Configurar o armazenamento do AWS (legado)
Essa documentação foi descontinuada e pode não estar atualizada. O produto, serviço ou tecnologia mencionados neste conteúdo não são mais suportados. Para view a documentação atual do administrador, consulte gerenciar seu Databricks account .
Este artigo se aplica apenas aos titulares de account legado. Todas as novas contas Databricks e a maioria das contas existentes devem usar Create an S3 bucket for workspace deployment.
Databricks armazena seu ativo account-wide, como biblioteca, em um bucket Amazon Web serviço S3. Este artigo o orienta nas etapas de configuração do bucket para concluir a implementação do Databricks.
O senhor pode definir as configurações de armazenamento do AWS usando o console account somente quando configurar inicialmente o account. Para alterar as configurações posteriormente, entre em contato com help@databricks.com.
Etapa 1: Gerar política de bucket S3
Para configurar o armazenamento AWS para um legado account:
-
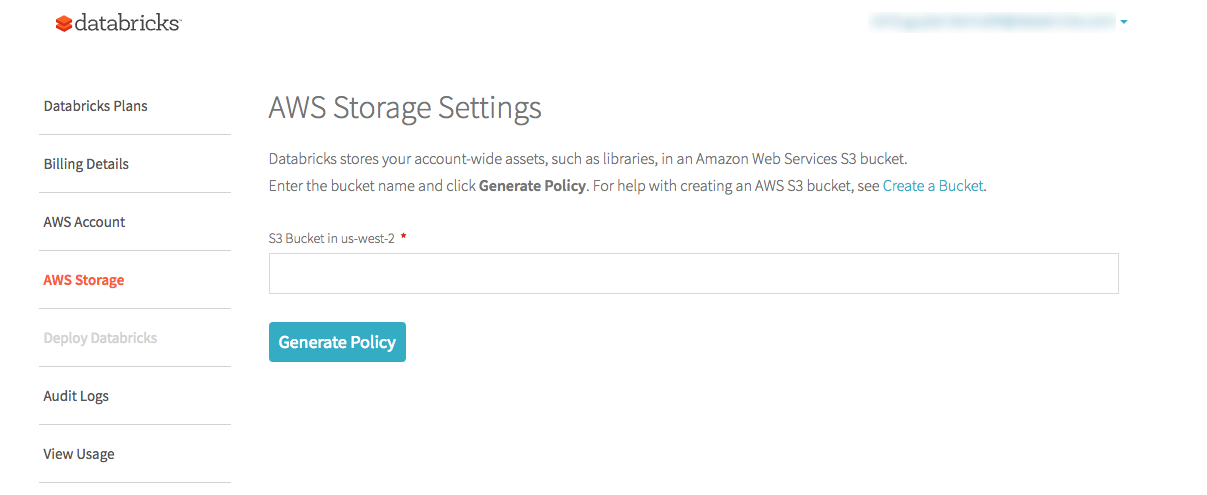
No console Databricks account , clique em AWS Storage tab.
-
No campo S3 bucket in <region> , digite o nome do seu bucket S3. Para obter ajuda com a criação de um bucket S3, consulte Criar um bucket na documentação do AWS.
-
O bucket S3 deve estar na mesma região que a implantação do Databricks.
-
A Databricks recomenda, como prática recomendada, que o senhor use um bucket S3 específico da Databricks.
-
Não reutilize um bucket do espaço de trabalho legado. Por exemplo, se o senhor estiver migrando para o E2, crie um novo bucket do AWS para sua configuração do E2.
-
Clique em Gerar política .
-
Copie a política gerada. Ele deve ter o seguinte formato, em que
414351767826é o ID Databricks account e<s3-bucket-name>é o bucket S3 que o senhor especificou na primeira tela:JSON{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Grant Databricks Access",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::414351767826:root"
},
"Action": [
"s3:GetObject",
"s3:GetObjectVersion",
"s3:PutObject",
"s3:DeleteObject",
"s3:ListBucket",
"s3:GetBucketLocation"
],
"Resource": ["arn:aws:s3:::<s3-bucket-name>/*", "arn:aws:s3:::<s3-bucket-name>"]
}
]
}
Etapa 2: Configurar o bucket S3
Para configurar o bucket S3, aplique a política de bucket gerada no console Databricks account e, opcionalmente, configure o registro em nível de objeto S3 (altamente recomendado).
- No Console da AWS, acesse o serviço S3.
- Clique no nome do bucket.
Aplique a política de bucket
-
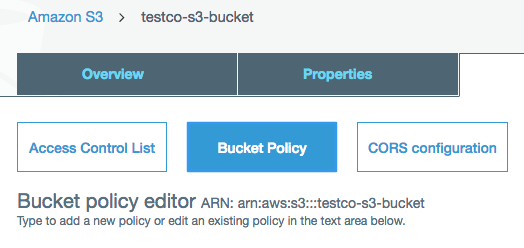
Clique na guia Permissões .
-
Clique no botão Política de bucket .
-
Cole a política que você copiou na Etapa 1 e clique em Salvar .
Ativar o registro em nível de objeto do S3 (recomendado)
O Databricks recomenda enfaticamente que você habilite o log em nível de objeto do S3 para seu bucket de armazenamento raiz. Isso permite uma investigação mais rápida de quaisquer problemas que possam surgir. Esteja ciente de que o registro em log em nível de objeto do S3 pode aumentar os custos de uso do AWS.
Para obter instruções, consulte a documentação da AWS sobre o log de eventos do CloudTrail para buckets e objetos S3.
Etapa 3: Aplique a alteração em seu site Databricks account
- No console Databricks account , vá para AWS Storage tab.
- Clique em Aplicar alteração .
Resolver falhas de validação
As permissões da política de bucket podem levar alguns minutos para serem propagadas. Você deve tentar novamente se a validação falhar devido às permissões.