Materialized views
Like standard views, materialized views are the results of a query and you access them the same way you would a table. Unlike standard views, which recompute results on every query, materialized views cache the results and refresh them on a specified interval. Because a materialized view is precomputed, queries against it can run much faster than against regular views.
For guidance on when to use materialized views versus streaming tables or views, see What are pipelines?.
A materialized view is a declarative pipeline object. It includes a query that defines it, a flow to update it, and the cached results for fast access. A materialized view:
- Tracks changes in upstream data.
- On trigger, incrementally processes the changed data and applies the necessary transformations.
- Maintains the output table, in sync with the source data, based on a specified refresh interval.
Materialized views are a good choice for many transformations:
- You apply reasoning over cached results instead of rows. In fact, you simply write a query.
- They are always correct at the time of their update. All required data is processed, even if it arrives late or out of order.
- They are often incremental. Databricks tries to choose the appropriate strategy that minimizes the cost of updating a materialized view.
How materialized views work
The following diagram illustrates how materialized views work.

Materialized views are defined and updated by a single pipeline. You can explicitly define materialized views in the source code of the pipeline. Tables defined by a pipeline can't be changed or updated by any other pipeline.
When you create a standalone materialized view, outside of Lakeflow Spark Declarative Pipelines, Databricks creates a pipeline that is used to update the view. You can see the pipeline by selecting Jobs & Pipelines from the left navigation in your workspace. You can add the Pipeline type column to your view. Materialized views defined in a pipeline have a type of ETL. Standalone materialized views have a type of MV/ST. See Use standalone materialized views.
Databricks uses Unity Catalog to store metadata about the view, including the query and additional system views for incremental updates. Databricks materializes the cached data in cloud storage. Databricks stores some backing data in the __databricks_internal catalog. See The __databricks_internal catalog.
Databricks creates internal tables to support materialized view incremental refresh. These tables appear in system.information_schema.tables but are not visible in Catalog Explorer or other workspace UI surfaces.
The following example joins two tables together and keeps the result up to date using a materialized view.
- Python
- SQL
from pyspark import pipelines as dp
@dp.materialized_view
def regional_sales():
partners_df = spark.read.table("partners")
sales_df = spark.read.table("sales")
return (
partners_df.join(sales_df, on="partner_id", how="inner")
)
CREATE OR REPLACE MATERIALIZED VIEW regional_sales
AS SELECT *
FROM partners
INNER JOIN sales ON
partners.partner_id = sales.partner_id;
Automatic incremental updates
When the pipeline defining a materialized view is triggered, the view is automatically kept up to date, often incrementally. Databricks attempts to process only the data that must be processed to keep the materialized view up to date. A materialized view always shows the correct result, even if it requires fully recomputing the query result from scratch, but often Databricks makes only incremental updates to a materialized view, which can be far less costly than a full recomputation.
The diagram below shows a materialized view called sales_report, which is the result of joining two upstream tables called clean_customers and clean_transactions, and grouping by country. An upstream process inserts 200 rows into clean_customers in three countries (USA, Netherlands, UK) and updates 5,000 rows in clean_transactions corresponding to these new customers. The sales_report materialized view is incrementally updated for only the countries that have new customers or corresponding transactions. In this example, three rows update instead of the entire sales report.
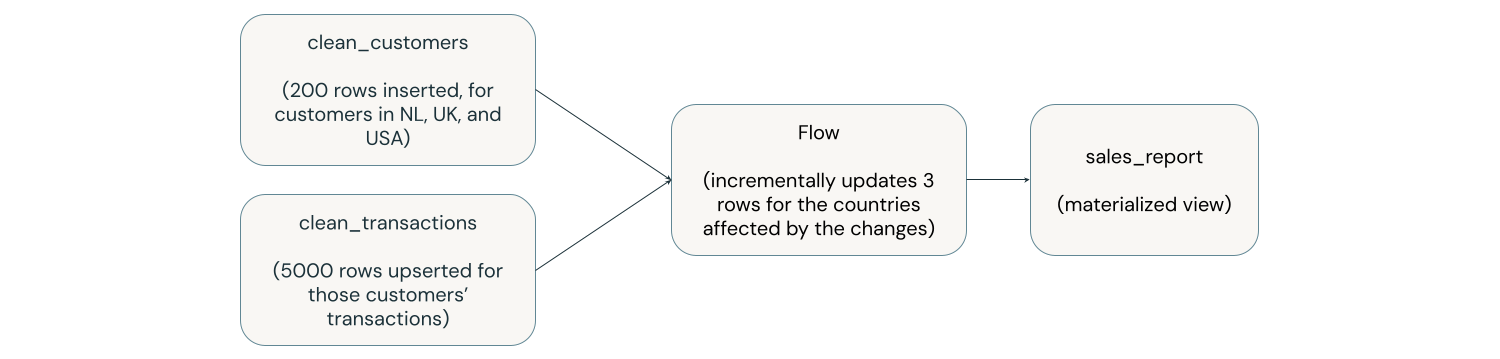
For more details about how incremental refresh works in materialized views, see Incremental refresh for materialized views.
Materialized view limitations
Materialized views have the following limitations:
- Since updates create correct queries, some changes to inputs will require a full recomputation of a materialized view, which can be expensive.
- They are not designed for low-latency use cases. The latency of updating a materialized view is in the seconds or minutes, not milliseconds.
- Not all computations can be incrementally computed.
- Databricks attempts to detect when a UDF used in a materialized view changes behavior and perform a full refresh to apply the updated UDF. However, UDFs that call other functions or libraries may change behavior in ways that Databricks does not recognize. One example of this is when a called library is upgraded. When the behavior of a UDF changes, it is your responsibility to perform a full refresh on any materialized view that uses it.
- Materialized views do not support
CLONE. You cannot use a materialized view as the source or target of a deep or shallow clone. For more information, see Limitations. - To view the pipeline that backs a materialized view, a non-admin user needs the
REFRESHprivilege on the materialized view in addition to permissions on the pipeline. See Who can view a pipeline and its output?.