July 2020
These features and Databricks platform improvements were released in July 2020.
Releases are staged. Your Databricks account may not be updated until up to a week after the initial release date.
Web terminal (Public Preview)
July 29-Aug 4, 2020: Version 3.25
Web terminal provides a convenient and highly interactive way for users with CAN ATTACH TO permission on a cluster to run shell commands, including editors such as Vim or Emacs. Example uses of the web terminal include monitoring resource usage and installing Linux packages.
Unlike using SSH, web terminal can be used by many users on one cluster and does not require setting up keys.
For details, see Run shell commands in Databricks web terminal.
New, more secure global init script framework (Public Preview)
July 29 - August 4, 2020: Version 3.25
The new global init script framework brings significant improvements over legacy global init scripts:
- Init scripts are more secure, requiring admin permissions to create, view, and delete.
- Script-related launch failures are logged.
- You can set the execution order of multiple init scripts.
- Init scripts can reference cluster-related environment variables.
- Init scripts can be created and managed using the admin settings page or the new Global Init Scripts REST API.
Databricks recommends that you migrate existing legacy global init scripts to the new framework to take advantage of these improvements.
For details, see Global init scripts.
IP access lists now GA
July 29 - August 4, 2020: Version 3.25
The IP Access List API is now generally available.
The GA version includes one change, which is the renaming of the list_type values:
WHITELISTtoALLOWBLACKLISTtoBLOCK
Use the IP Access List API to configure your Databricks workspaces so that users connect to the service only through existing corporate networks with a secure perimeter. Databricks admins can use the IP Access List API to define a set of approved IP addresses, including allow and block lists. All incoming access to the web application and REST APIs requires that the user connect from an authorized IP address, guaranteeing that workspaces cannot be accessed from a public network like a coffee shop or an airport unless your users use VPN.
This feature requires the Enterprise plan.
For more information, see Configure IP access lists for workspaces.
New file upload dialog
July 29 - August 4, 2020: Version 3.25
You can now upload small tabular data files (like CSVs) and access them from a notebook by selecting Add data from the notebook File menu. Generated code shows you how to load the data into Pandas or DataFrames. Admins can disable this feature on the Admin Console Advanced tab.
For more information, see Browse files in DBFS.
SCIM API filter and sort improvements
July 29 - Aug 4, 2020: Version 3.25
The SCIM API now includes these filtering and sorting improvements:
- Admin users can filter users on the
activeattribute. - All users can sort results using the
sortByandsortOrderquery parameters. The default is to sort by ID.
Databricks Runtime 7.1 GA
July 21, 2020
Databricks Runtime 7.1 brings many additional features and improvements over Databricks Runtime 7.0, including:
- Google BigQuery connector
%pipcommands to manage Python libraries installed in a notebook session- Koalas installed
- Many Delta Lake improvements, including:
- Setting user-defined commit metadata
- Getting the version of the last commit written by the current
SparkSession - Converting Parquet tables created by Structured Streaming using the
_spark_metadatatransaction log MERGE INTOperformance improvements
For details, see the complete Databricks Runtime 7.1 (EoS) release notes.
Databricks Runtime 7.1 ML GA
July 21, 2020
Databricks Runtime 7.1 for Machine Learning is built on top of Databricks Runtime 7.1 and brings the following new features and library changes:
- pip and conda magic commands enabled by default
- spark-tensorflow-distributor: 0.1.0
- pillow 7.0.0 -> 7.1.0
- pytorch 1.5.0 -> 1.5.1
- torchvision 0.6.0 -> 0.6.1
- horovod 0.19.1 -> 0.19.5
- mlflow 1.8.0 -> 1.9.1
For details, see the complete Databricks Runtime 7.1 for ML (EoS) release notes.
Databricks Runtime 7.1 Genomics GA
July 21, 2020
Databricks Runtime 7.1 for Genomics is built on top of Databricks Runtime 7.1 and brings the following new features:
- LOCO transformation
- GloWGR output reshaping function
- RNASeq outputs unpaired alignments
Databricks Connect 7.1 (Public Preview)
July 17, 2020
Databricks Connect 7.1 is now in public preview.
IP Access List API updates
July 15-21, 2020: Version 3.24
The following IP Access List API properties have changed:
updator_user_idtoupdated_bycreator_user_idtocreated_by
Python notebooks now support multiple outputs per cell
July 15-21, 2020: Version 3.24
Python notebooks now support multiple outputs per cell. This means you can have any number of display, displayHTML, or print statements in a cell. Take advantage of the ability to view the raw data and the plot in the same cell, or all of the outputs that succeeded before you hit an error.
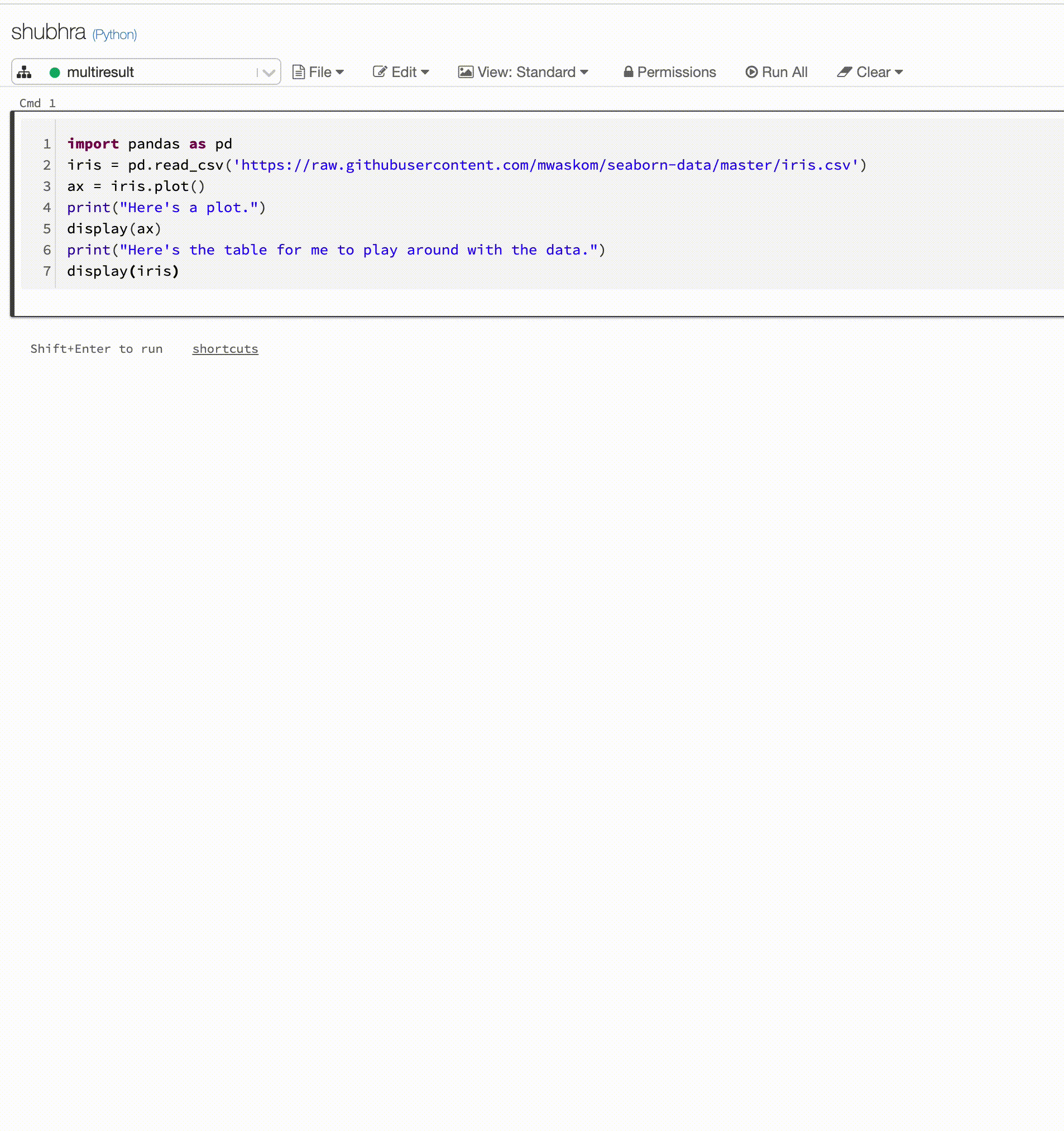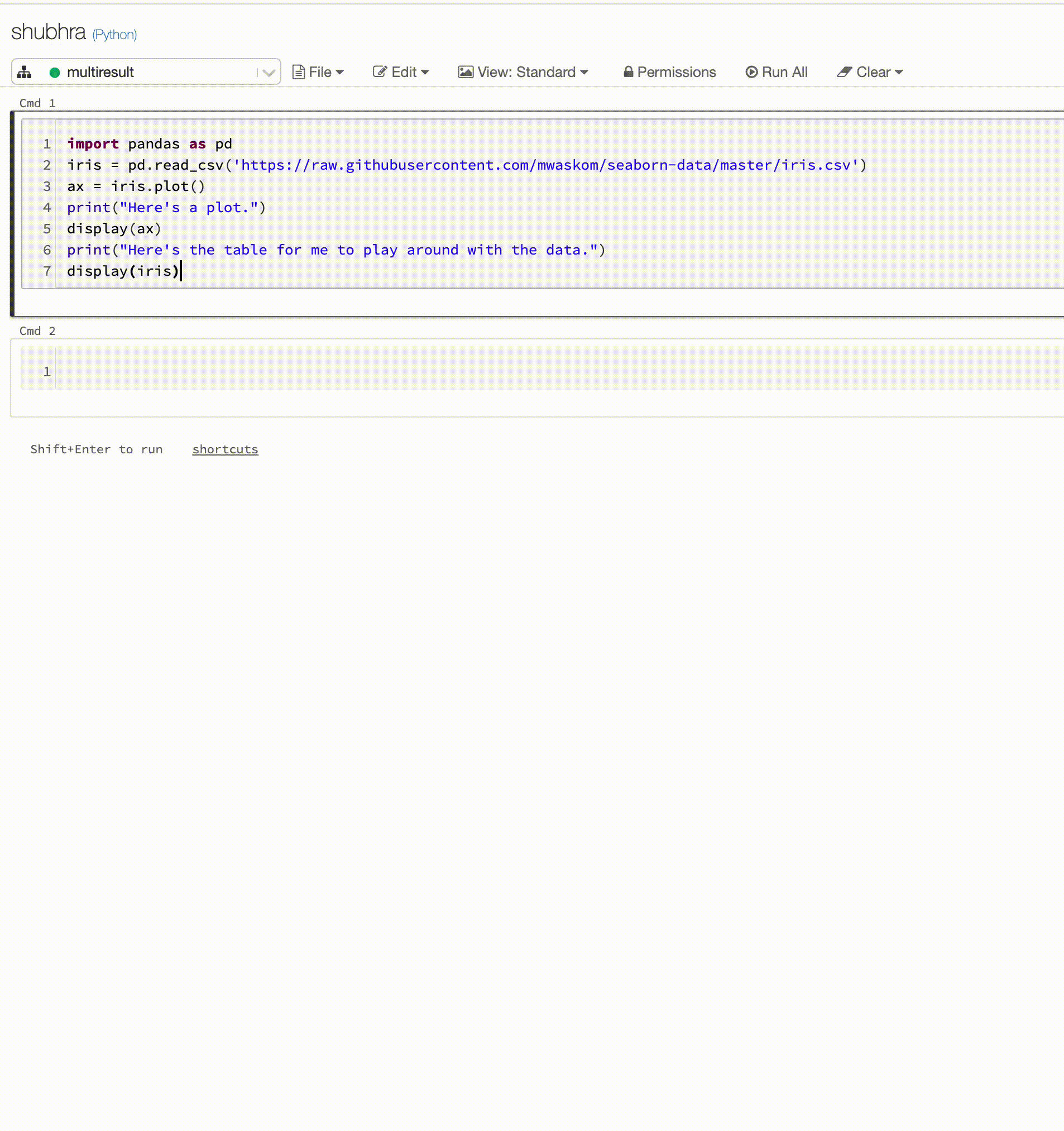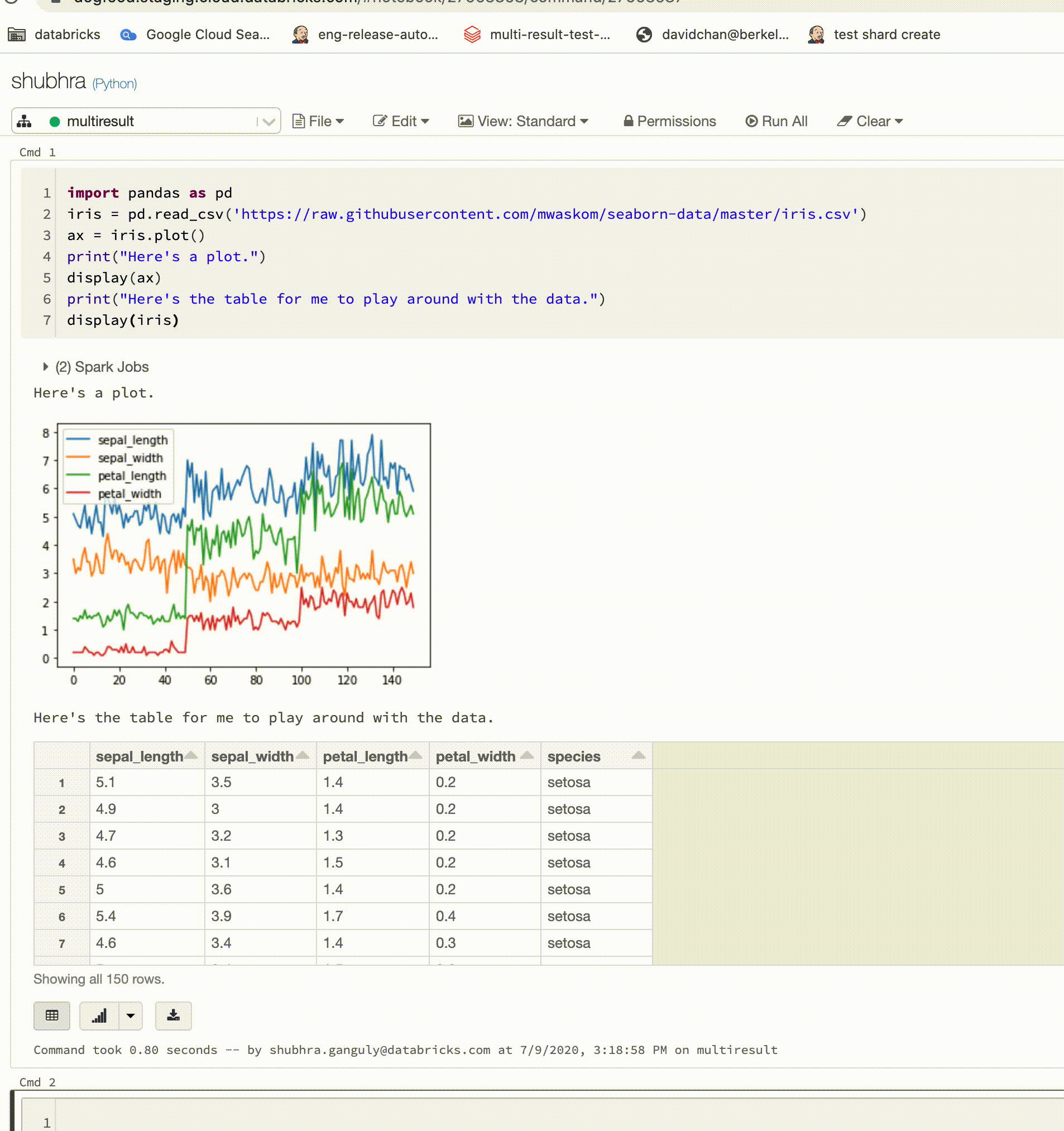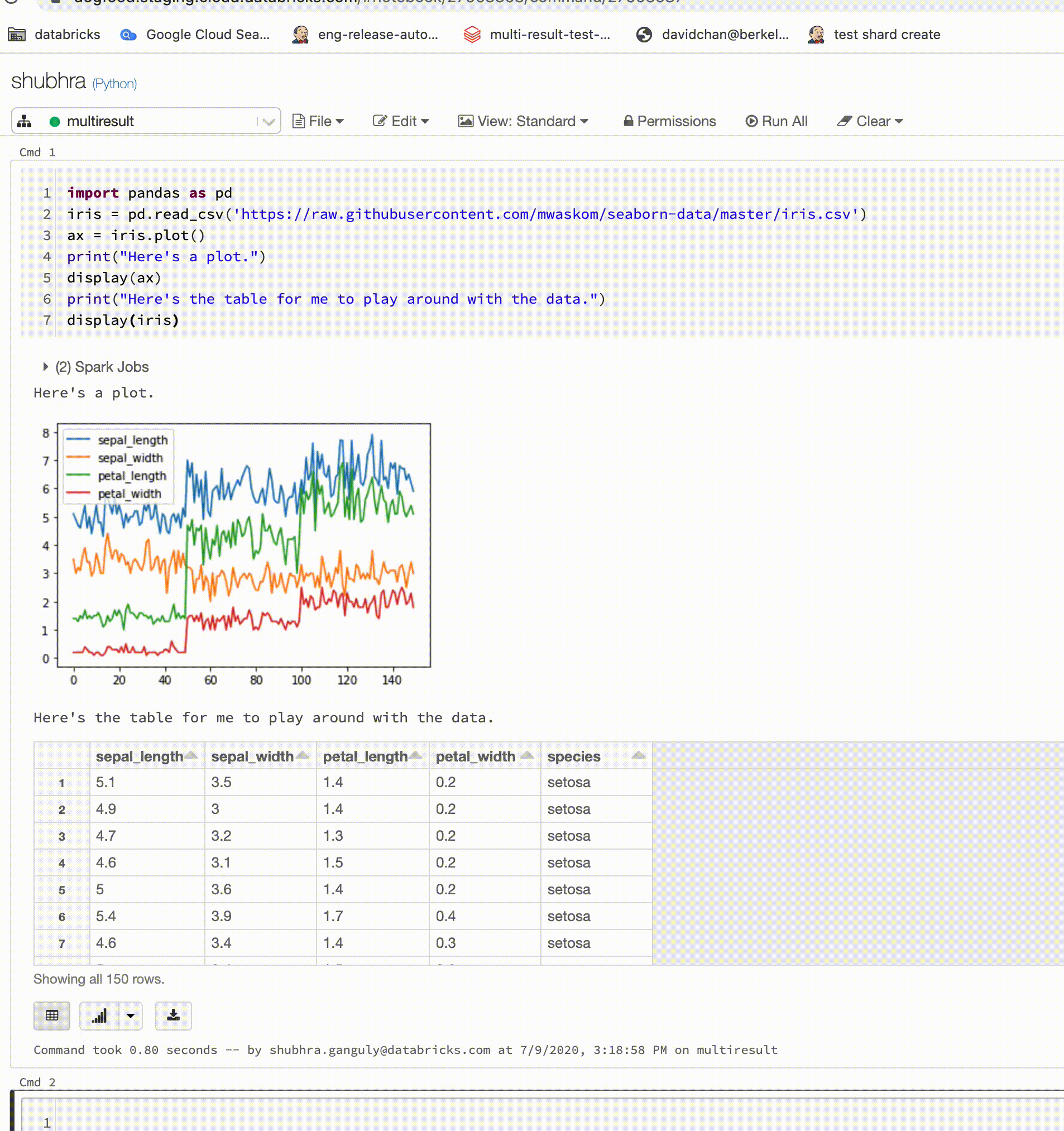
This feature requires Databricks Runtime 7.1 or above and is disabled by default in Databricks Runtime 7.1. Enable it by setting spark.databricks.workspace.multipleResults.enabled true.
View notebook code and results cells side by side
July 15-21, 2020: Version 3.24
The new Side-by-Side notebook display option lets you view code and results next to each other. This display option joins the “Standard” option (formerly “Code”) and the “Results Only” option.
Pause job schedules
July 15-21, 2020: Version 3.24
Jobs schedules now have Pause and Unpause buttons making it easy to pause and resume jobs. Now you can make changes to a job schedule without additional job runs starting while you are making the changes. Current runs or runs triggered by Run Now are not affected. For details, see Pause and resume job triggers.
Jobs API endpoints validate run ID
July 15-21, 2020: Version 3.24
The jobs/runs/cancel and jobs/runs/output API endpoints now validate that the run_id parameter is valid. For invalid parameters these API endpoints now return HTTP status code 400 instead of code 500.
Format SQL in notebooks automatically
July 15-21, 2020: Version 3.24
You can now format SQL notebook cells from a keyboard shortcut, the command context menu, and the notebook Edit menu (select Edit > Format SQL Cells). SQL formatting makes it easy to read and maintain code with little effort. It works for SQL notebooks as well as %sql cells.

Support for r5.8xlarge and r5.16xlarge instances
July 15-21, 2020: Version 3.24
With the addition of r5.8xlarge and r5.16xlarge, Databricks now supports the complete family of r5 EC2 instance types.
Use password access control to configure which users are required to log in using SSO or authenticate using tokens (Public Preview)
July 1-9, 2020: Version 3.23
If your Databricks workspace uses single sign-on (SSO), you can now assign password permissions to prevent admin users from using their username and password to log in to the Databricks UI. You can also deny non-admin users and groups the ability to authenticate to the Databricks REST APIs with their username and password, forcing them to use personal access tokens instead. Password access control requires the Premium plan or above.
See Manage personal access token permissions.
Reproducible order of installation for Maven and CRAN libraries
July 1-9, 2020: Version 3.23
Databricks now processes Maven and CRAN libraries in the order that they were installed on the cluster.
Take control of your users' personal access tokens with the Token Management API (Public Preview)
July 1-9, 2020: Version 3.23
Now Databricks administrators can use the Token Management API to manage their users' Databricks personal access tokens:
- Monitor and revoke users' personal access tokens.
- Control the lifetime of future tokens in your workspace.
- Control which users can create and use tokens.
See Monitor and revoke personal access tokens.
Customer-managed VPC deployments (Public Preview) can now use regional VPC endpoints
July 8, 2020: Version 3.23
If you are participating in the customer-managed VPC preview with secure cluster connectivity, you can now configure your VPC to use only regional VPC endpoints to AWS services for more direct, secure connections and reduced cost compared to AWS global endpoints. For details, see Regional endpoints.
Encrypt traffic between cluster worker nodes (Public Preview)
July 7, 2020
In Databricks, a user query or transformation is sent to your clusters over an encrypted channel. The data exchanged between cluster worker nodes, however, is not encrypted by default. If your environment requires that data be encrypted at all times, whether at rest or in transit, you can create an init script that configures your clusters to encrypt traffic between worker nodes, using AES 128-bit encryption over a TLS 1.2 connection. This inter-node encryption feature requires the Enterprise plan. Contact your Databricks account team for more information.
See Encrypt traffic between cluster worker nodes.
Table access control supported on all accounts with the Premium plan (Public Preview)
July 1-9, 2020: Version 3.23
Table access control (table ACLs), which lets you programmatically grant and revoke access to your data from Python and SQL, is now supported in Public Preview on all accounts with the Premium plan or above.
See Hive metastore table access control (legacy).
IAM credential passthrough supported on all accounts with the Premium plan (Public Preview)
July 1-9, 2020: Version 3.23
IAM credential passthrough, which allows you to authenticate automatically to S3 buckets from Databricks clusters using the identity that you use to log in to Databricks, is now supported in Public Preview on all accounts with the Premium plan or above.
See the original release note and Credential passthrough (legacy).
Restore cut notebook cells
July 1-9, 2020: Version 3.23
You can now restore notebook cells that have been cut either by using the (Z) keyboard shortcut or by selecting Edit > Undo Cut Cells. This functionality is analogous to that for undoing deleted cells.
Assign jobs CAN MANAGE permission to non-admin users
July 1-9, 2020: Version 3.23
You can now assign non-admin users and groups to the CAN MANAGE permission for jobs. This permission level allows users to manage all settings on the job, including assigning permissions, changing the owner, and changing the cluster configuration (for example, adding libraries and modifying the cluster specification). See Control access to a job.
Non-admin Databricks users can view and filter by username using the SCIM API
July 1-9, 2020: Version 3.23
Non-admin users can now view usernames and filter users by username using the SCIM /Users endpoint.
Link to view cluster specification when you view job run details
July 1-9, 2020: Version 3.23
Now when you view the details for a job run, you can click a link to the cluster configuration page to view the cluster specification. Previously, you would have to copy the job ID from the URL and go to the cluster list to search for it.