Create and verify a cluster for legacy HIPAA support
This article applies to the legacy HIPAA compliance features. For an overview of HIPAA compliance features on the E2 platform, instead see the article HIPAA.
If your workspace uses the legacy HIPAA support, use the following instructions to create and verify a cluster for HIPAA compliance features to process PHI data.
-
Create a cluster
Follow the instructions in Compute configuration reference. As part of the configuration step you must choose a Databricks runtime version.
warningDatabricks Runtime for Machine Learning includes high-performance distributed machine learning packages that use MPI (Message Passing Interface) and other low-level communication protocols. Because these protocols do not natively support encryption over the wire, these ML packages can potentially send unencrypted sensitive data across the network. These packages do not change data encryption over the wire if your workflow does not depend on them.
Messages sent across the network by these ML packages are typically either ML model parameters or summary statistics about training data. It is therefore not typically expected that sensitive data, such as protected health information, would be sent over the wire unencrypted. However, it is possible that certain configurations or uses of these packages (such as specific model designs) could result in messages being sent across the network that contain such information.
The following packages are affected:
- XGBoost
- Horovod, HorovodEstimator, and HorovodRunner
- Distributed TensorFlow
-
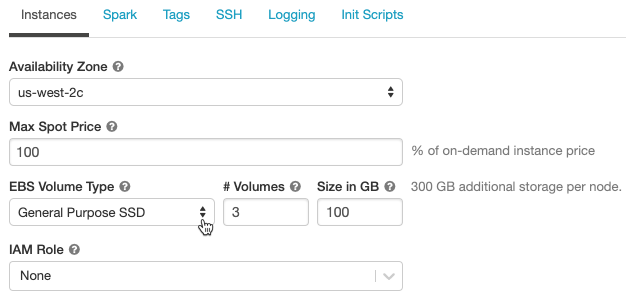
Configure the cluster with an EBS volume (Legacy HIPAA support)
Provision an EBS volume, as Databricks EBS volumes are encrypted while the default local storage is not.
-
Verify that encryption is enabled.
-
Create a notebook in the workspace and attach the notebook to the cluster that was created in the previous step.
-
Run the following command in the notebook:
Scala%scala spark.conf.get("spark.ssl.enabled")If the returned value is true, you have successfully created a cluster with encryption turned on. If not, contact help@databricks.com.
-
spark-submit is not supported on HIPAA-compliant clusters.