Conectar-se ao Google Cloud Storage
Este artigo descreve um padrão herdado para acessar o Google Cloud Storage (GCS) de um workspace do Databricks hospedado na AWS que ignora a governança do Unity Catalog. Use-o somente se a governança do Unity Catalog não for exigida para os dados neste bucket.
Para ler ou gravar em um bucket GCS, o senhor deve criar um serviço anexado account e deve associar o bucket ao serviço account. O senhor se conecta ao bucket diretamente com um key que gera para o serviço account.
Acesse um bucket GCS diretamente com um serviço do Google Cloud account key
Para ler e gravar diretamente em um bucket, o senhor configura um key definido em sua configuraçãoSpark.
Etapa 1: Configure o serviço do Google Cloud account usando o Google Cloud Console
O senhor deve criar um serviço account para o clustering Databricks. Databricks recomenda dar a esse serviço account o mínimo de privilégios necessários para realizar sua tarefa.
-
Clique em IAM e Admin no painel de navegação esquerdo.
-
Clique em conta de serviço .
-
Clique em + CREATE serviço account .
-
Digite o nome e a descrição do serviço account.
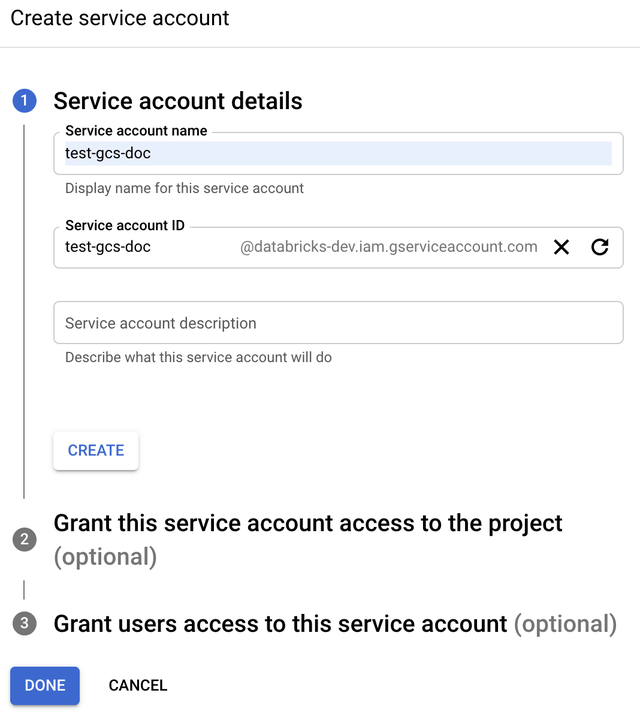
-
Clique em Criar .
-
Clique em "Continuar" .
-
Clique em Concluído .
Etapa 2: Crie um key para acessar diretamente o bucket GCS
O JSON key que o senhor gera para o serviço account é um key privado que só deve ser compartilhado com usuários autorizados, pois controla o acesso ao conjunto de dados e ao recurso no seu Google Cloud account.
- No console do Google Cloud, na lista de contas de serviço, clique na conta recém-criada account.
- Na seção de chaves , clique em ADD key > Create new key .
- Aceite o JSON key tipo.
- Clique em CRIAR . O arquivo key é baixado para o seu computador.
Etapa 3: Configurar o bucket do GCS
Crie um bucket
Se você ainda não tiver um bucket, crie um:
-
Clique em Armazenamento no painel de navegação esquerdo.
-
Clique em Criar bucket .
-
Clique em Criar .
Configurar o bucket
-
Configure os detalhes do bucket.
-
Clique na guia Permissões .
-
Ao lado do rótulo Permissions (Permissões ), clique em ADD (Adicionar ).
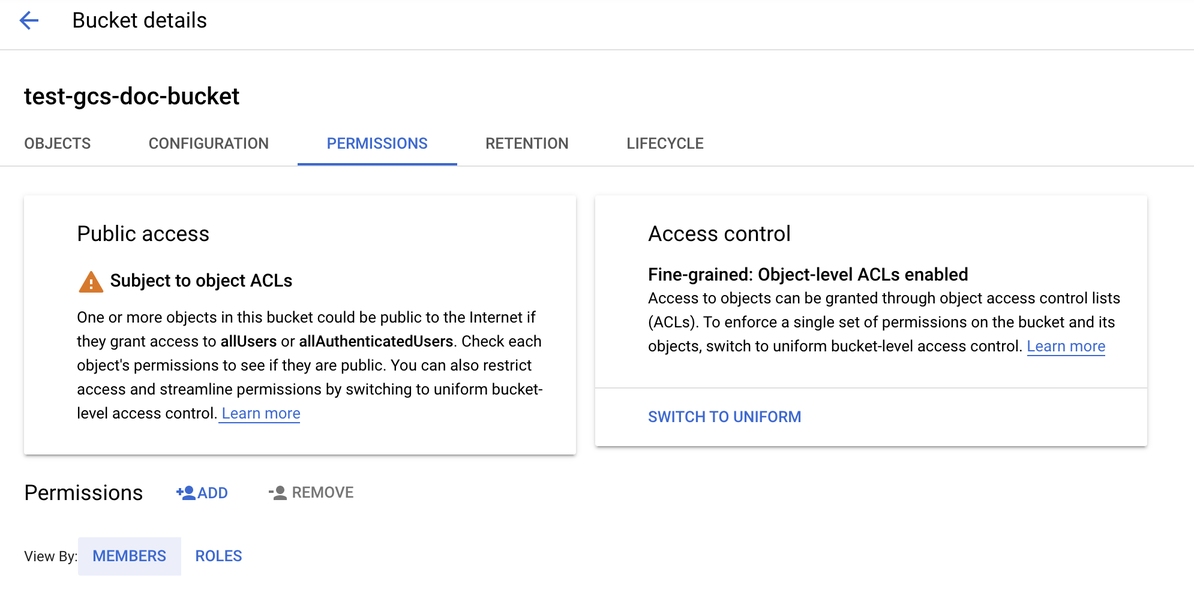
-
Forneça a permissão de administrador de armazenamento para o serviço account no bucket das funções do Cloud Storage.
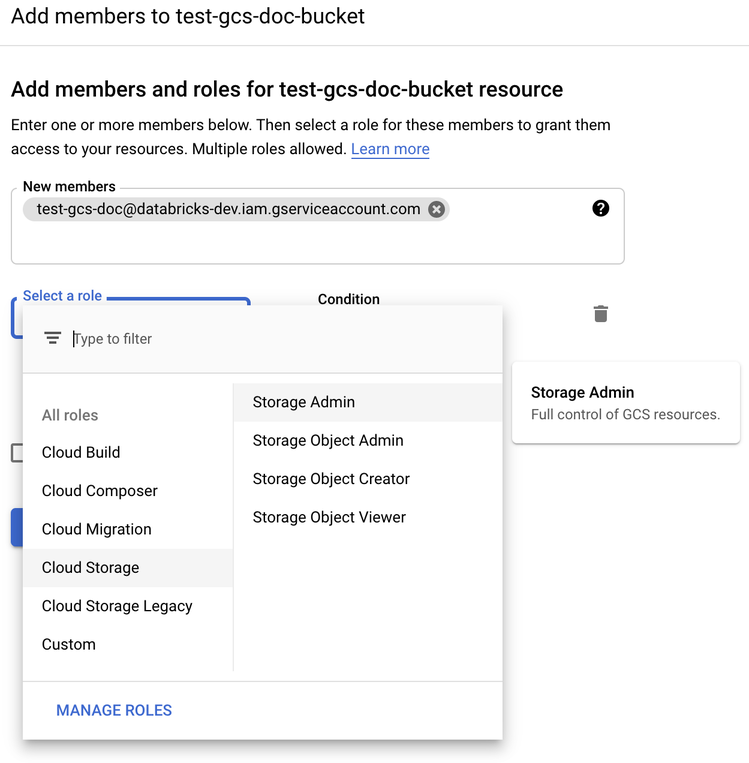
-
Clique em SALVAR .
Etapa 4: Coloque o serviço account key em Databricks secrets
Databricks recomenda o uso do Secret Scope para armazenar todas as credenciais. O senhor pode colocar o key privado e o key ID privado do seu arquivo key JSON em Databricks Secret Scope. O senhor pode conceder a usuários, entidades de serviço e grupos em seu workspace acesso para ler o Secret Scope. Isso protege o serviço account key e, ao mesmo tempo, permite que os usuários acessem GCS. Para criar um escopo secreto, consulte gerenciar segredos.
Etapa 5: Configurar um clustering Databricks
No endereçoSpark Config tab, defina uma configuração global ou uma configuração por bucket. Os exemplos a seguir definem a chave usando valores armazenados como segredos de Databricks.
Use o controle de acesso ao clustering e o controle de acesso ao Notebook juntos para proteger o acesso ao serviço account e aos dados no bucket GCS. Consulte Permissões de computação e Colaborar usando o Databricks Notebook.
Configuração global
Use essa configuração se as credenciais fornecidas precisarem ser usadas para acessar todos os buckets.
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client-email>
spark.hadoop.fs.gs.project.id <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key {{secrets/scope/gsa_private_key}}
spark.hadoop.fs.gs.auth.service.account.private.key.id {{secrets/scope/gsa_private_key_id}}
Substitua <client-email>, <project-id> pelos valores desses nomes de campo exatos do arquivo key JSON .
Configuração por bucket
Use essa configuração se precisar configurar credenciais para buckets específicos. A sintaxe da configuração por bucket acrescenta o nome do bucket ao final de cada configuração, como no exemplo a seguir.
As configurações por bucket podem ser usadas além das configurações globais. Quando especificadas, as configurações por bucket substituem as configurações globais.
spark.hadoop.google.cloud.auth.service.account.enable.<bucket-name> true
spark.hadoop.fs.gs.auth.service.account.email.<bucket-name> <client-email>
spark.hadoop.fs.gs.project.id.<bucket-name> <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key.<bucket-name> {{secrets/scope/gsa_private_key}}
spark.hadoop.fs.gs.auth.service.account.private.key.id.<bucket-name> {{secrets/scope/gsa_private_key_id}}
Substitua <client-email>, <project-id> pelos valores desses nomes de campo exatos do arquivo key JSON .
Etapa 6: Ler do GCS
Para ler o bucket do GCS, use um comando de leitura do Spark em qualquer formato compatível, por exemplo:
df = spark.read.format("parquet").load("gs://<bucket-name>/<path>")
Para gravar no bucket do GCS, use um comando de gravação do Spark em qualquer formato compatível, por exemplo:
df.write.mode("<mode>").save("gs://<bucket-name>/<path>")
Substitua <bucket-name> pelo nome do bucket que o senhor criou na Etapa 3: Configurar o bucket do GCS.