Introduction to workspace objects
This article provides a high-level introduction to Databricks workspace objects. You can create, view, and organize workspace objects in the workspace browser across personas.
Note about naming workspace assets
A workspace asset's full name consists of its base name and its file extension. For example, a notebook's file extension can be .py, .sql, .scala, .r, and .ipynb depending on the notebook's language and format.
When you create a notebook asset, its base name and its full name (the base name concatenated with the file extension) must be unique within any workspace folder. When you name an asset, Databricks checks to see if it meets this criteria by adding the file extension to it. If the full name matches an existing file in the folder, that name is not allowed and you must choose a new notebook name. For example, if you try to create a Python notebook (in Python source format) named test in the same folder as a Python file named test.py, it won't be allowed.
Clusters
Databricks clusters provide a unified platform for various use cases such as running production ETL pipelines, streaming analytics, ad-hoc analytics, and machine learning. A cluster is a type of Databricks compute resource. Other compute resource types include Databricks SQL warehouses.
For detailed information on managing and using clusters, see Compute.
Notebooks
A notebook is a web-based interface to documents containing a series of runnable cells (commands) that operate on files and tables, visualizations, and narrative text. Commands can be run in sequence, referring to the output of one or more previously run commands.
Notebooks are one mechanism for running code in Databricks. The other mechanism is jobs.
For detailed information on managing and using notebooks, see Databricks notebooks.
Jobs
Jobs are one mechanism for running code in Databricks. The other mechanism is notebooks.
For detailed information on managing and using jobs, see Lakeflow Jobs.
Libraries
A library makes third-party or locally-built code available to notebooks and jobs running on your clusters.
For detailed information on managing and using libraries, see Install libraries.
Data
You can import data into a distributed file system mounted into a Databricks workspace and work with it in Databricks notebooks and clusters. You can also use a wide variety of Apache Spark data sources to access data.
For detailed information on loading data, see Standard connectors in Lakeflow Connect.
Files
This feature is in Public Preview.
In Databricks Runtime 11.3 LTS and above, you can create and use arbitrary files in the Databricks workspace. Files can be any file type. Common file type examples include:
.pyfiles used in custom modules..mdfiles, such asREADME.md..csvor other small data files..txtfiles.- Log files.
For detailed information on using files, see Work with files on Databricks. For information about how to use files to modularize your code as you develop with Databricks notebooks, see Share code between Databricks notebooks
Git folders
Git folders are Databricks folders whose contents are co-versioned together by syncing them to a remote Git repository. Using Databricks Git folders, you can develop notebooks in Databricks and use a remote Git repository for collaboration and version control.
For detailed information on using repos, see Databricks Git folders.
Models
Model refers to a model registered in MLflow Model Registry. Model Registry is a centralized model store that enables you to manage the full lifecycle of MLflow models. It provides chronological model lineage, model versioning, stage transitions, and model and model version annotations and descriptions.
For detailed information on managing and using models, see Manage model lifecycle in Unity Catalog.
Experiments
An MLflow experiment is the primary unit of organization and access control for MLflow runs, including agent traces, LLM application evaluations, and ML model training runs. All MLflow runs belong to an experiment. Each experiment lets you visualize, search, and compare runs, and download and run artifacts or metadata for analysis in other tools.
For detailed information on managing and using experiments, see Organize training runs with MLflow experiments.
Queries
Queries are SQL statements that allow you to interact with your data. For more information, see Access and manage saved queries.
Dashboards
Dashboards are presentations of query visualizations and commentary. See Dashboards.
Alerts
Alerts are notifications that a field returned by a query has reached a threshold. For more information, see Databricks SQL alerts.
References to workspace objects
Historically, users were required to include the /Workspace path prefix for some Databricks APIs (%sh) but not for others (%run, REST API inputs).
Users can use workspace paths with the /Workspace prefix everywhere. Old references to paths without the /Workspace prefix are redirected and continue to work. We recommend that all workspace paths carry the /Workspace prefix to differentiate them from Volume and DBFS paths.
The prerequisite for consistent /Workspace path prefix behavior is this: There cannot be a /Workspace folder at the workspace root level. If you have a /Workspace folder on the root level and want to enable this UX improvement, delete or rename the /Workspace folder you created and contact your Databricks account team.
Share a file, folder, or notebook URL
In your Databricks workspace, URLs to workspace files, notebooks, and folders are in the formats:
Workspace file URLs
https://<databricks-instance>/?o=<16-digit-workspace-ID>#files/<16-digit-object-ID>
Notebook URLs
https://<databricks-instance>/?o=<16-digit-workspace-ID>#notebook/<16-digit-object-ID>/command/<16-digit-command-ID>
Folder (workspace and Git) URLs
https://<databricks-instance>/browse/folders/<16-digit-ID>?o=<16-digit-workspace-ID>
These links can break if any folder, file, or notebook in the current path is updated with a Git pull command, or is deleted and recreated with the same name. However, you can construct a link based on the workspace path to share with other Databricks users with appropriate access levels by changing it to a link in this format:
https://<databricks-instance>/?o=<16-digit-workspace-ID>#workspace/<full-workspace-path-to-file-or-folder>
Links to folders, notebooks, and files can be shared by replacing everything in the URL after ?o=<16-digit-workspace-ID> with the path to the file, folder, or notebook from the workspace root. If you are sharing a URL to a folder, remove /browse/folders/<16-digit-ID> from the original URL as well.
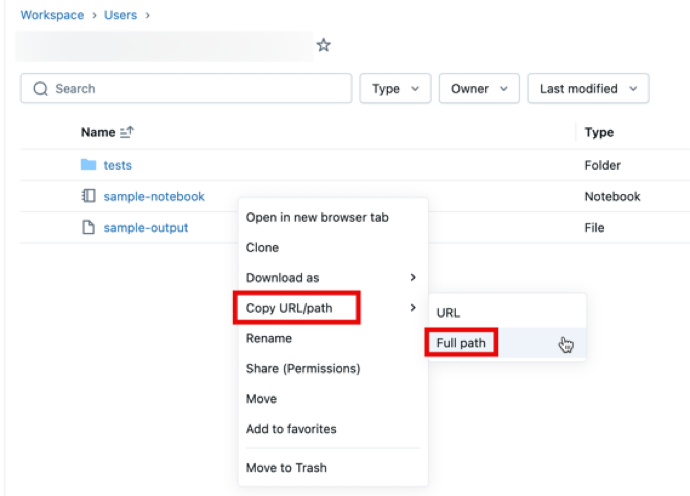
To get the file path, open the context menu by right-clicking on the folder, notebook, or file in your workspace that you want to share and select Copy URL/path > Full path. Prepend #workspace to the file path you just copied, and append the resulting string after the ?o=<16-digit-workspace-ID> so it matches the URL format above.
URL formulation example #1: Folder URLs
To share the workspace folder URL https://<databricks-instance>/browse/folders/1111111111111111?o=2222222222222222, remove the browse/folders/1111111111111111 substring from the URL. Add #workspace followed by the path to the folder or workspace object you want to share.
In this case, the workspace path is to a folder, /Workspace/Users/user@example.com/team-git/notebooks. After copying the full path from your workspace, you can now construct the shareable link:
https://<databricks-instance>/?o=2222222222222222#workspace/Workspace/Users/user@example.com/team-git/notebooks
URL formulation example 2: Notebook URLs
To share the notebook URL https://<databricks-instance>/?o=1111111111111111#notebook/2222222222222222/command/3333333333333333, remove #notebook/2222222222222222/command/3333333333333333. Add #workspace followed by the path to the folder or workspace object.
In this case, the workspace path points to a notebook, /Workspace/Users/user@example.com/team-git/notebooks/v1.0/test-notebook. After copying the full path from your workspace, you can now construct the shareable link:
https://<databricks-instance>/?o=1111111111111111#workspace/Workspace/Users/user@example.com/team-git/notebooks/v1.0/test-notebook
Now you have a stable URL for a file, folder, or notebook path to share! For more information about URLs and identifiers, see Get identifiers for workspace objects.