lotes vs. transmissão processamento de dados em Databricks
Este artigo descreve as key diferenças entre lotes e transmissão, duas semânticas de processamento de dados diferentes usadas para cargas de trabalho de engenharia de dados, incluindo ingestão, transformações e processamento de tempo real.
A transmissão é comumente associada ao processamento contínuo e de baixa latência de barramentos de mensagens, como o Apache Kafka.
No entanto, no Databricks, possui uma definição mais abrangente. O mecanismo subjacente do pipeline declarativo LakeFlow Spark (Apache Spark e transmissão estruturada) possui uma arquitetura unificada para processamento de lotes e transmissões:
- O mecanismo pode tratar fontes como armazenamento de objetos na nuvem e Delta Lake como fontes de transmissão para um processamento incremental eficiente.
- O processamento de transmissão pode ser executado tanto de forma acionada quanto contínua, oferecendo ao senhor a flexibilidade de controlar as compensações de custo e desempenho de suas cargas de trabalho de transmissão.
Abaixo estão as diferenças semânticas fundamentais que distinguem lotes e transmissão, incluindo suas vantagens e desvantagens, e considerações para escolhê-los para suas cargas de trabalho.
semântica de lotes
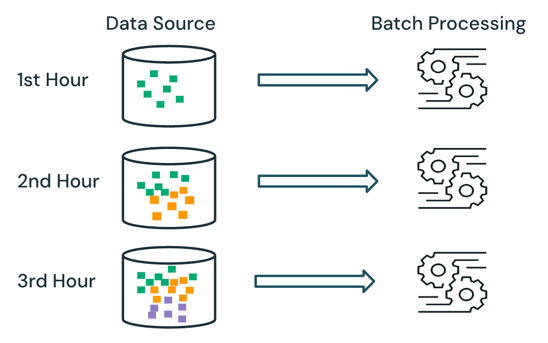
Com o processamento de lotes, o mecanismo não controla quais dados já estão sendo processados na fonte. Todos os dados atualmente disponíveis na fonte são processados no momento do processamento. Na prática, um lote fonte de dados é normalmente particionado logicamente, por exemplo, por dia ou região, para limitar o reprocessamento de dados.
Por exemplo, o cálculo do preço médio das vendas do item, agregado em uma granularidade horária, para um evento de vendas executado por uma empresa de comércio eletrônico pode ser programado como processamento de lotes para calcular o preço médio das vendas a cada hora. Com lotes, os dados de horas anteriores são reprocessados a cada hora e os resultados calculados anteriormente são substituídos para refletir os resultados mais recentes.
transmissão semântica
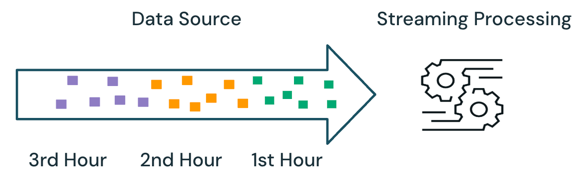
Com o processamento de transmissão, o mecanismo mantém o controle de quais dados estão sendo processados e só processa novos dados na execução subsequente. No exemplo acima, o senhor pode programar o processamento de transmissão em vez do processamento de lotes para calcular o preço médio das vendas a cada hora. Com a transmissão, somente os novos dados adicionados à fonte desde a última execução são processados. Os resultados recém-calculados devem ser anexados aos resultados calculados anteriormente para verificar os resultados completos.
lotes vs. transmissão
No exemplo acima, a transmissão é melhor do que o processamento de lotes porque não processa os mesmos dados processados na execução anterior. No entanto, o processamento da transmissão fica mais complexo com cenários como dados fora de ordem e de chegada tardia na fonte.
Um exemplo de dados de chegada tardia é se alguns dados de ventas da primeira hora não chegarem à fonte até a segunda hora:
- No processamento de lotes, os dados de chegada tardia da primeira hora serão processados com os dados da segunda hora e os dados existentes da primeira hora. Os resultados anteriores da primeira hora serão sobrescritos e corrigidos pelos dados de chegada tardia.
- No processamento de transmissão, os dados de chegada tardia da primeira hora serão processados sem nenhum dos outros dados da primeira hora que foram processados. A lógica de processamento deve armazenar as informações de soma e contagem dos cálculos médios da primeira hora para atualizar corretamente os resultados anteriores.
Essas complexidades de transmissão são normalmente introduzidas quando o processamento é de estado, como junções, agregações e deduplicações.
Para o processamento de transmissão sem estado, como anexar novos dados da fonte, o tratamento de dados fora de ordem e de chegada tardia é menos complexo, pois os dados de chegada tardia podem ser anexados aos resultados anteriores à medida que os dados chegam à fonte.
A tabela abaixo descreve os prós e contras do processamento de lotes e transmissão e os diferentes produtos recurso que suportam essas duas semânticas de processamento em Databricks LakeFlow.
Processamento semântico | Prós | Contras | Data engenharia produto |
|---|---|---|---|
Batch |
|
|
|
transmissão |
|
|
|
Recomendações
A tabela abaixo descreve a semântica de processamento recomendada com base nas características das cargas de trabalho de processamento de dados em cada camada da arquitetura do medalhão.
Camada de medalhão | Características da carga de trabalho | Recomendação |
|---|---|---|
Bronze |
|
|
Prata |
|
|
ouro |
|
|