspace, os URLs dos arquivos workspace, do Notebook e das pastas estão nos formatos:
URLs de arquivos do espaço de trabalho
https://<databricks-instance>/?o=<16-digit-workspace-ID>#files/<16-digit-object-ID>
Notebook URLs
https://<databricks-instance>/?o=<16-digit-workspace-ID>#notebook/<16-digit-object-ID>/command/<16-digit-command-ID>
URLs de pastas (workspace e Git)
https://<databricks-instance>/browse/folders/<16-digit-ID>?o=<16-digit-workspace-ID>
Esses links podem ser interrompidos se qualquer pasta, arquivo ou Notebook no caminho atual for atualizado com um comando Git pull ou for excluído e recriado com o mesmo nome. No entanto, o senhor pode criar um link com base no caminho workspace para compartilhar com outros usuários do Databricks com níveis de acesso apropriados, alterando-o para um link nesse formato:
https://<databricks-instance>/?o=<16-digit-workspace-ID>#workspace/<full-workspace-path-to-file-or-folder>
Os links para pastas, Notebook e arquivos podem ser compartilhados substituindo tudo no URL após ?o=<16-digit-workspace-ID> pelo caminho para o arquivo, pasta ou Notebook na raiz do site workspace. Se o senhor estiver compartilhando um URL para uma pasta, remova também o endereço /browse/folders/<16-digit-ID> do URL original.
Para obter o caminho do arquivo, abra o menu de contexto clicando com o botão direito do mouse na pasta, no Notebook ou no arquivo do site workspace que deseja compartilhar e selecione Copy URL/path > Full path . Anexe #workspace ao caminho do arquivo que acabou de copiar e acrescente as strings resultantes após ?o=<16-digit-workspace-ID> para que correspondam ao formato de URL acima.
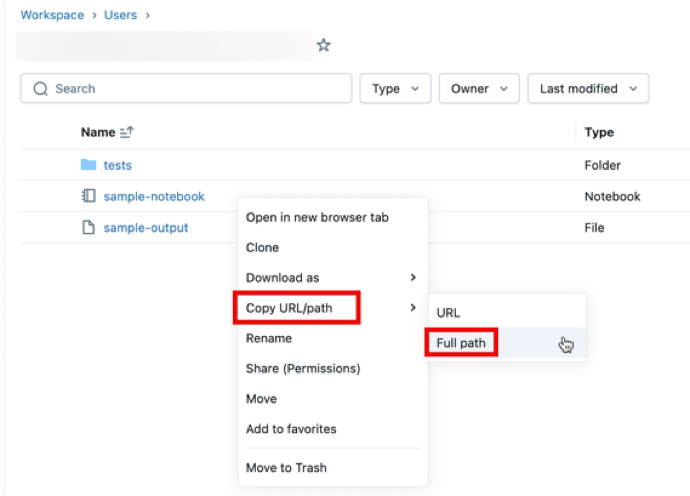
Exemplo de formulação de URL #1: URLs de pastas
Para compartilhar o URL https://<databricks-instance>/browse/folders/1111111111111111?o=2222222222222222 da pasta workspace, remova a substring browse/folders/1111111111111111 do URL. Adicione #workspace seguido do caminho para a pasta ou o objeto workspace que deseja compartilhar.
Nesse caso, o caminho workspace é para uma pasta, /Workspace/Users/user@example.com/team-git/notebooks. Depois de copiar o caminho completo do site workspace, o senhor pode criar o link compartilhável:
https://<databricks-instance>/?o=2222222222222222#workspace/Workspace/Users/user@example.com/team-git/notebooks
Exemplo de formulação de URL 2: Notebook URLs
Para compartilhar o URL do Notebook https://<databricks-instance>/?o=1111111111111111#notebook/2222222222222222/command/3333333333333333, remova #notebook/2222222222222222/command/3333333333333333. Adicione #workspace seguido do caminho para a pasta ou o objeto workspace.
Nesse caso, o caminho workspace aponta para um Notebook, /Workspace/Users/user@example.com/team-git/notebooks/v1.0/test-notebook. Depois de copiar o caminho completo do site workspace, o senhor pode criar o link compartilhável:
https://<databricks-instance>/?o=1111111111111111#workspace/Workspace/Users/user@example.com/team-git/notebooks/v1.0/test-notebook
Agora o senhor tem um URL estável para compartilhar um arquivo, pasta ou caminho do Notebook! Para obter mais informações sobre URLs e identificadores, consulte Obter identificadores para objetos workspace.