Acesso ao S3 com passagem de credencial IAM com SCIM (legado)
Essa documentação foi descontinuada e pode não estar atualizada.
A passagem de credenciais está obsoleta a partir do Databricks Runtime 15.0 e será removida em versões futuras do Databricks Runtime. A Databricks recomenda que o senhor atualize para o Unity Catalog. Unity Catalog simplifica a segurança e a governança de seus dados, fornecendo um local central para administrar e auditar o acesso aos dados em vários espaços de trabalho em seu site account. Consulte O que é o Unity Catalog?
IAM O credential passthrough permite que o senhor se autentique automaticamente em S3 buckets do clustering Databricks usando a identidade que usa para log in para Databricks. Quando o senhor habilita a passagem de credenciais do IAM para o seu cluster, o comando que o senhor executa nesse cluster pode ler e gravar dados no S3 usando a sua identidade. IAM A passagem de credenciais tem dois key benefícios em relação à proteção do acesso a S3 buckets usando o perfil de instância:
- IAM A passagem de credenciais permite que vários usuários com diferentes políticas de acesso a dados compartilhem um clustering Databricks para acessar dados em S3, mantendo sempre a segurança dos dados. Um instance profile pode ser associado a apenas um IAM role. Isso exige que todos os usuários de um cluster Databricks compartilhem essa função e as políticas de acesso a dados dessa função.
- A passagem de credenciais do IAM associa um usuário a uma identidade. Isso, por sua vez, permite o registro de objetos S3 via CloudTrail. Todo o acesso ao S3 é vinculado diretamente ao usuário por meio do ARN nos logs do CloudTrail.
Requisitos
- Plano premium ouacima.
- Acesso de administrador do AWS a:
- IAM função e políticas no AWS account da implantação do Databricks.
- AWS account do balde S3.
- Databricks acesso de administrador para configurar o perfil da instância.
Configurar uma meta instance profile
Para usar a passagem de credenciais IAM, é necessário primeiro configurar pelo menos uma meta instance profile para assumir a função IAM que você atribui aos usuários.
Uma IAM role é uma identidade AWS com políticas que determinam o que a identidade pode ou não fazer em AWS. Um perfil de instância é um contêiner para um IAM role que o senhor pode usar para passar as informações da função para uma instância do EC2 quando a instância começar. permite que o senhor acesse os dados do Databricks clustering sem precisar incorporar sua chave AWS no Notebook.
Embora o perfil de instância simplifique muito a configuração de funções no cluster, um instance profile pode ser associado a apenas um IAM role. Isso exige que todos os usuários de um cluster Databricks compartilhem essa função e as políticas de acesso a dados dessa função. No entanto, a função IAM pode ser usada para assumir outra função IAM ou para acessar os dados diretamente. Usar as credenciais de uma função para assumir uma função diferente é chamado de função encadeamento.
IAM A passagem de credenciais permite que os administradores dividam o IAM role que o instance profile está usando e as funções que os usuários usam para acessar os dados. Em Databricks, chamamos a função de instância de meta IAM e a função de acesso a dados de data IAM role . Semelhante ao instance profile, um meta instance profile é um contêiner para um meta IAM role.
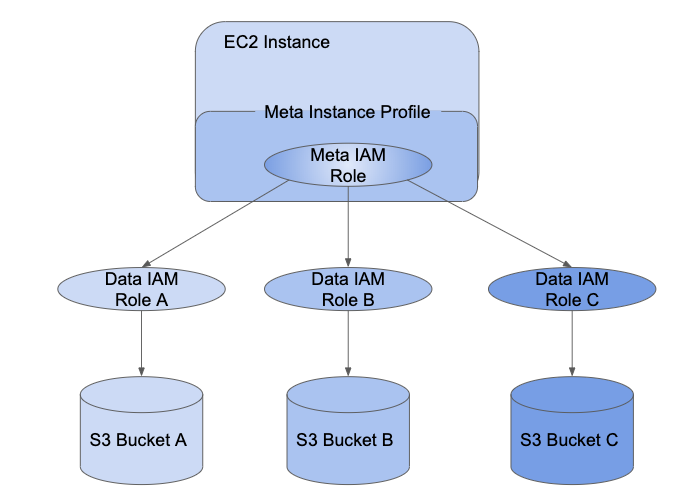
Os usuários recebem acesso aos dados da função IAM usando o SCIM API. Se o senhor estiver mapeando funções com seu provedor de identidade, essas funções serão sincronizadas com a API SCIM da Databricks. Ao usar um clustering com passagem de credenciais e um meta instance profile, o senhor pode assumir apenas a função de dados IAM que pode acessar. Isso permite que vários usuários com diferentes políticas de acesso a dados compartilhem um clustering Databricks e, ao mesmo tempo, mantenham os dados seguros.
Esta seção descreve como configurar o meta instance profile necessário para ativar a passagem de credenciais do IAM.
Etapa 1: Configurar funções para a passagem de credenciais do IAM
Nesta secção:
- Criar um dado IAM role
- Configurar um meta IAM role
- Configure os dados IAM role para confiar na meta IAM role
Criar um dado IAM role
Use um dado existente IAM role ou, opcionalmente, siga o tutorial: Configure o acesso S3 com um instance profile para criar um IAM role de dados que possa acessar S3 buckets.
Configurar um meta IAM role
Configure seu meta IAM role para assumir os dados IAM role.
-
No console da AWS, acesse o serviço IAM .
-
Clique na guia Funções na barra lateral.
-
Clique em Criar função .
- Em Selecionar tipo de entidade confiável , selecione Serviço da AWS .
- Clique no serviço EC2 .
-
Clique em Próximas permissões .
-
Clique em Criar política . Uma nova janela é aberta.
-
Clique no botão JSON tab.
-
Copie a política a seguir e defina
<account-id>como o ID da sua conta AWS e<data-iam-role>como o nome dos dados IAM role da seção anterior.JSON{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AssumeDataRoles",
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Resource": ["arn:aws:iam::<account-id>:role/<data-iam-role>"]
}
]
} -
Clique em Revisar política .
-
No campo Nome, digite um nome de política e clique em Criar política .
-
-
Retorne à janela da função e acesse refresh.
-
Pesquise o nome da política e marque a caixa de seleção ao lado do nome da política.
-
Clique em Próximas tags e em Próxima revisão .
-
No arquivo de nome da função, digite um nome para o meta IAM role.
-
Clique em Criar função .
-
No resumo da função, copie o perfil da instância ARN .
Configure os dados IAM role para confiar na meta IAM role
Para tornar a meta IAM role capaz de assumir os dados IAM role, o senhor torna a meta função confiável para a função de dados.
-
No console da AWS, acesse o serviço IAM .
-
Clique na guia Funções na barra lateral.
-
Encontre a função de dados criada na passo anterior e clique nela para ir para a página de detalhes da função.
-
Clique em Trust relationships (Relações de confiança ) tab e adicione a seguinte declaração, caso não esteja definida:
JSON{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::<account-id>:role/<meta-iam-role>"
},
"Action": "sts:AssumeRole"
}
]
}
Etapa 2: Configure um meta instance profile em Databricks
Esta seção descreve como configurar um meta instance profile em Databricks.
Nesta secção:
- Determine o site IAM role usado para a implantação do Databricks
- Modificar a política no site IAM role usado para a implantação do Databricks
- Adicione o meta instance profile ao Databricks
Determine o site IAM role usado para a implantação do Databricks
-
Acesse o console da conta.
-
Clique no ícone do espaço de trabalho .
-
Clique no nome do site workspace.
-
Observe o nome da função no final de ARN key na seção de credenciais; na imagem abaixo, é
testco-role.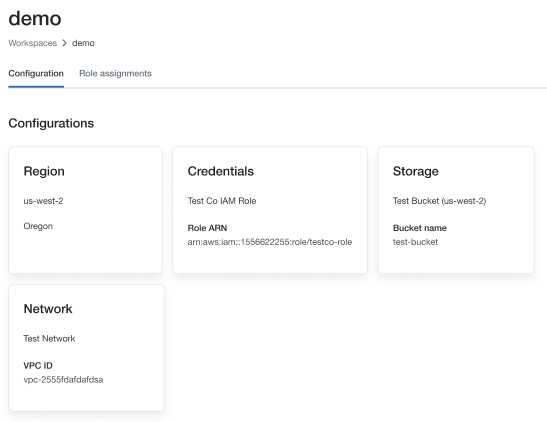
Modificar a política no site IAM role usado para a implantação do Databricks
- No console da AWS, acesse o serviço IAM .
- Clique na guia Funções na barra lateral.
- Edite a função que você anotou na seção anterior.
- Clique na política anexada à função.
- Modifique a política para permitir que as instâncias de EC2 para o clustering de Spark em Databricks usem o meta instance profile que o senhor criou em Configurar um meta IAM role. Para obter um exemplo, consulte Etapa 5: Adicionar o endereço S3 IAM role à política EC2.
- Clique em Revisar política e Salvar alterações .
Adicione o meta instance profile ao Databricks
-
Vá para a página de configurações.
-
Selecione o perfil da instância tab.
-
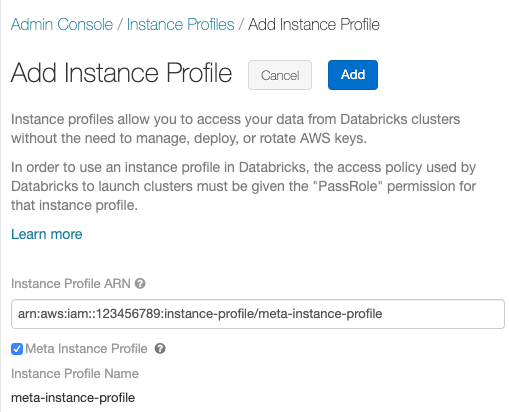
Clique no botão Add instance profile (Adicionar perfil de instância ). Uma caixa de diálogo é exibida.
-
Cole o perfil da instância ARN para a meta IAM role de Configure a meta IAM role.
-
Marque a caixa de seleção Meta instance profile e clique em Add .
-
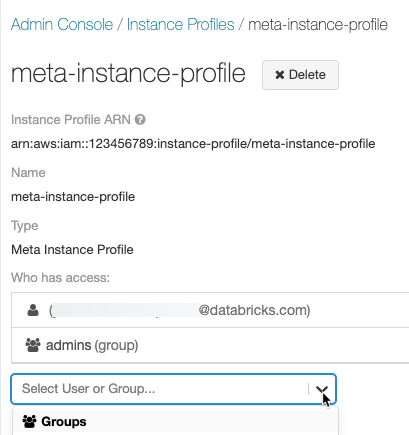
Opcionalmente, identifique os usuários que podem iniciar o clustering com o meta instance profile.
Etapa 3: Anexe as permissões do IAM role aos usuários do Databricks
Há duas maneiras de manter o mapeamento de usuários para a função IAM:
- No Databricks, usando a API SCIM Users ou a API SCIM Groups.
- Dentro do seu provedor de identidade. Isso permite que o senhor centralize o acesso aos dados e passe esses direitos diretamente para o clustering Databricks por meio da federação de identidade SAML 2.0.
Use o gráfico a seguir para ajudá-lo a decidir qual método de mapeamento é melhor para o seu workspace:
Requisito | SCIM | Provedor de identidade |
|---|---|---|
Login único na Databricks | Não | Sim |
Configurar o provedor de identidade do AWS | Não | Sim |
Configurar meta instance profile | Sim | Sim |
Databricks workspace administrador | Sim | Sim |
Administrador da AWS | Sim | Sim |
Administrador do provedor de identidade | Não | Sim |
Quando o senhor começa um clustering com um meta instance profile, o clustering passa pela sua identidade e assume apenas a função de dados IAM que o senhor pode acessar. Um administrador deve conceder permissões aos usuários na função IAM de dados usando os SCIM API métodos para definir permissões em funções.
Se o senhor estiver mapeando funções dentro do IdP, essas funções substituirão quaisquer funções mapeadas no SCIM e não deverá mapear usuários para funções diretamente. Consulte a Etapa 6: opcionalmente, configure o Databricks para sincronizar os mapeamentos de função do SAML para o SCIM.
O senhor também pode anexar um instance profile a um usuário ou grupo com Databricks Terraform provider e databricks_user_role ou databricks_group_instance_profile.
Iniciar um clustering de passagem de credenciais IAM
O processo para iniciar um clustering com passagem de credenciais difere de acordo com o modo de clustering.
Habilitar a passagem de credenciais para um cluster de alta simultaneidade
O cluster de alta simultaneidade pode ser compartilhado por vários usuários. Eles suportam apenas Python e SQL com passagem.
-
Quando o senhor criar um cluster, defina o cluster Mode como alta simultaneidade.
-
Escolha um Databricks Runtime versão 6.1 ouacima.
-
Em Advanced Options (Opções avançadas ), selecione Enable credential passthrough (Ativar passagem de credenciais) para acesso a dados em nível de usuário e permita apenas Python e SQL comando .

-
Clique em Instâncias tab. No menu suspenso do perfil da instância , escolha o meta instance profile que o senhor criou em Add the meta instance profile to Databricks.
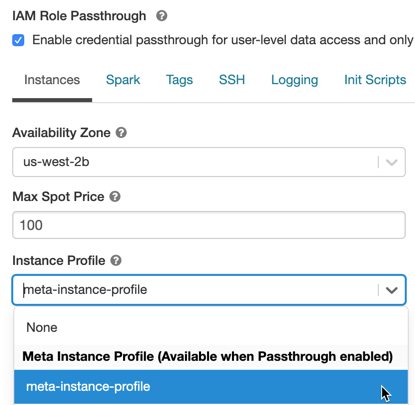
Habilitar a passagem de credenciais do IAM para um clustering Standard
clusters padrão com passagem de credencial são suportados e limitados a um único usuário. Os clusters padrão oferecem suporte a Python, SQL, Scala e R. No Databricks Runtime 10.4 LTSe acima, o sparklyr também é compatível.
O senhor deve atribuir um usuário na criação do cluster, mas o cluster pode ser editado por um usuário com permissões CAN MANAGE a qualquer momento para substituir o usuário original.
O usuário atribuído ao clustering deve ter pelo menos a permissão CAN ATTACH TO para o clustering a fim de executar o comando no clustering. Os administradores do espaço de trabalho e o criador do clustering têm permissões CAN MANAGE, mas não podem executar comando no clustering, a menos que sejam o usuário designado do clustering.
-
Quando o senhor criar um cluster, defina o cluster Mode como Standard.
-
Escolha um Databricks Runtime versão 6.1 ouacima.
-
Em Opções avançadas , selecione Habilitar passagem de credenciais para acesso a dados em nível de usuário .
-
Selecione o nome de usuário no menu suspenso Acesso de usuário único .
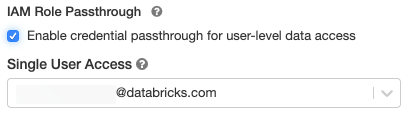
-
Clique em Instâncias tab. No menu suspenso do perfil da instância , selecione o meta instance profile que o senhor criou em Add the meta instance profile to Databricks.
Acessar o S3 usando a passagem de credenciais do IAM
O senhor pode acessar o S3 usando a passagem de credenciais assumindo uma função e acessando o S3 diretamente ou usando a função para montar o bucket do S3 e acessar os dados por meio da montagem.
Leitura e gravação S3 uso de dados credential passthrough
Ler e gravar dados de/para o S3:
- Python
- R
dbutils.credentials.assumeRole("arn:aws:iam::xxxxxxxx:role/<data-iam-role>")
spark.read.format("csv").load("s3a://prod-foobar/sampledata.csv")
spark.range(1000).write.mode("overwrite").save("s3a://prod-foobar/sampledata.parquet")
dbutils.credentials.assumeRole("arn:aws:iam::xxxxxxxx:role/<data-iam-role>")
# SparkR
library(SparkR)
sparkR.session()
read.df("s3a://prod-foobar/sampledata.csv", source = "csv")
write.df(as.DataFrame(data.frame(1:1000)), path="s3a://prod-foobar/sampledata.parquet", source = "parquet", mode = "overwrite")
# sparklyr
library(sparklyr)
sc <- spark_connect(method = "databricks")
sc %>% spark_read_csv("s3a://prod-foobar/sampledata.csv")
sc %>% sdf_len(1000) %>% spark_write_parquet("s3a://prod-foobar/sampledata.parquet", mode = "overwrite")
Use dbutils com uma função:
- Python
- R
dbutils.credentials.assumeRole("arn:aws:iam::xxxxxxxx:role/<data-iam-role>")
dbutils.fs.ls("s3a://bucketA/")
dbutils.credentials.assumeRole("arn:aws:iam::xxxxxxxx:role/<data-iam-role>")
dbutils.fs.ls("s3a://bucketA/")
Para outros métodos do site dbutils.credentials, consulte Utilidades de credenciais (dbutils.credentials).
Montar um bucket S3 no DBFS usando a passagem de credenciais do IAM
Para cenários mais avançados em que diferentes buckets ou prefixos exigem funções diferentes, é mais conveniente usar as montagens de bucket do Databricks para especificar a função a ser usada ao acessar um caminho de bucket específico.
Quando o senhor monta um cluster habilitado com IAM credential passthrough, qualquer leitura ou gravação no ponto de montagem usa suas credenciais para se autenticar no ponto de montagem. Este ponto de montagem será visíveis para outros usuários, mas os únicos usuários que terão acesso de leitura e gravação são aqueles que:
- Ter acesso ao armazenamento subjacente S3 account por meio de funções de dados IAM
- O senhor está usando um clustering habilitado para a passagem de credenciais IAM
dbutils.fs.mount(
"s3a://<s3-bucket>/data/confidential",
"/mnt/confidential-data",
extra_configs = {
"fs.s3a.credentialsType": "Custom",
"fs.s3a.credentialsType.customClass": "com.databricks.backend.daemon.driver.aws.AwsCredentialContextTokenProvider",
"fs.s3a.stsAssumeRole.arn": "arn:aws:iam::xxxxxxxx:role/<confidential-data-role>"
})
Acesse os dados do S3 em um Job usando a passagem de credenciais do IAM
Para acessar S3 uso de dados credential passthrough em um trabalho, configure o clustering de acordo com Iniciar um clustering IAM credential passthrough quando o senhor selecionar um clustering novo ou existente.
O agrupamento assumirá apenas as funções que o proprietário do trabalho tem permissão para assumir e, portanto, poderá acessar apenas os dados S3 que a função tem permissão para acessar.
Acessar dados do S3 a partir de um cliente JDBC ou ODBC usando a passagem de credenciais IAM
Para acessar S3 uso de dados IAM credential passthrough usando um cliente JDBC ou ODBC, configure o clustering de acordo com Iniciar um clustering IAM credential passthrough e conectar-se a esse clustering em seu cliente. O clustering assumirá apenas as funções que o usuário que se conectar a ele tiver permissão para acessar e, portanto, só poderá acessar os dados do S3 que o usuário tiver permissão para acessar.
Para especificar uma função em sua consulta SQL, faça o seguinte:
SET spark.databricks.credentials.assumed.role=arn:aws:iam::XXXX:role/<data-iam-role>;
-- Access the bucket which <my-role> has permission to access
SELECT count(*) from csv.`s3://my-bucket/test.csv`;
Limitações conhecidas
Os seguintes recursos não são compatíveis com a passagem de credenciais do site IAM:
-
%fs(em vez disso, use o comando dbutils.fs equivalente). -
Os seguintes métodos nos objetos SparkContext (
sc) e SparkSession (spark):- Métodos obsoletos.
- Métodos como
addFile()eaddJar()que permitiriam que usuários não administradores chamassem o código Scala. - Qualquer método que acesse um sistema de arquivos que não seja o S3.
- APIs antigas do Hadoop (
hadoopFile()ehadoopRDD()). - transmissão APIs, uma vez que as credenciais passadas expirariam enquanto a transmissão ainda estivesse em andamento.
-
DBFS As montagens (
/dbfs) estão disponíveis somente em Databricks Runtime 7.3 LTS e acima. Os pontos de montagem com passagem de credencial configurada não são suportados por esse caminho. -
Biblioteca em todo o cluster que requer permissão de um cluster instance profile para download. Somente as bibliotecas com caminhos DBFS são compatíveis.
-
Databricks Connect O clustering de alta simultaneidade está disponível somente em Databricks Runtime 7.3 LTS e acima.