Model deployment patterns
This article describes two common patterns for moving ML artifacts through staging and into production. The asynchronous nature of changes to models and code means that there are multiple possible patterns that an ML development process might follow.
Models are created by code, but the resulting model artifacts and the code that created them can operate asynchronously. That is, new model versions and code changes might not happen at the same time. For example, consider the following scenarios:
- To detect fraudulent transactions, you develop an ML pipeline that retrains a model weekly. The code may not change very often, but the model might be retrained every week to incorporate new data.
- You might create a large, deep neural network to classify documents. In this case, training the model is computationally expensive and time-consuming, and retraining the model is likely to happen infrequently. However, the code that deploys, serves, and monitors this model can be updated without retraining the model.
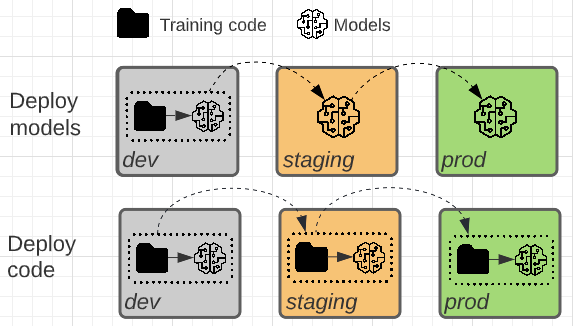
The two patterns differ in whether the model artifact or the training code that produces the model artifact is promoted towards production.
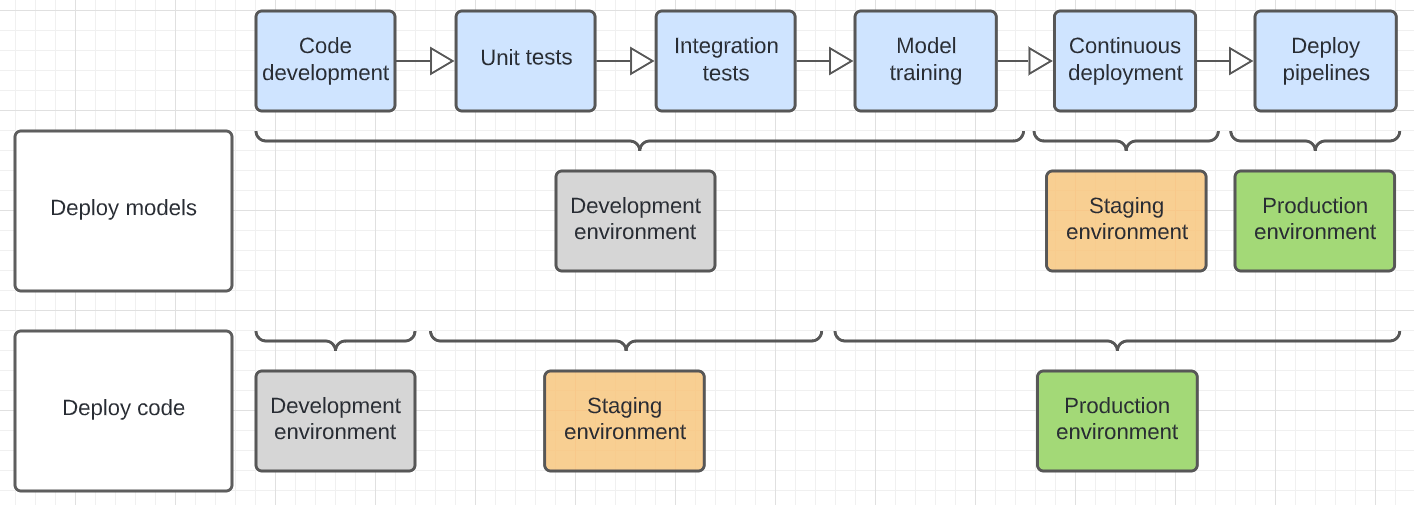
Deploy code (recommended)
In most situations, Databricks recommends the “deploy code” approach. This approach is incorporated into the recommended MLOps workflow.
In this pattern, the code to train models is developed in the development environment. The same code moves to staging and then production. The model is trained in each environment: initially in the development environment as part of model development, in staging (on a limited subset of data) as part of integration tests, and in the production environment (on the full production data) to produce the final model.
Advantages:
- In organizations where access to production data is restricted, this pattern allows the model to be trained on production data in the production environment.
- Automated model retraining is safer, since the training code is reviewed, tested, and approved for production.
- Supporting code follows the same pattern as model training code. Both go through integration tests in staging.
Disadvantages:
- The learning curve for data scientists to hand off code to collaborators can be steep. Predefined project templates and workflows are helpful.
Also in this pattern, data scientists must be able to review training results from the production environment, as they have the knowledge to identify and fix ML-specific issues.
If your situation requires that the model be trained in staging over the full production dataset, you can use a hybrid approach by deploying code to staging, training the model, and then deploying the model to production. This approach saves training costs in production but adds an extra operation cost in staging.
Deploy models
In this pattern, the model artifact is generated by training code in the development environment. The artifact is then tested in the staging environment before being deployed into production.
Consider this option when one or more of the following apply:
- Model training is very expensive or hard to reproduce.
- All work is done in a single Databricks workspace.
- You are not working with external repos or a CI/CD process.
Advantages:
- A simpler handoff for data scientists
- In cases where model training is expensive, only requires training the model once.
Disadvantages:
- If production data is not accessible from the development environment (which may be true for security reasons), this architecture may not be viable.
- Automated model retraining is tricky in this pattern. You could automate retraining in the development environment, but the team responsible for deploying the model in production might not accept the resulting model as production-ready.
- Supporting code, such as pipelines used for feature engineering, inference, and monitoring, needs to be deployed to production separately.
Typically an environment (development, staging, or production) corresponds to a catalog in Unity Catalog. For details on how to implement this pattern, see the upgrade guide.
The diagram below contrasts the code lifecycle for the above deployment patterns across the different execution environments.
The environment shown in the diagram is the final environment in which a step is run. For example, in the deploy models pattern, final unit and integration testing is performed in the development environment. In the deploy code pattern, unit tests and integration tests are run in the development environments, and final unit and integration testing is performed in the staging environment.