Parallelize Hyperopt hyperparameter tuning
The open-source version of Hyperopt is no longer being maintained.
Hyperopt is not included in Databricks Runtime for Machine Learning after 16.4 LTS ML. Databricks recommends using either Optuna for single-node optimization or RayTune for a similar experience to the deprecated Hyperopt distributed hyperparameter tuning functionality. Learn more about using RayTune on Databricks.
This example notebook shows how to scale single-machine hyperparameter tuning to a Databricks cluster using Hyperopt with SparkTrials. Tuning a scikit-learn SVM classifier on the Iris dataset, you first build a single-machine fmin() workflow, then parallelize it across Spark workers with MLflow automatically tracking every trial.
Import required packages and load dataset
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score
from sklearn.svm import SVC
from hyperopt import fmin, tpe, hp, SparkTrials, STATUS_OK, Trials
# If you are running Databricks Runtime for Machine Learning, `mlflow` is already installed and you can skip the following line.
import mlflow
# Load the iris dataset from scikit-learn
iris = iris = load_iris()
X = iris.data
y = iris.target
Part 1. Single-machine Hyperopt workflow
Here are the steps in a Hyperopt workflow:
- Define a function to minimize.
- Define a search space over hyperparameters.
- Select a search algorithm.
- Run the tuning algorithm with Hyperopt
fmin().
For more information, see the Hyperopt documentation.
Define a function to minimize
In this example, we use a support vector machine classifier. The objective is to find the best value for the regularization parameter C.
Most of the code for a Hyperopt workflow is in the objective function. This example uses the support vector classifier from scikit-learn.
If your cluster uses Databricks Runtime 11.3 ML, edit the support vector classifier to take a positional argument, clf = SVC(C).
def objective(C):
# Create a support vector classifier model
clf = SVC(C=C)
# Use the cross-validation accuracy to compare the models' performance
accuracy = cross_val_score(clf, X, y).mean()
# Hyperopt tries to minimize the objective function. A higher accuracy value means a better model, so you must return the negative accuracy.
return {'loss': -accuracy, 'status': STATUS_OK}
Define the search space over hyperparameters
See the Hyperopt docs for details on defining a search space and parameter expressions.
search_space = hp.lognormal('C', 0, 1.0)
Select a search algorithm
The two main choices are:
hyperopt.tpe.suggest: Tree of Parzen Estimators, a Bayesian approach which iteratively and adaptively selects new hyperparameter settings to explore based on past resultshyperopt.rand.suggest: Random search, a non-adaptive approach that samples over the search space
algo=tpe.suggest
Run the tuning algorithm with Hyperopt fmin()
Set max_evals to the maximum number of points in hyperparameter space to test, that is, the maximum number of models to fit and evaluate.
argmin = fmin(
fn=objective,
space=search_space,
algo=algo,
max_evals=16)
# Print the best value found for C
print("Best value found: ", argmin)
Part 2. Distributed tuning using Apache Spark and MLflow
To distribute tuning, add one more argument to fmin(): a Trials class called SparkTrials.
SparkTrials takes 2 optional arguments:
parallelism: Number of models to fit and evaluate concurrently. The default is the number of available Spark task slots.timeout: Maximum time (in seconds) thatfmin()can run. The default is no maximum time limit.
This example uses the very simple objective function defined in Cmd 7. In this case, the function runs quickly and the overhead of starting the Spark jobs dominates the calculation time, so the calculations for the distributed case take more time. For typical real-world problems, the objective function is more complex, and using SparkTrails to distribute the calculations is faster than single-machine tuning.
Automated MLflow tracking is enabled by default. To use it, call mlflow.start_run() before calling fmin() as shown in the example.
from hyperopt import SparkTrials
# To display the API documentation for the SparkTrials class, uncomment the following line.
# help(SparkTrials)
spark_trials = SparkTrials()
with mlflow.start_run():
argmin = fmin(
fn=objective,
space=search_space,
algo=algo,
max_evals=16,
trials=spark_trials)
# Print the best value found for C
print("Best value found: ", argmin)
To view the MLflow experiment associated with the notebook, click the Experiment icon in the notebook context bar on the upper right. There, you can view all runs. To view runs in the MLflow UI, click the icon at the far right next to Experiment Runs.
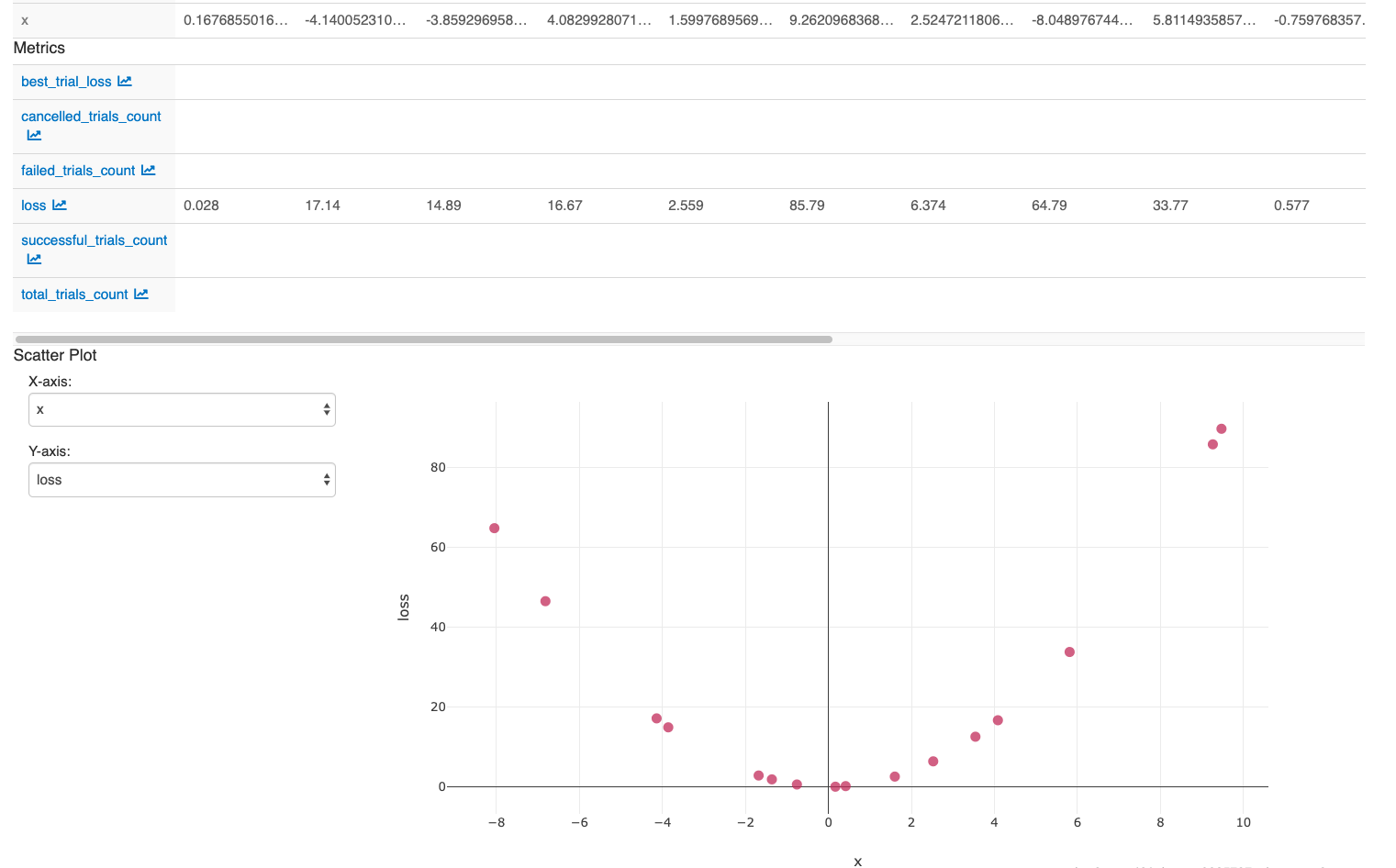
To examine the effect of tuning C:
- Select the resulting runs and click Compare.
- In the Scatter Plot, select C for X-axis and loss for Y-axis.
After you perform the actions in the last cell in the notebook, your MLflow UI should display: