Padrões de implantação de modelos
Este artigo descreve dois padrões comuns para a movimentação de artefatos do site ML entre a fase de preparação e a produção. A natureza assíncrona das alterações nos modelos e no código significa que há vários padrões possíveis que um processo de desenvolvimento de ML pode seguir.
Os modelos são criados por código, mas os artefatos do modelo resultantes e o código que os criou podem operar de forma assíncrona. Ou seja, novas versões do modelo e mudanças de código podem não acontecer ao mesmo tempo. Por exemplo, considere os seguintes cenários:
- Para detectar transações fraudulentas, o senhor desenvolve um pipeline de ML que retreina um modelo semanalmente. O código pode não mudar com muita frequência, mas o modelo pode ser retreinado toda semana para incorporar novos dados.
- O senhor pode criar uma rede neural grande e profunda para classificar documentos. Nesse caso, o treinamento do modelo é computacionalmente caro e demorado, e é provável que o retreinamento do modelo ocorra com pouca frequência. No entanto, o código que implanta, atende e monitora esse modelo pode ser atualizado sem retreinar o modelo.
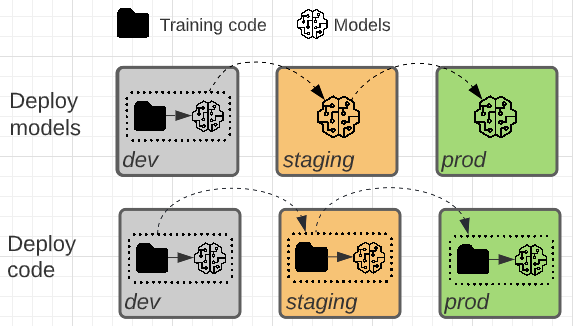
Os dois padrões diferem quanto ao fato de o artefato do modelo ou o código de treinamento que produz o artefato do modelo ser promovido para a produção.
código implantado (recomendado)
Na maioria das situações, o site Databricks recomenda a abordagem do "código implantado". Essa abordagem é incorporada ao fluxo de trabalho recomendado do MLOps.
Nesse padrão, o código para treinar modelos é desenvolvido no ambiente de desenvolvimento. O mesmo código passa para a preparação e depois para a produção. O modelo é treinado em cada ambiente: inicialmente no ambiente de desenvolvimento como parte do desenvolvimento do modelo, na preparação (em um subconjunto limitado de dados) como parte dos testes de integração e no ambiente de produção (nos dados completos da produção) para produzir o modelo final.
Vantagens:
- Em organizações em que o acesso aos dados de produção é restrito, esse padrão permite que o modelo seja treinado em dados de produção no ambiente de produção.
- O retreinamento automatizado de modelos é mais seguro, pois o código de treinamento é revisado, testado e aprovado para produção.
- O código de suporte segue o mesmo padrão do código de treinamento do modelo. Ambos passam por testes de integração na preparação.
Desvantagens:
- A curva de aprendizado para que o data scientists transfira o código para os colaboradores pode ser íngreme. O padrão de projeto e o fluxo de trabalho predefinidos são úteis.
Também nesse padrão, o data scientists deve ser capaz de analisar os resultados do treinamento no ambiente de produção, pois tem o conhecimento necessário para identificar e corrigir problemas específicos do ML.
Se a sua situação exigir que o modelo seja treinado na fase de preparação em toda a produção dataset, o senhor poderá usar uma abordagem híbrida implantando o código na fase de preparação, treinando o modelo e, em seguida, implantando o modelo na produção. Essa abordagem economiza custos de treinamento na produção, mas adiciona um custo extra de operações na preparação.
modelos implantados
Nesse padrão, o artefato do modelo é gerado pelo código de treinamento no ambiente de desenvolvimento. O artefato é então testado no ambiente de preparação antes de ser implantado na produção.
Considere essa opção quando uma ou mais das seguintes opções se aplicarem:
- O treinamento de modelos é muito caro ou difícil de reproduzir.
- Todo o trabalho é feito em um único Databricks workspace.
- O senhor não está trabalhando com repositórios externos ou com um processo de CI/CD.
Vantagens:
- Um handoff mais simples para data scientists
- Nos casos em que o treinamento do modelo é caro, é necessário treinar o modelo apenas uma vez.
Desvantagens:
- Se os dados de produção não estiverem acessíveis no ambiente de desenvolvimento (o que pode ser verdade por motivos de segurança), essa arquitetura pode não ser viável.
- O retreinamento automatizado de modelos é complicado nesse padrão. O senhor poderia automatizar o retreinamento no ambiente de desenvolvimento, mas a equipe responsável por implantar o modelo na produção poderia não aceitar o modelo resultante como pronto para a produção.
- O código de suporte, como o pipeline usado para engenharia de recursos, inferência e monitoramento, precisa ser implantado na produção separadamente.
Normalmente, um ambiente (desenvolvimento, preparação ou produção) corresponde a um catálogo no Unity Catalog. Para obter detalhes sobre como implementar esse padrão, consulte o guia de atualização.
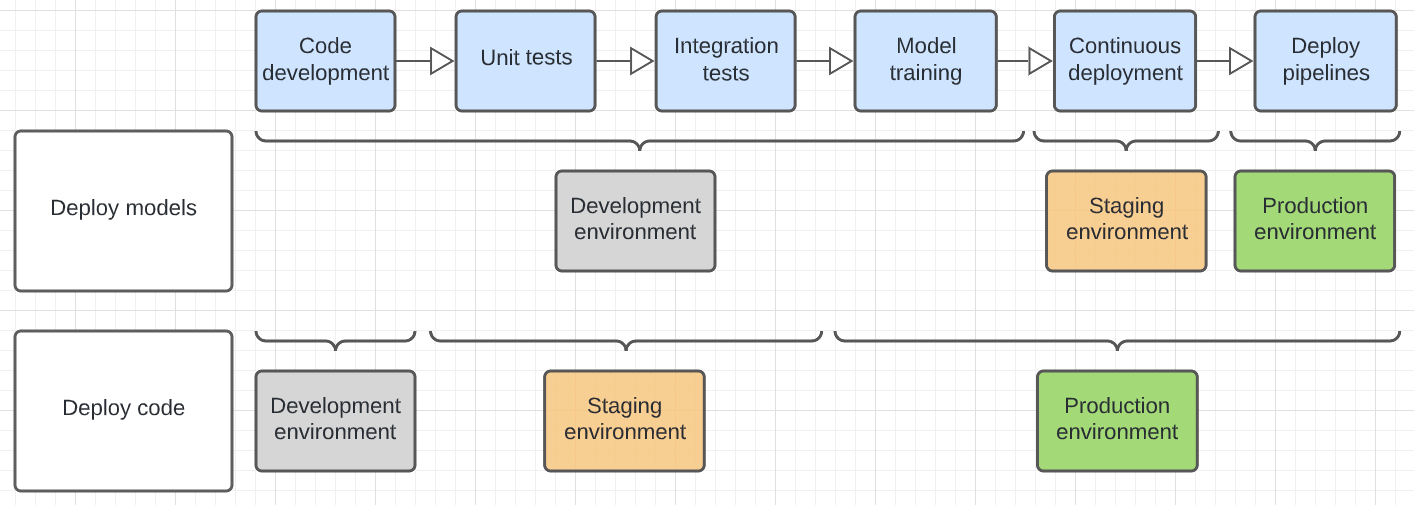
O diagrama abaixo compara o ciclo de vida do código para os padrões de implantação acima nos diferentes ambientes de execução.
O ambiente mostrado no diagrama é o ambiente final no qual uma passo é executada. Por exemplo, no padrão de modelos aprimorados, os testes finais de unidade e integração são realizados no ambiente de desenvolvimento. No padrão de código aprimorado, os testes de unidade e os testes de integração são executados nos ambientes de desenvolvimento, e os testes finais de unidade e integração são executados no ambiente de preparação.