Write queries and explore data in the new SQL editor
The Databricks UI includes a SQL editor that you can use to write queries, collaborate with colleagues, find available data, and create visualizations. This page introduces the new SQL editor and links to pages that cover each task in detail.
This page describes the new SQL editor. To learn about working with the legacy SQL editor, see Write queries and explore data in the legacy SQL editor.
Starting in late May 2026, the new SQL editor will be enabled by default for all workspaces. The ability to turn off the new SQL editor at the workspace level will no longer be available. Individual users will still be able to switch to the legacy editor during this period. Starting in late July 2026, the legacy SQL editor will be retired and all users will use the new SQL editor. See What's coming? for details.
Open the SQL editor
To open the SQL editor in the Databricks UI, click ![]() SQL Editor in the sidebar.
SQL Editor in the sidebar.
The SQL editor opens to your last open query. If no query exists, or all of your queries have been explicitly closed, the SQL editor landing page opens.
Turn on the new SQL editor
Use the New SQL editor toggle, to the right of the catalog and schema drop-down selectors, to turn the new editor on. On narrow displays, you can find the New SQL editor toggle by clicking the kebab menu ![]() to the right of the catalog and schema selectors.
to the right of the catalog and schema selectors.
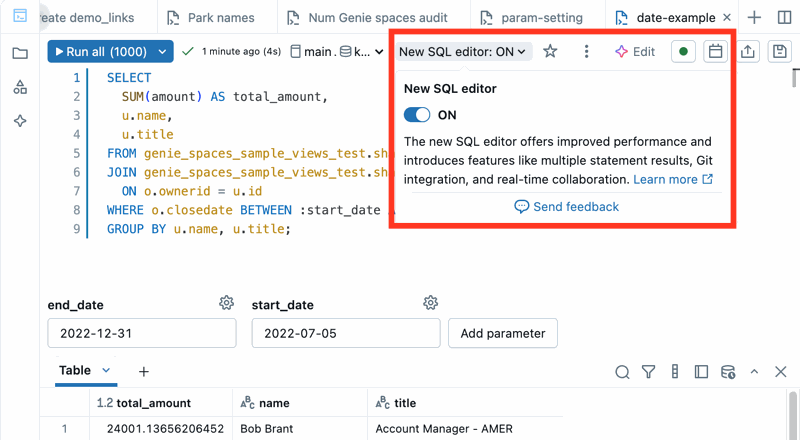
Enable the new editor for any query that you own:
- Click New SQL editor: OFF. A New SQL editor popover menu opens.
- The Apply to all of my queries checkbox is selected by default. Keep this setting to enable the editor for all queries that you own.
- To enable the new editor for the active query only, clear the Apply to all of my queries checkbox.
- Set the New SQL editor toggle to ON.
The new SQL editor cannot be used for all queries. You cannot switch to the new SQL editor for a query if any of the following are true:
- You do not own the query.
- The query contains Query-based Dropdown Lists, which are not supported. See Use named parameter markers.
When you turn on the new SQL editor, your query reopens in the new UI. The result set is empty until you run the query.
Query results are shared with all collaborators and are limited to 64,000 rows.
Orientation
This section highlights key differences in the UI and explains how to find and use available features.
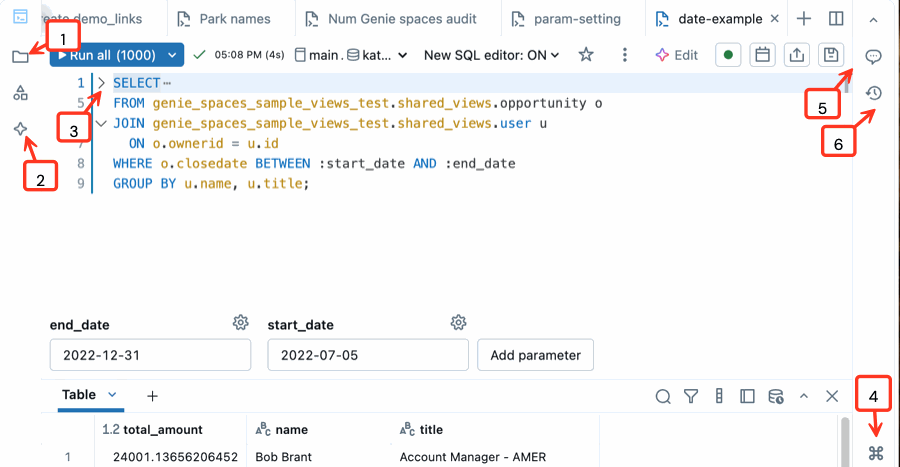
- Open the workspace file system: You can open and organize your workspace objects directly from the SQL editor.
- Use the integrated Genie Code: Chat with Genie Code to help you write, refine, or understand queries. Run code generated by Genie Code from the side pane.
- Collapse sections of code: Click the collapse arrow to the left of a code block to selectively hide and expand code sections. This can make working through large files easier.
- Open the command palette: The command palette includes common actions, keyboard shortcuts, custom themes, and links to help you quickly find what you need. After you open it, use the search bar to look for specific tools and shortcuts.
- Comment on code: Add comments to code to enhance collaboration.
- Review version history: Review recent changes to your query.
Work with the SQL editor
The following pages discuss the primary tasks you can perform in the new SQL editor:
-
- Write queries
- Connect to compute, browse data assets, and author queries.
-
- Run and share queries
- Run single or multi-statement queries, share them, and edit them together in real time.
-
- View query results
- Explore, visualize, download, and filter query results.
-
- Use parameters
- Use named parameters and configure parameter widgets.
-
- Custom format SQL
- Customize SQL auto-formatting options.
-
- Keyboard shortcuts
- Reference of common keyboard shortcuts.
Copy the legacy query ID
To get the legacy query ID for a query that you migrated to the new SQL editor, copy it from the File menu. The legacy query ID can be useful for API calls or other integrations that reference it.
- Open the query in the new SQL editor.
- Click the kebab menu
 at the top of the editor.
at the top of the editor. - Click File > Copy legacy query ID.
Disable the new SQL editor
Starting in late May 2026, the workspace-level opt-out for the new SQL editor will be removed. Individual users can still switch to the legacy editor until late July 2026, when the legacy SQL editor will be fully retired. See What's coming? for details.
To turn off the new SQL editor:
- Click New SQL editor: ON. A New SQL editor popover menu opens.
- Set the New SQL Editor toggle to OFF.
- In the confirmation dialog, select whether to turn off the new editor for the active query only or for all eligible queries.
- The Disable for all eligible queries is unselected. Keep this setting if you want to turn off the new editor for only the active query.
- To turn off the new SQL editor for all your queries, select the checkbox Disable for all eligible queries.
To prevent queries from automatically opening in the new SQL editor:
- In the Databricks workspace, click your username in the top bar and select Settings.
- In the left pane, under User, click the Developer tab.
- Turn off Create and open all eligible queries in the new SQL editor.
Workspace admins can turn off this feature at the workspace level by visiting the preview portal and searching for SQL editor. See Manage Databricks previews.