Crie um pipeline de dados não estruturados para RAG
Este artigo descreve como criar um pipeline de dados não estruturados para aplicações de AI generativa. Pipelines não estruturados são particularmente úteis para aplicações de Geração Aumentada de Recuperação (RAG).
Aprenda a converter conteúdo não estruturado, como arquivos de texto e PDFs, em um índice vetorial que agentes de AI ou outros recuperadores podem consultar. Você também aprenderá a experimentar e ajustar seu pipeline para otimizar a divisão em blocos, a indexação e a análise de dados, permitindo que você solucione problemas e experimente o pipeline para alcançar melhores resultados.
Notebook de pipeline de dados não estruturados
O notebook a seguir demonstra como implementar as informações neste artigo para criar um pipeline de dados não estruturados.
Pipeline de dados não estruturados do Databricks
Key componentes do pipeline de dados
A base de qualquer aplicativo RAG com dados não estruturados é a pipeline de dados. Este pipeline é responsável por organizar e preparar os dados não estruturados em um formato que o aplicativo RAG possa usar de forma eficaz.

Embora este pipeline de dados possa se tornar complexo dependendo do caso de uso, os seguintes são os key componentes que você precisa considerar ao construir pela primeira vez seu aplicativo RAG:
-
Composição e ingestão de corpus: Selecione as fontes de dados corretas e o conteúdo com base no caso de uso específico.
-
Pré-processamento de dados: transforme dados brutos em um formato limpo e consistente, adequado para embedding e recuperação.
- Análise: extraia informações relevantes do uso de dados usando técnicas de análise apropriadas.
- Enriquecimento: enriquecer dados com metadados adicionais e remover ruído.
- Extração de metadados: Extraia metadados úteis para implementar uma recuperação de dados mais rápida e eficiente.
- Deduplicação: Analise os documentos para identificar e eliminar documentos duplicados ou quase-duplicados.
- Filtragem: eliminar documentos irrelevantes ou indesejados da coleção.
-
Fragmentação: Divida os dados analisados em trechos menores e gerenciáveis para uma recuperação eficiente.
-
Incorporação: Converter os dados de texto em partes em uma representação vetorial numérica que captura seu significado semântico.
-
Indexação e armazenamento: criar índices vetoriais eficientes para um desempenho de pesquisa otimizado.
Composição e ingestão de corpus
Seu aplicativo RAG não consegue recuperar as informações necessárias para responder a uma consulta de usuário sem o corpus de dados correto. Os dados corretos dependem inteiramente dos requisitos e objetivos específicos do seu aplicativo, tornando crucial dedicar tempo para entender as nuances dos dados disponíveis. Para obter mais informações, consulte Ciclo de vida de desenvolvimento de agentes.
Por exemplo, ao criar um bot de suporte ao cliente, pode-se considerar incluir o seguinte:
- Documentos da base de conhecimento
- Perguntas Frequentes (FAQs)
- Manuais e especificações do produto
- Guias de solução de problemas
Envolva especialistas no domínio e partes interessadas desde o início de qualquer projeto para ajudar a identificar e organizar conteúdo relevante que possa melhorar a qualidade e a cobertura do seu corpus de dados. Podem fornecer percepções sobre os tipos de consultas que os usuários provavelmente enviarão e ajudar a priorizar as informações mais críticas a serem incluídas.
A Databricks recomenda que você faça a ingestão de dados de forma escalável e incremental. A Databricks oferece vários métodos para ingestão de dados, incluindo conectores totalmente gerenciados para aplicativos SaaS e integrações de API. Como prática recomendada, dados brutos de origem devem ser ingeridos e armazenados em uma tabela de destino. Essa abordagem garante a preservação dos dados, rastreabilidade e auditoria. Consulte Conectores padrão no Lakeflow Connect.
Pré-processamento de dados
Após a ingestão dos dados, é essencial limpar e formatar os dados brutos em um formato consistente adequado para incorporação e recuperação.
Análise
Após identificar as fontes de dados apropriadas para seu aplicativo recuperador, o próximo passo é extrair as informações necessárias dos dados brutos. Este processo, conhecido como análise, envolve a transformação dos dados não estruturados em um formato que o aplicativo RAG pode usar de forma eficaz.
As técnicas e ferramentas de análise específicas que você usa dependem do tipo de dados com que você está trabalhando. Por exemplo:
- Documentos de texto (PDFs, documentos do Word): Bibliotecas prontas para uso, como unstructured e PyPDF2, podem lidar com vários formatos de arquivo e fornecer opções para personalizar o processo de análise.
- Documentos HTML: bibliotecas de análise de HTML como BeautifulSoup e lxml podem ser usadas para extrair conteúdo relevante de páginas web. Essas bibliotecas podem ajudar a navegar pela estrutura HTML, selecionar elementos específicos e extrair o texto ou os atributos desejados.
- Imagens e documentos digitalizados: Técnicas de Reconhecimento Óptico de Caracteres (OCR) são geralmente necessárias para extrair texto de imagens. Bibliotecas OCR populares incluem bibliotecas de código aberto, como Tesseract, ou versões SaaS como Amazon Textract, Azure AI Vision OCR e Google Cloud Vision API.
Melhores práticas para analisar dados
A análise garante que os dados estejam limpos, estruturados e prontos para geração de embeddings e pesquisa de AI. Ao analisar seus dados, considere as seguintes práticas recomendadas:
- Limpeza de dados: pré-processe o texto extraído para remover informações irrelevantes ou ruidosas, como cabeçalhos, rodapés ou caracteres especiais. Reduza a quantidade de informação desnecessária ou malformada que sua cadeia RAG precisa processar.
- Tratamento de erros e exceções: implemente mecanismos de tratamento de erros e de log para identificar e resolver quaisquer problemas encontrados durante o processo de análise. Isso ajuda a identificar e resolver problemas rapidamente. Geralmente, isso aponta para problemas upstream com a qualidade dos dados de origem.
- Personalizando a lógica de análise: Dependendo da estrutura e formato dos seus dados, pode ser necessário personalizar a lógica de análise para extrair as informações mais relevantes. Embora possa exigir um esforço adicional inicial, invista tempo para fazer isso, se necessário, pois frequentemente evita muitos problemas de qualidade a jusante.
- Avaliação da qualidade da análise: Avalie regularmente a qualidade dos dados analisados revisando manualmente uma amostra da saída. Isso pode ajudar a identificar quaisquer problemas ou áreas de melhoria no processo de análise.
Enriquecimento
Enriquecer dados com metadados adicionais e remover ruído. Embora o enriquecimento seja opcional, ele pode melhorar drasticamente o desempenho geral do seu aplicativo.
Extração de metadados
Gerar e extrair metadados que capturam informações essenciais sobre o conteúdo, contexto e estrutura do documento pode melhorar significativamente a qualidade e o desempenho da recuperação de uma aplicação RAG. Os metadados fornecem sinais adicionais que melhoram a relevância, permitem filtragem avançada e suportam requisitos de busca específicos do domínio.
Embora bibliotecas como LangChain e LlamaIndex forneçam parsers integrados capazes de extrair automaticamente metadados padrão associados, muitas vezes é útil complementar isso com metadados personalizados adaptados ao seu caso de uso específico. Essa abordagem garante que informações críticas específicas do domínio sejam capturadas, melhorando a recuperação e a geração downstream. Você também pode usar grandes modelos de linguagem (LLMs) para automatizar o aprimoramento de metadados.
Os tipos de metadados incluem:
- Metadados em nível de documento: Nome do arquivo, URLs, informações do autor, carimbos de data/hora de criação e modificação, coordenadas GPS e versionamento de documentos.
- Metadados baseados em conteúdo: palavras-chave, resumos, tópicos, entidades nomeadas e tags específicas do domínio extraídos (nomes de produtos e categorias como PII ou HIPAA).
- Metadados estruturais: Cabeçalhos de seção, índice, números de página e limites de conteúdo semântico (capítulos ou subseções).
- Metadados contextuais: Sistema de origem, data de ingestão, nível de sensibilidade de dados, idioma original ou instruções transnacionais.
Armazenar metadados junto com documentos fragmentados ou suas incorporações correspondentes é essencial para o desempenho ideal. Também ajudará a refinar as informações recuperadas e a melhorar a precisão e a escalabilidade de seu aplicativo. Além disso, integrar metadados em pipeline de pesquisa híbrida, o que significa combinar pesquisa de similaridade vetorial com filtragem baseada em palavras-chave, pode aprimorar a relevância, especialmente em grandes dataset ou cenários de critérios de pesquisa específicos.
Desduplicação
Dependendo das suas fontes, você pode acabar com documentos duplicados ou documentos quase duplicados. Por exemplo, se você obtiver de uma ou mais unidades compartilhadas, várias cópias do mesmo documento poderiam existir em vários locais. Algumas dessas cópias podem ter modificações sutis. Da mesma forma, sua base de conhecimento pode ter cópias da documentação do seu produto ou rascunhos de postagens no blog. Se essas duplicatas permanecerem no seu corpus, você pode acabar com partes altamente redundantes no seu índice final, o que pode diminuir o desempenho do seu aplicativo.
Você pode eliminar algumas duplicatas usando apenas metadados. Por exemplo, se um item tiver o mesmo título e data de criação, mas várias entradas de diferentes fontes ou locais, você poderá filtrar com base nos metadados.
No entanto, isso pode não ser suficiente. Para ajudar a identificar e eliminar duplicatas com base no conteúdo dos documentos, é possível usar uma técnica conhecida como hashing sensível à localidade. Especificamente, uma técnica chamada MinHash funciona bem aqui, e uma implementação do Spark já está disponível no Spark ML. Funciona criando um hash para o documento com base nas palavras que ele contém e, em seguida, pode identificar com eficiência duplicatas ou quase duplicatas unindo-se a esses hashes. Em um nível bem alto, este é um processo de quatro etapas:
- Crie um vetor de recursos para cada documento. Se necessário, considere aplicar técnicas como remoção de stopwords, radicagem e lematização para melhorar os resultados e, em seguida, tokenizar em n-grams.
- Ajuste um modelo MinHash e aplique hash aos vetores usando MinHash para distância de Jaccard.
- Faça a execução de um join de similaridade usando esses hashes para produzir um conjunto de resultados para cada documento duplicado ou quase duplicado.
- Filtre as duplicatas que você não deseja manter.
Um o passo de dedupicação de linha de base pode selecionar os documentos a serem mantidos arbitrariamente (como o primeiro nos resultados de cada duplicata ou uma escolha aleatória entre as duplicatas). Uma melhoria potencial seria selecionar a "melhor" versão da duplicata usando outra lógica (como a mais recentemente atualizada, status de publicação ou fonte mais autoritativa). Além disso, observe que pode ser necessário experimentar o passo de extração de recursos e o número de tabelas hash usadas no modelo MinHash para melhorar os resultados da correspondência.
Para obter mais informações, consulte a documentação do Spark para hashing sensível à localidade.
Filtragem
Alguns dos documentos que são ingeridos no corpus podem não ser úteis para o agente, seja porque são irrelevantes para sua finalidade, muito antigos ou não confiáveis, ou porque contêm conteúdo problemático, como linguagem prejudicial. Ainda assim, outros documentos podem conter informações confidenciais que não se deseja expor por meio do agente.
Portanto, considere incluir o passo em seu pipeline para filtrar esses documentos usando quaisquer metadados, como aplicar um classificador de toxicidade ao documento para produzir uma previsão que você possa usar como filtro. Outro exemplo seria aplicar um algoritmo de detecção de informações de identificação pessoal (PII) aos documentos para filtrar documentos.
Por fim, qualquer fonte de documento que você alimenta em seu agente são potenciais vetores de ataque para que agentes mal-intencionados lancem ataques de envenenamento de dados. Você também pode considerar adicionar mecanismos de detecção e filtragem para ajudar a identificá-los e eliminá-los.
Fragmentação
Após analisar os dados brutos em um formato mais estruturado, remover duplicatas e filtrar informações indesejadas, o próximo passo é dividi-los em unidades menores e gerenciáveis, chamadas fragmentos. A segmentação de documentos grandes em fragmentos menores e semanticamente concentrados garante que os dados recuperados se encaixem no contexto do LLM, minimizando a inclusão de informações distrativas ou irrelevantes. As escolhas feitas na fragmentação afetarão diretamente os dados recuperados que o LLM fornece, tornando-a uma das primeiras camadas de otimização em uma aplicação RAG.
Ao dividir seus dados, considere os seguintes fatores:
- Estratégia de fragmentação: o método usado para dividir o texto original em fragmentos. Isso pode envolver técnicas básicas como a divisão por sentenças, parágrafos, contagens específicas de caracteres/tokens e estratégias de divisão mais avançadas e específicas do documento.
- Tamanho do chunk: Chunks menores podem se concentrar em detalhes específicos, mas perder alguma informação contextual circundante. Chunks maiores podem capturar mais contexto, mas podem incluir informação irrelevante ou ser computacionalmente caros.
- Sobreposição entre blocos: Para garantir que informações importantes não sejam perdidas ao dividir os dados em blocos, considere incluir alguma sobreposição entre blocos adjacentes. A sobreposição pode garantir a continuidade e a preservação do contexto entre blocos e melhorar os resultados da recuperação.
- Coerência semântica: Quando possível, procure criar blocos semanticamente coerentes que contenham informações relacionadas, mas que possam se sustentar independentemente como uma unidade de texto significativa. Isso pode ser alcançado considerando a estrutura dos dados originais, como parágrafos, seções ou limites de tópico.
- **Metadados:** Metadados relevantes, como o nome do documento de origem, título da seção ou nomes de produtos, podem melhorar a recuperação. Essa informação adicional pode ajudar a corresponder consultas de recuperação a fragmentos.
Estratégias de divisão de dados
Encontrar o método de divisão adequado é um processo iterativo e dependente do contexto. Não há uma abordagem única para todos os casos. O tamanho e o método de divisão ideais dependem do caso de uso específico e da natureza dos dados que estão sendo processados. Em termos gerais, as estratégias de divisão podem ser vistas da seguinte forma:
- Divisão em partes de tamanho fixo: Divida o texto em partes de um tamanho predeterminado, como um número fixo de caracteres ou tokens (por exemplo, LangChain CharacterTextSplitter). Embora a divisão por um número arbitrário de caracteres/tokens seja rápida e fácil de configurar, ela geralmente não resultará em partes semanticamente coerentes consistentes. Essa abordagem raramente funciona para aplicativos de nível de produção.
- Divisão em blocos baseada em parágrafos: Use os limites naturais dos parágrafos no texto para definir blocos. Este método pode ajudar a preservar a coerência semântica dos blocos, já que os parágrafos frequentemente contêm informações relacionadas (por exemplo, LangChain RecursiveCharacterTextSplitter).
- Fragmentação específica do formato: formatos como Markdown ou HTML têm uma estrutura inerente que pode definir limites de fragmentação (por exemplo, cabeçalhos de markdown). Ferramentas como MarkdownHeaderTextSplitter da LangChain ou divisores baseados em cabeçalho/seçãoHTML podem ser usadas para essa finalidade.
- **Fragmentação semântica:** Técnicas como modelagem de tópicos podem ser aplicadas para identificar seções semanticamente coerentes no texto. Essas abordagens analisam o conteúdo ou a estrutura de cada documento para determinar os limites de fragmentos mais apropriados com base em mudanças de tópico. Embora mais elaborada do que as abordagens básicas, a fragmentação semântica pode ajudar a criar fragmentos que estejam mais alinhados com as divisões semânticas naturais no texto (veja LangChain SemanticChunker, por exemplo).
Exemplo: Fragmentação de tamanho fixo
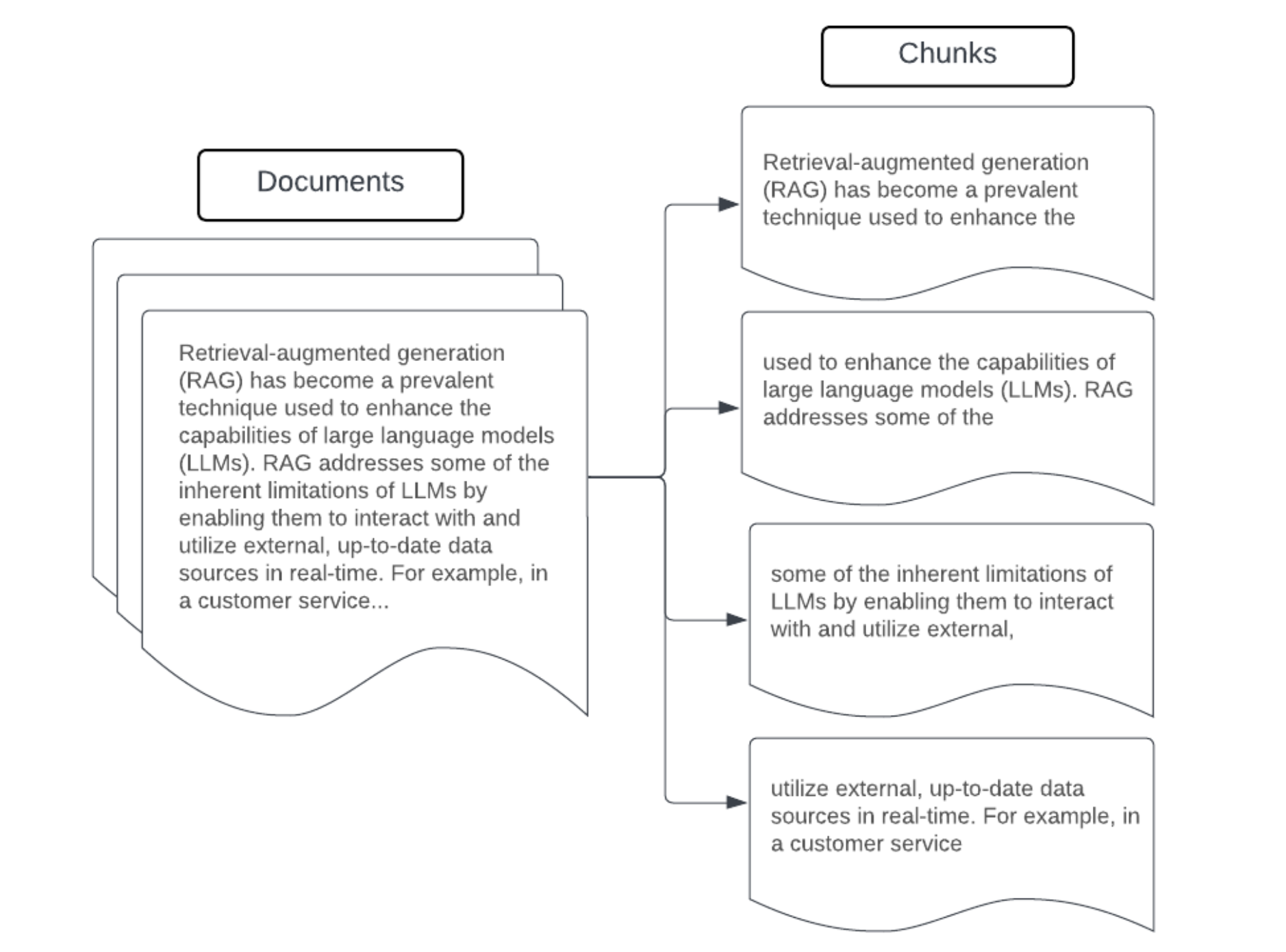
Exemplo de divisão em chunks de tamanho fixo usando o RecursiveCharacterTextSplitter do LangChain com chunk_size=100 e chunk_overlap=20. O ChunkViz oferece uma forma interativa de visualizar como diferentes tamanhos de chunk e valores de chunk overlap com os separadores de caracteres do LangChain afetam os chunks resultantes.
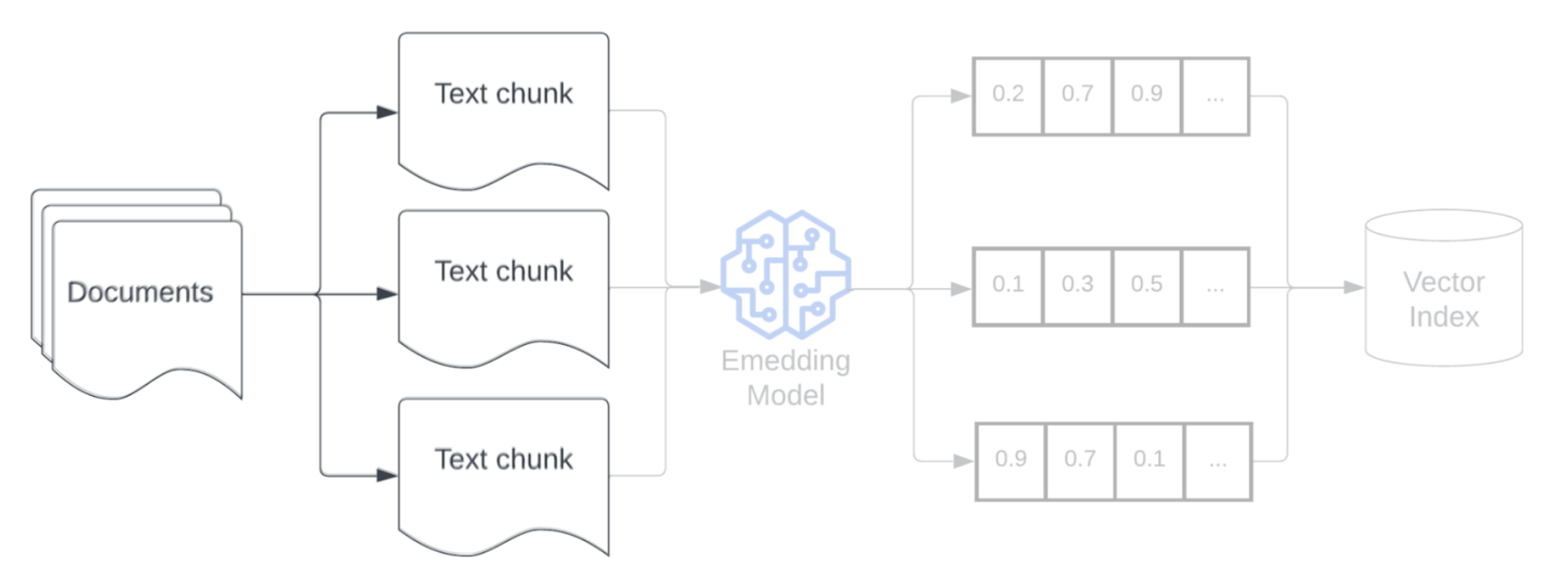
Incorporação
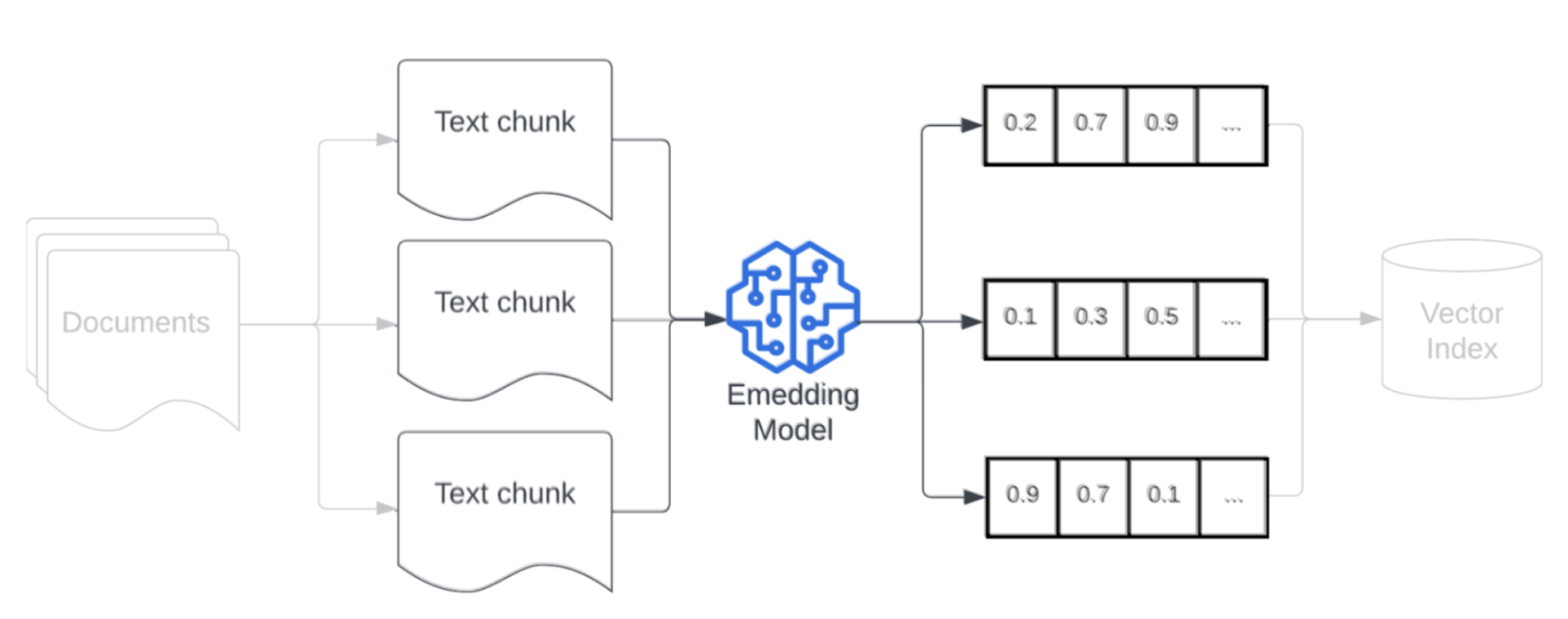
Após a fragmentação dos dados, o próximo passo é converter as partes de texto em uma representação vetorial usando um modelo de incorporação. Um modelo de incorporação converte cada parte de texto em uma representação vetorial que captura seu significado semântico. Ao representar as partes como vetores densos, as incorporações permitem uma recuperação rápida e precisa das partes mais relevantes com base em sua similaridade semântica com uma consulta de recuperação. A consulta de recuperação será transformada no momento da consulta usando o mesmo modelo de incorporação usado para incorporar partes no pipeline de dados.
Ao selecionar um modelo de incorporação, considere os seguintes fatores:
-
Escolha do Modelo: Cada modelo de incorporação tem nuances, e os benchmarks disponíveis podem não capturar as características específicas dos seus dados. É crucial selecionar um modelo que tenha sido treinado em dados semelhantes. Também pode ser benéfico explorar quaisquer modelos de incorporação disponíveis que sejam projetados para tarefas específicas. Experimente diferentes modelos de incorporação prontos para uso, mesmo aqueles que podem estar classificados mais abaixo em tabelas de classificação padrão como MTEB. Alguns exemplos a considerar:
-
Máximo de tokens: Conheça o limite máximo de tokens para o seu modelo de incorporação escolhido. Se você passar blocos que excedem este limite, eles serão truncados, potencialmente perdendo informações importantes. Por exemplo, bge-large-en-v1.5 tem um limite máximo de tokens de 512.
-
Tamanho do modelo: Modelos de incorporação maiores geralmente apresentam melhor desempenho, mas exigem mais recursos computacionais. Com base em seu caso de uso específico e recursos disponíveis, você precisará equilibrar desempenho e eficiência.
-
Ajuste fino: se sua aplicação RAG lida com linguagem específica do domínio (como acrônimos ou terminologia de empresa interna), considere fazer o ajuste fino do modelo de incorporação em dados específicos do domínio. Isso pode ajudar o modelo a capturar melhor as nuances e a terminologia do seu domínio particular e, muitas vezes, pode levar a um desempenho de recuperação aprimorado.
Indexação e armazenamento
O próximo passo no pipeline é criar índices nos embeddings e nos metadados gerados nos passos anteriores. Esta etapa envolve a organização de embeddings vetoriais de alta dimensão em estruturas de dados eficientes que permitem buscas de similaridade rápidas e precisas.
Ao implantar endpoints e índices de pesquisa de AI, a Pesquisa de AI garante pesquisas rápidas e eficientes para suas consultas. Você não precisa se preocupar em testar e escolher as melhores técnicas de indexação.
Para pipeline RAG de produção, a Databricks recomenda a Pesquisa de AI. Fragmentos e metadados são armazenados em uma tabela Delta que dá suporte a um índice de AI Search, que usa incorporações gerenciadas pela Databricks e atende a consultas de similaridade de baixa latência. Armazenar metadados junto com as incorporações na mesma tabela Delta permite a filtragem eficiente durante a recuperação.