Tracing LlamaIndex
LlamaIndex is an open-source framework for building agentic generative AI applications that allow large language models to work with your data in any format.
MLflow Tracing provides automatic tracing capability for LlamaIndex. You can enable tracing
for LlamaIndex by calling the mlflow.llama_index.autolog function, and nested traces are automatically logged to the active MLflow Experiment upon invocation of LlamaIndex engines and workflows.
import mlflow
mlflow.llama_index.autolog()
On serverless compute clusters, autologging is not automatically enabled. You must explicitly call mlflow.llama_index.autolog() to enable automatic tracing for this integration.
MLflow LlamaIndex integration is not only about tracing. MLflow offers full tracking experience for LlamaIndex, including model tracking, index management, and evaluation.
Prerequisites
To use MLflow Tracing with LlamaIndex, you need to install MLflow and the llama-index library.
- Development
- Production
For development environments, install the full MLflow package with Databricks extras and llama-index:
pip install --upgrade "mlflow[databricks]>=3.1" llama-index
The full mlflow[databricks] package includes all features for local development and experimentation on Databricks.
For production deployments, install mlflow-tracing and llama-index:
pip install --upgrade mlflow-tracing llama-index
The mlflow-tracing package is optimized for production use.
MLflow 3 is highly recommended for the best tracing experience with LlamaIndex.
Before running the examples, you'll need to configure your environment:
For users outside Databricks notebooks: Set your Databricks environment variables:
export DATABRICKS_HOST="https://your-workspace.cloud.databricks.com"
export DATABRICKS_TOKEN="your-personal-access-token"
For users inside Databricks notebooks: These credentials are automatically set for you.
API Keys: Ensure your LLM provider API keys are configured. For production environments, use AI Gateway or Databricks secrets instead of hardcoded values for secure API key management.
export OPENAI_API_KEY="your-openai-api-key"
# Add other provider keys as needed
Example Usage
First, let's download a test data to create a toy index:
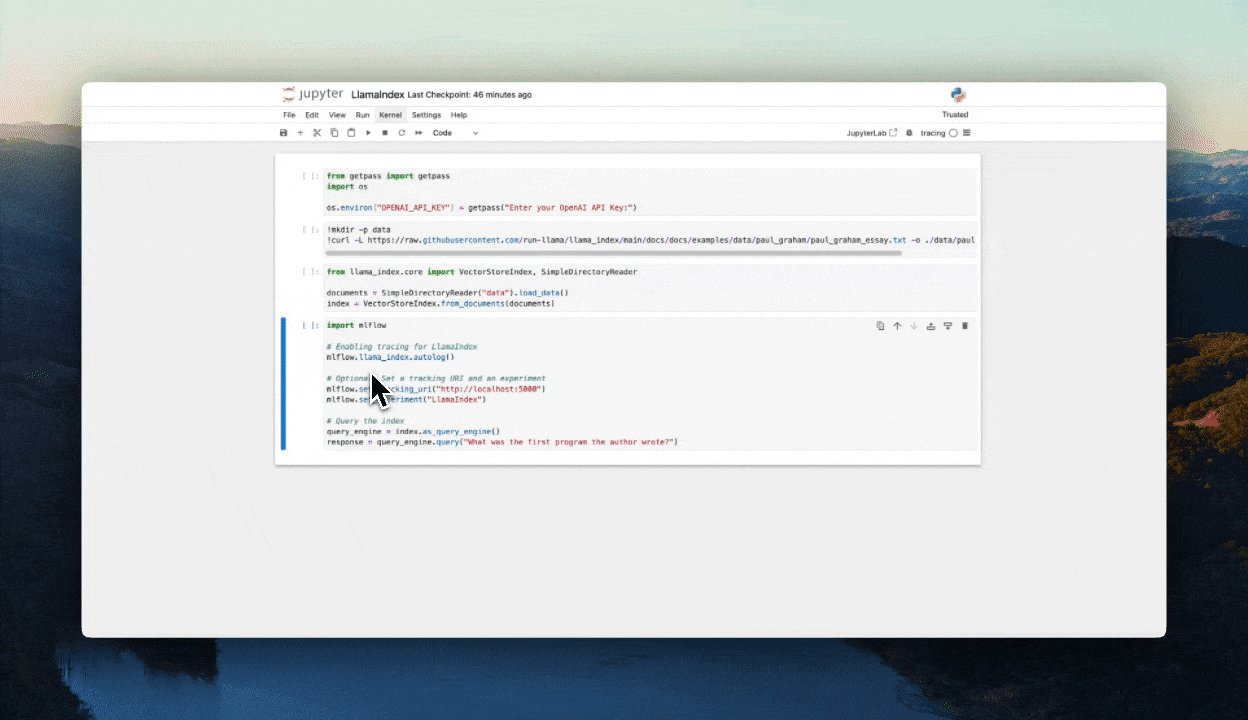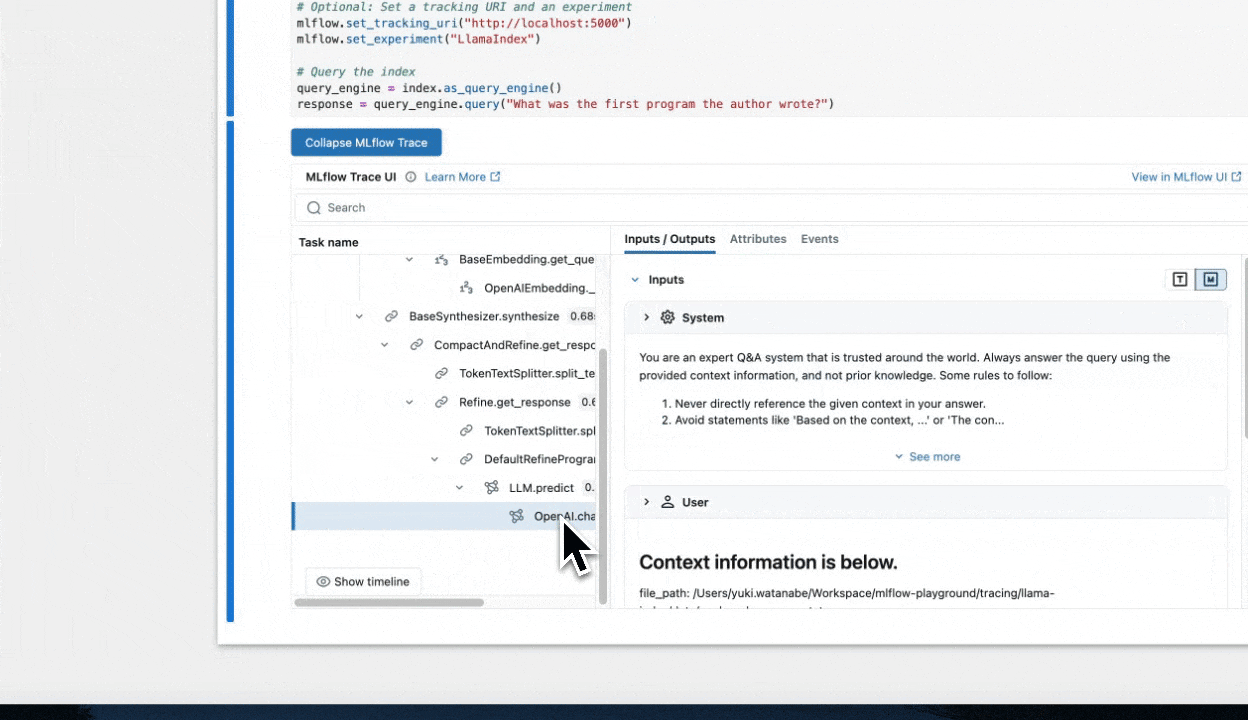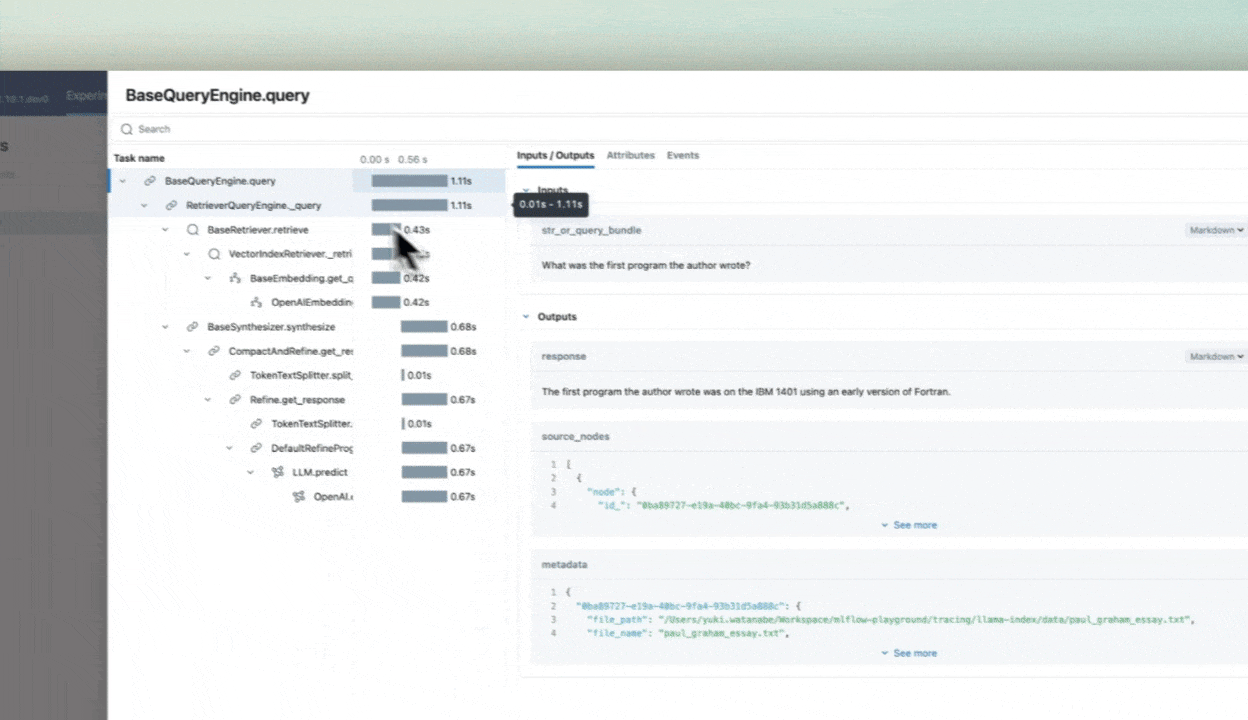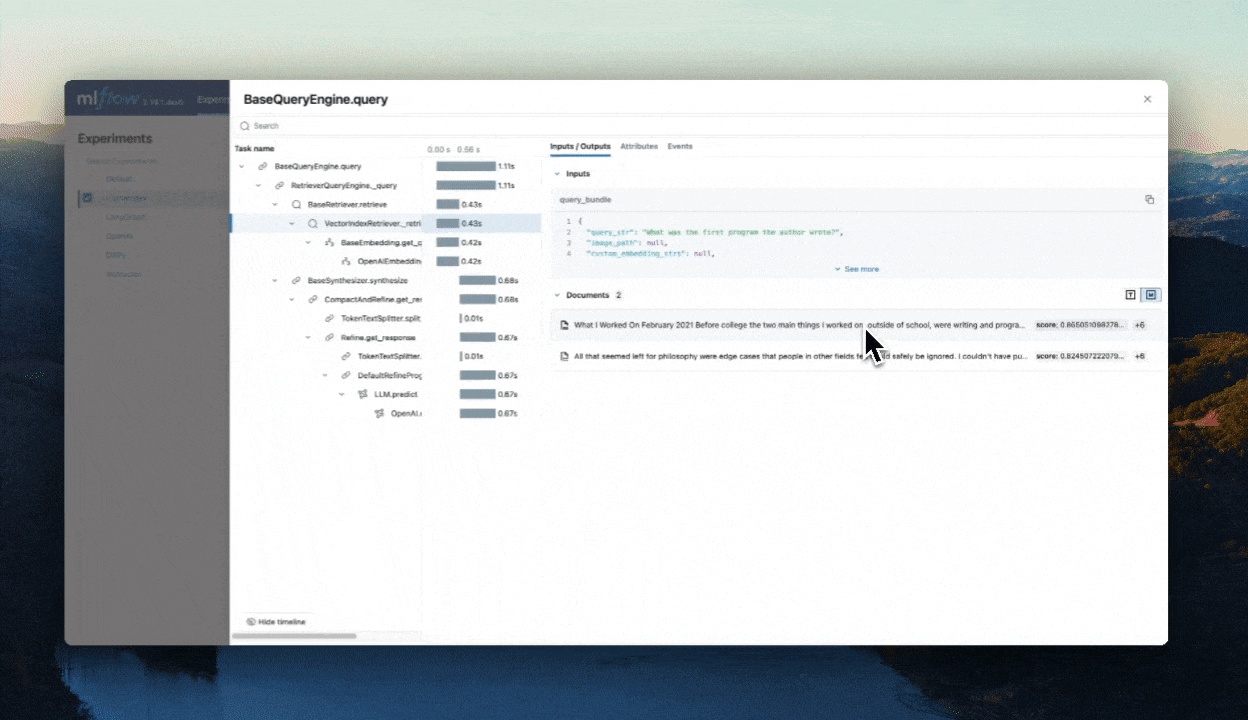
!mkdir -p data
!curl -L https://raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/paul_graham/paul_graham_essay.txt -o ./data/paul_graham_essay.txt
Load them into a simple in-memory vector index:
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
Now you can enable LlamaIndex auto tracing and start querying the index:
import mlflow
import os
# Ensure your OPENAI_API_KEY (or other LLM provider keys) is set in your environment
# os.environ["OPENAI_API_KEY"] = "your-openai-api-key" # Uncomment and set if not globally configured
# Enabling tracing for LlamaIndex
mlflow.llama_index.autolog()
# Set up MLflow tracking to Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/llamaindex-demo")
# Query the index
query_engine = index.as_query_engine()
response = query_engine.query("What was the first program the author wrote?")
For production environments, use AI Gateway or Databricks secrets instead of hardcoded values for secure API key management.
LlamaIndex workflow
The Workflow is LlamaIndex's next-generation GenAI orchestration framework. It is designed as a flexible and interpretable framework for building arbitrary LLM applications such as an agent, a RAG flow, a data extraction pipeline, etc. MLflow supports tracking, evaluating, and tracing the Workflow objects, which makes them more observable and maintainable.
Automatic tracing for LlamaIndex workflow works off-the-shelf by calling the same mlflow.llama_index.autolog().
Disable auto-tracing
Auto tracing for LlamaIndex can be disabled globally by calling mlflow.llama_index.autolog(disable=True) or mlflow.autolog(disable=True).