Databricks SQL release notes 2025
The following Databricks SQL features and improvements were released in 2025.
November 2025
Databricks SQL version 2025.35 is rolling out in Current
November 20, 2025
Databricks SQL version 2025.35 is rolling out to the Current channel. See features in 2025.35.
Databricks SQL alerts are now in Public Preview
November 14, 2025
- Databricks SQL alerts: The latest version of Databricks SQL alerts, with a new editing experience, is now in Public Preview. See Databricks SQL alerts.
SQL Editor visualization fix
November 6, 2025
- Fixed tooltip display issue: Resolved an issue where tooltips were hidden behind the legend in Notebook and SQL Editor visualizations.
October 2025
Databricks SQL version 2025.35 is now available in Preview
October 30, 2025
Databricks SQL version 2025.35 is now available in the Preview channel. Review the following section to learn about new features, behavioral changes, and bug fixes.
EXECUTE IMMEDIATE using constant expressions
You can now pass constant expressions as the SQL string and as arguments to parameter markers in EXECUTE IMMEDIATE statements.
LIMIT ALL support for recursive CTEs
You can now use LIMIT ALL to remove the total size restriction on recursive common table expressions (CTEs).
st_dump function support
You can now use the st_dump function to get an array containing the single geometries of the input geometry. See st_dump function.
Polygon interior ring functions are now supported
You can now use the following functions to work with polygon interior rings:
st_numinteriorrings: Get the number of inner boundaries (rings) of a polygon. Seest_numinteriorringsfunction.st_interiorringn: Extract the n-th inner boundary of a polygon and return it as a linestring. Seest_interiorringnfunction.
Support MV/ST refresh information in DESCRIBE EXTENDED AS JSON
Databricks now generates a section for materialized view and streaming table refresh information in the DESCRIBE EXTENDED AS JSON output, including last refreshed time, refresh type, status, and schedule.
Add metadata column to DESCRIBE QUERY and DESCRIBE TABLE
Databricks now includes a metadata column in the output of DESCRIBE QUERY and DESCRIBE TABLE for semantic metadata.
For DESCRIBE QUERY, when describing a query with metric views, semantic metadata propagates through the query if dimensions are directly referenced and measures use the MEASURE() function.
For DESCRIBE TABLE, the metadata column appears only for metric views, not other table types.
Correct handling of null structs when dropping NullType columns
When writing to Delta tables, Databricks now correctly preserves null struct values when dropping NullType columns from the schema. Previously, null structs were incorrectly replaced with non-null struct values where all fields were set to null.
New alert editing experience
October 20, 2025
- New alert editing experience: Creating or editing an alert now opens in the new multi-tab editor, providing a unified editing workflow. See Databricks SQL alerts.
Visualizations fix
October 9, 2025
- Legend selection for aliased series names: Legend selection now works correctly for charts with aliased series names in SQL editor and notebooks.
Semantic metadata in metric views
October 2, 2025
You can now define semantic metadata in a metric view. Semantic metadata helps AI tools such as Genie spaces and AI/BI dashboards interpret and use your data more effectively.
To use semantic metadata, your metric view must use YAML specification version 1.1 or higher and run on Databricks Runtime 17.2 or above. The corresponding Databricks SQL version is 2025.30, available in the Preview channel for SQL warehouses.
See Use semantic metadata in metric views and Upgrade your YAML to 1.1.
September 2025
Databricks SQL version 2025.30 is now available in Preview
September 25, 2025
Databricks SQL version 2025.30 is now available in the Preview channel. Review the following section to learn about new features, behavioral changes, and bug fixes.
UTF8 based collations now support LIKE operator
You can now use LIKE with columns that have one of the following collations enabled: UTF8_Binary, UTF8_Binary_RTRIM, UTF8_LCASE, UTF8_LCASE_RTRIM. See Collation.
ST_ExteriorRing function is now supported
You can now use the ST_ExteriorRing function to extract the outer boundary of a polygon and return it as a linestring. See st_exteriorring function.
Declare multiple session or local variables in a single DECLARE statement
You can now declare multiple session or local variables of the same type and default value in a single DECLARE statement. See DECLARE VARIABLE and BEGIN END compound statement.
Support TEMPORARY keyword for metric view creation
You can now use the TEMPORARY keyword when creating a metric view. Temporary metric views are visible only in the session that created them and are dropped when the session ends. See CREATE VIEW.
DESCRIBE CONNECTION shows environment settings for JDBC connections
Databricks now includes user-defined environment settings in the DESCRIBE CONNECTION output for JDBC connections that support custom drivers and run in isolation. Other connection types remain unchanged.
SQL syntax for Delta read options in streaming queries
You can now specify Delta read options for SQL-based streaming queries using the WITH clause. For example:
SELECT * FROM STREAM tbl WITH (SKIPCHANGECOMMITS=true, STARTINGVERSION=X);
Correct results for split with empty regex and positive limit
Databricks now returns correct results when using split function with an empty regex and a positive limit. Previously, the function incorrectly truncated the remaining string instead of including it in the last element.
Fix url_decode and try_url_decode error handling in Photon
In Photon, try_url_decode() and url_decode() with failOnError = false now return NULL for invalid URL-encoded strings instead of failing the query.
August 2025
Default warehouse setting is now available in Beta
August 28, 2025
Set a default warehouse that will be automatically selected in the compute selector across the SQL editor, AI/BI dashboards, AI/BI Genie, Alerts, and Catalog Explorer. Individual users can override this setting by selecting a different warehouse before running a query. They can also define their own user-level default warehouse to apply across their sessions. See Set a default SQL warehouse for the workspace and Set a user-level default warehouse.
Databricks SQL version 2025.25 is rolling out in Current
August 21, 2025
Databricks SQL version 2025.25 is rolling out to the Current channel from August 20th, 2025 to August 28th, 2025. See features in 2025.25.
Databricks SQL version 2025.25 is now available in Preview
August 14, 2025
Databricks SQL version 2025.25 is now available in the Preview channel. Review the following section to learn about new features and behavioral changes.
Recursive common table expressions (rCTE) are generally available
Recursive common table expressions (rCTEs) are generally available. Navigate hierarchical data using a self-referencing CTE with UNION ALL to follow the recursive relationship.
Support for schema and catalog level default collation
You can now set a default collation for schemas and catalogs. This allows you to define a collation that applies to all objects created within the schema or catalog, ensuring consistent collation behavior across your data.
Support for Spatial SQL expressions and GEOMETRY and GEOGRAPHY data types
You can now store geospatial data in built-in GEOMETRY and GEOGRAPHY columns for improved performance of spatial queries. This release adds more than 80 new spatial SQL expressions, including functions for importing, exporting, measuring, constructing, editing, validating, transforming, and determining topological relationships with spatial joins. See ST geospatial functions, GEOGRAPHY type, and GEOMETRY type.
Support for schema and catalog level default collation
You can now set a default collation for schemas and catalogs. This allows you to define a collation that applies to all objects created within the schema or catalog, ensuring consistent collation behavior across your data.
Better handling of JSON options with VARIANT
The from_json and to_json functions now correctly apply JSON options when working with top-level VARIANT schemas. This ensures consistent behavior with other supported data types.
Support for TIMESTAMP WITHOUT TIME ZONE syntax
You can now specify TIMESTAMP WITHOUT TIME ZONE instead of TIMESTAMP_NTZ. This change improves compatibility with the SQL Standard.
Resolved subquery correlation issue
Databricks no longer incorrectly correlates semantically equal aggregate expressions between a subquery and its outer query. Previously, this could lead to incorrect query results.
Error thrown for invalid CHECK constraints
Databricks now throws an AnalysisException if a CHECK constraint expression cannot be resolved during constraint validation.
Stricter rules for stream-stream joins in append mode
Databricks now disallows streaming queries in append mode that use a stream-stream join followed by window aggregation, unless watermarks are defined on both sides. Queries without proper watermarks can produce non-final results, violating append mode guarantees.
New SQL editor is generally available
August 14, 2025
The new SQL editor is now generally available. The new SQL editor provides a unified authoring environment with support for multiple statement results, inline execution history, real-time collaboration, enhanced Databricks Assistant integration, and additional productivity features. See Write queries and explore data in the new SQL editor.
Fixed timeout handling for materialized views and streaming tables
August 14, 2025
New timeout behavior for materialized views and streaming tables created in Databricks SQL:
- Materialized views and streaming tables created after August 14, 2025 will have the warehouse timeout automatically applied.
- For materialized views and streaming tables created before August 14, 2025, run
CREATE OR REFRESHto synchronize the timeout setting with the timeout configuration of the warehouse. - All materialized views and streaming tables now have a default timeout of two days.
July 2025
Preset date ranges for parameters in the SQL editor
July 31, 2025
In the new SQL editor, you can now choose from preset date ranges—such as This week, Last 30 days, or Last year when using timestamp, date, and date range parameters. These presets make it faster to apply common time filters without manually entering dates.
Jobs & Pipelines list now includes Databricks SQL pipelines
July 29, 2025
The Jobs & Pipelines list now includes pipelines for materialized views and streaming tables that were created with Databricks SQL.
Inline execution history in SQL editor
July 24, 2025
Inline execution history is now available in the new SQL editor, allowing you to quickly access past results without re-executing queries. Easily reference previous executions, navigate directly to past query profiles, or compare run times and statuses—all within the context of your current query.
Databricks SQL version 2025.20 is now available in Current
July 17, 2025
Databricks SQL version 2025.20 is rolling out in stages to the Current channel. For features and updates in this release, see 2025.20 features.
SQL editor updates
July 17, 2025
-
Improvements to named parameters: Date-range and multi-select parameters are now supported. For date range parameters, see Add a date range. For multi-select parameters, see Use multiple values in a single query.
-
Updated header layout in SQL editor: The run button and catalog picker have moved to the header, creating more vertical space for writing queries.
Git support for alerts
July 17, 2025
You can now use Databricks Git folders to track and manage changes to alerts. To track alerts with Git, place them in a Databricks Git folder. Newly cloned alerts only appear in the alerts list page or API after a user interacts with them. They have paused schedules and need to be explicitly resumed by users. See How Git integration works with alerts.
Databricks SQL version 2025.20 is now available in Preview
July 3, 2025
Databricks SQL version 2025.20 is now available in the Preview channel. Review the following section to learn about new features and behavioral changes.
SQL procedure support
SQL scripts can now be encapsulated in a procedure stored as a reusable asset in Unity Catalog. You can create a procedure using the CREATE PROCEDURE command, and then call it using the CALL command.
Set a default collation for SQL Functions
Using the new DEFAULT COLLATION clause in the CREATE FUNCTION command defines the default collation used for STRING parameters, the return type, and STRING literals in the function body.
Recursive common table expressions (rCTE) support
Databricks now supports navigation of hierarchical data using recursive common table expressions (rCTEs).
Use a self-referencing CTE with UNION ALL to follow the recursive relationship.
Support ALL CATALOGS in SHOW SCHEMAS
The SHOW SCHEMAS syntax is updated to accept the following syntax:
SHOW SCHEMAS [ { FROM | IN } { catalog_name | ALL CATALOGS } ] [ [ LIKE ] pattern ]
When ALL CATALOGS is specified in a SHOW query, the execution iterates through all active catalogs that support namespaces using the catalog manager (DsV2). For each catalog, it includes the top-level namespaces.
The output attributes and schema of the command have been modified to add a catalog column indicating the catalog of the corresponding namespace. The new column is added to the end of the output attributes, as shown below:
Previous output
| Namespace |
|------------------|
| test-namespace-1 |
| test-namespace-2 |
New output
| Namespace | Catalog |
|------------------|----------------|
| test-namespace-1 | test-catalog-1 |
| test-namespace-2 | test-catalog-2 |
Liquid clustering now compacts deletion vectors more efficiently
Delta tables with Liquid clustering now apply physical changes from deletion vectors more efficiently when OPTIMIZE is running. For more details, see Apply changes to Parquet data files.
Allow non-deterministic expressions in UPDATE/INSERT column values for MERGE operations
Databricks now allows the use of non-deterministic expressions in updated and inserted column values of MERGE operations. However, non-deterministic expressions in the conditions of MERGE statements are not supported.
For example, you can now generate dynamic or random values for columns:
MERGE INTO target USING source
ON target.key = source.key
WHEN MATCHED THEN UPDATE SET target.value = source.value + rand()
This can be helpful for data privacy by obfuscating actual data while preserving the data properties (such as mean values or other computed columns).
Support VAR keyword for declaring and dropping SQL variables
SQL syntax for declaring and dropping variables now supports the VAR keyword in addition to VARIABLE. This change unifies the syntax across all variable-related operations, which improves consistency and reduces confusion for users who already use VAR when setting variables.
CREATE VIEW column-level clauses now throw errors when the clause only applies to materialized views
CREATE VIEW commands that specify a column-level clause that is only valid for MATERIALIZED VIEWs now throw an error. The affected clauses for CREATE VIEW commands are:
NOT NULL- A specified datatype, such as
FLOATorSTRING DEFAULTCOLUMN MASK
June 2025
Databricks SQL Serverless engine upgrades
June 11, 2025
The following engine upgrades are now rolling out globally, with availability expanding to all regions over the coming weeks.
- Lower latency: Dashboards, ETL jobs, and mixed workloads now run faster, with up to 25% improvement. The upgrade is automatically applied to serverless SQL warehouses with no additional cost or configuration.
- Predictive Query Execution (PQE): PQE monitors tasks in real time and dynamically adjusts query execution to help avoid skew, spills, and unnecessary work.
- Photon vectorized shuffle: Keeps data in compact columnar format, sorts it within the CPU's high-speed cache, and processes multiple values simultaneously using vectorized instructions. This improves throughput for CPU-bound workloads such as large joins and wide aggregation.
User interface updates
June 5, 2025
- Query insights improvements: Visiting the Query History page now emits the
listHistoryQueriesevent. Opening a query profile now emits thegetHistoryQueryevent.
May 2025
Metric views are in Public Preview
May 29, 2025
Unity Catalog metric views provide a centralized way to define and manage consistent, reusable, and governed core business metrics. They abstract complex business logic into a centralized definition, enabling organizations to define key performance indicators once and use them consistently across reporting tools like dashboards, Genie spaces, and alerts. Use a SQL warehouse running on the Preview channel (2025.16) or other compute resource running Databricks Runtime 16.4 or above to work with metric views. See Unity Catalog metric views.
User interface updates
May 29, 2025
- New SQL editor improvements:
- New queries in Drafts folder: New queries are now created by default in the Drafts folder. When saved or renamed, they automatically move out of Drafts.
- Query snippets support: You can now create and reuse query snippets—predefined segments of SQL such as
JOINorCASEexpressions, with support for autocomplete and dynamic insertion points. Create snippets by choosing View > Query Snippets. - Audit log events: Audit log events are now emitted for actions taken in the new SQL editor.
- Filters impact on visualizations: Filters applied to result tables now also affect visualizations, enabling interactive exploration without modifying the SQL query.
New alert version in Beta
May 22, 2025
A new version of alerts is now in Beta. This version simplifies creating and managing alerts by consolidating query setup, conditions, schedules, and notification destinations into a single interface. You can still use legacy alerts alongside the new version. See Databricks SQL alerts.
User interface updates
May 22, 2025
- Tooltip formatting in charts: Tooltips in charts from the SQL editor and notebooks now follow the number formatting defined in the Data labels tab. See Visualizations in Databricks notebooks and SQL editor.
Databricks SQL version 2025.16 is now available
May 15, 2025
Databricks SQL version 2025.16 is now available in the Preview channel. Review the following section to learn about new features, behavioral changes, and bug fixes.
IDENTIFIER support now available in Databricks SQL for catalog operations
You can now use the IDENTIFIER clause when performing the following catalog operations:
CREATE CATALOGDROP CATALOGCOMMENT ON CATALOGALTER CATALOG
This new syntax allows you to dynamically specify catalog names using parameters defined for these operations, enabling more flexible and reusable SQL workflows. As an example of the syntax, consider CREATE CATALOG IDENTIFIER(:param) where param is a parameter provided to specify a catalog name.
For more details, see IDENTIFIER clause.
Collated expressions now provide autogenerated transient aliases
Autogenerated aliases for collated expressions will now always deterministically incorporate COLLATE information. Autogenerated aliases are transient (unstable) and should not be relied on. Instead, as a best practice, use expression AS alias consistently and explicitly.
UNION/EXCEPT/INTERSECT inside a view and EXECUTE IMMEDIATE now return correct results
Queries for temporary and persistent view definitions with top-level UNION/EXCEPT/INTERSECT and un-aliased columns previously returned incorrect results because UNION/EXCEPT/INTERSECT keywords were considered aliases. Now those queries will correctly perform the whole set operation.
EXECUTE IMMEDIATE ... INTO with a top-level UNION/EXCEPT/INTERSECT and un-aliased columns also wrote an incorrect result of a set operation into the specified variable due to the parser interpreting these keywords as aliases. Similarly, SQL queries with invalid tail text were also allowed. Set operations in these cases now write a correct result into the specified variable, or fail in case of invalid SQL text.
New listagg and string_agg functions
You can now use the listagg or string_agg functions to aggregate STRING and BINARY values in a group. See string_agg for more details.
Fix for grouping on aliased integer literals broke for certain operations
Grouping expressions on an aliased integer literal was previously broken for certain operations like MERGE INTO. For example, this expression would return GROUP_BY_POS_OUT_OF_RANGE because the value (val) would be replaced with 202001:
merge into t
using
(select 202001 as val, count(current_date) as total_count group by val) on 1=1
when not matched then insert (id, name) values (val, total_count)
This has been fixed. To mitigate the issue in your existing queries, check that the constants you are using are not equal to the column position that must be in the grouping expressions.
Enable flag to disallow disabling source materialization for MERGE operations
Previously, users could disable source materialization in MERGE by setting merge.materializeSource to none. With the new flag enabled, this will be forbidden and cause an error. Databricks plans to enable the flag only for customers who haven't used this configuration flag before, so no customer should notice any change in behavior.
April 2025
Databricks SQL version 2025.15 is now available
April 10, 2025
Databricks SQL version 2025.15 is now available in the Preview channel. Review the following section to learn about new features, behavioral changes, and bug fixes.
Edit multiple columns using ALTER TABLE
You can now alter multiple columns in a single ALTER TABLE statement. See ALTER TABLE ... COLUMN clause.
Delta table protocol downgrade is GA with checkpoint protection
DROP FEATURE is generally available to remove Delta Lake table features and downgrade the table protocol. By default, DROP FEATURE now creates protected checkpoints for a more optimized and simplified downgrade experience that does not require any waiting time or history truncation. See Drop a Delta Lake table feature and downgrade table protocol.
Write procedural SQL scripts based on ANSI SQL/PSM (Public Preview)
You can now use scripting capabilities based on ANSI SQL/PSM to write procedural logic with SQL, including conditional statements, loops, local variables, and exception handling. See SQL scripting.
Table and view level default collation
You can now specify a default collation for tables and views. This simplifies the creation of table and views where all or most columns share the same collation. See Collation.
New H3 functions
The following H3 functions have been added:
Legacy dashboards support has ended
April 10, 2025
Official support for legacy dashboards has ended. You can no longer create or clone legacy dashboards using the UI or API. Databricks continues to address critical security issues and service outages, but recommends using AI/BI dashboards for all new development. To learn more about AI/BI dashboards, see Dashboards. For help migrating, see Clone a legacy dashboard to an AI/BI dashboard and Use dashboard APIs to create and manage dashboards.
Custom autoformatting options for SQL queries
April 3, 2025
Customize autoformatting options for all of your SQL queries. See Custom format SQL statements.
Boxplot visualizations issue fixed
April 3, 2025
Fixed an issue where Databricks SQL boxplot visualizations with only a categorical x-axis did not display categories and bars correctly. Visualizations now render as expected.
CAN VIEW permission for SQL warehouses is in Public Preview
April 3, 2025
CAN VIEW permission is now in Public Preview. This permission allows users to monitor SQL warehouses, including the associated query history and query profiles. Users with CAN VIEW permission cannot run queries on the SQL warehouse without being granted additional permissions. See SQL warehouse ACLs.
March 2025
User interface updates
March 27, 2025
- Query profiles updated for improved usability: Query profiles have been updated to improve usability and help you quickly access key insights. See Query profile.
User interface updates
March 20, 2025
- Transfer SQL warehouse ownership to service principal: You can now use the UI to transfer warehouse ownership to a service principal.
User interface updates
March 6, 2025
- Dual-axis charts now support zoom: You can now click and drag to zoom in on dual-axis charts.
- Pin table columns: You can now pin table columns to the left side of the table display. Columns stay in view as you scroll right on the table. See Column settings.
- Fixed an issue with combo charts: Resolved misalignment between x-axis labels and bars when using a temporal field on the x-axis.
February 2025
Databricks SQL version 2025.10 is now available
February 21, 2025
Databricks SQL version 2025.10 is now available in the Preview channel. Review the following section to learn about new features, behavioral changes, and bug fixes.
In Delta Sharing, table history is enabled by default
Shares created using the SQL command ALTER SHARE <share> ADD TABLE <table> now have history sharing (WITH HISTORY) enabled by default. See ALTER SHARE.
Credential SQL statements return an error when there's a credential type mismatch
With this release, if the credential type specified in a credential management SQL statement doesn't match the type of the credential argument, an error is returned and the statement is not run. For example, for the statement DROP STORAGE CREDENTIAL 'credential-name', if credential-name is not a storage credential, the statement fails with an error.
This change is made to help prevent user errors. Previously, these statements would run successfully, even if a credential that didn't match the specified credential type was passed. For example, the following statement would successfully drop storage-credential: DROP SERVICE CREDENTIAL storage-credential.
This change affects the following statements:
- DROP CREDENTIAL
- ALTER CREDENTIAL
- DESCRIBE CREDENTIAL
- GRANT…ON…CREDENTIAL
- REVOKE…ON…CREDENTIAL
- SHOW GRANTS ON…CREDENTIAL
Use the timestampdiff & timestampadd in generated column expressions
Delta Lake generated column expressions now support timestampdiff and timestampadd functions.
Support for SQL pipeline syntax
You can now compose SQL pipelines. A SQL pipeline structures a standard query, such as SELECT c2 FROM T WHERE c1 = 5, into a step-by-step sequence, as shown in the following example:
FROM T
|> SELECT c2
|> WHERE c1 = 5
To learn about the supported syntax for SQL pipelines, see SQL Pipeline Syntax.
For background on this cross-industry extension, see SQL Has Problems. We Can Fix Them: Pipe Syntax In SQL (by Google Research).
Make HTTP request using the http_request function
You can now create HTTP connections and through them make HTTP requests using the http_request function.
Update to DESCRIBE TABLE returns metadata as structured JSON
You can now use the DESCRIBE TABLE AS JSON command to return table metadata as a JSON document. The JSON output is more structured than the default human-readable report and can be used to interpret a table's schema programmatically. To learn more, see DESCRIBE TABLE AS JSON.
Trailing blank insensitive collations
Added support for trailing blank insensitive collations. For example, these collations treat 'Hello' and 'Hello ' as equal. To learn more, see RTRIM collation.
Improved incremental clone processing
This release includes a fix for an edge case where an incremental CLONE might re-copy files already copied from a source table to a target table. See Clone a table on Databricks.
User interface updates
February 13, 2025
- Preview Unity Catalog metadata in data discovery: Preview metadata for Unity Catalog assets by hovering over an asset in the schema browser. This capability is available in Catalog Explorer and other interfaces where you use the schema browser, such as AI/BI dashboards and the SQL editor.
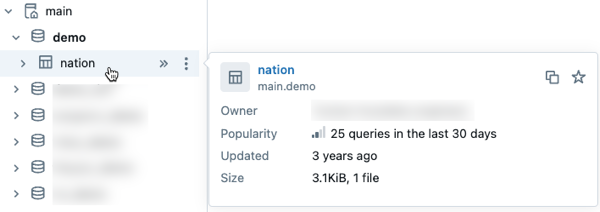
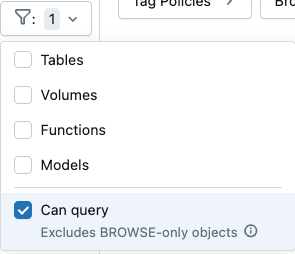
- Filter to find data assets you can query: Filter settings in Catalog Explorer's schema browser now includes a Can query checkbox. Selecting this option excludes objects that you can view but not query.
January 2025
User interface updates
January 30, 2025
-
Completed query count chart for SQL warehouses (Public Preview): A new Completed query count chart is now available on the SQL warehouse monitoring UI. This chart shows the number of queries finished in a time window, including canceled and failed queries. The chart can be used with the other charts and the Query History table to assess and troubleshoot the performance of the warehouse. The query is allocated in the time window it is completed. Counts are averaged per minute. For more information, see Monitor a SQL warehouse.
-
Expanded data display in SQL editor charts: Visualizations created in the SQL editor now support up to 15,000 rows of data.
Databricks SQL version 2024.50 is now available
January 23, 2025
Databricks SQL version 2024.50 is now available in the Preview channel. Review the following section to learn about new features, behavioral changes, and bug fixes.
The VARIANT data type can no longer be used with operations that require comparisons
You cannot use the following clauses or operators in queries that include a VARIANT data type:
DISTINCTINTERSECTEXCEPTUNIONDISTRIBUTE BY
These operations perform comparisons, and comparisons that use the VARIANT data type produce undefined results and are not supported in Databricks. If you use the VARIANT type in your Databricks workloads or tables, Databricks recommends the following changes:
- Update queries or expressions to explicitly cast
VARIANTvalues to non-VARIANTdata types. - If you have fields that must be used with any of the above operations, extract those fields from the
VARIANTdata type and store them using non-VARIANTdata types.
To learn more, see Query variant data.
Support for parameterizing the USE CATALOG with IDENTIFIER clause
The IDENTIFIER clause is supported for the USE CATALOG statement. With this support, you can parameterize the current catalog based on a string variable or parameter marker.
COMMENT ON COLUMN support for tables and views
The COMMENT ON statement supports altering comments for view and table columns.
New SQL functions
The following new built-in SQL functions are available:
- dayname(expr) returns the three-letter English acronym for the day of the week for the given date.
- uniform(expr1, expr2 [,seed]) returns a random value with independent and identically distributed values within the specified range of numbers.
- randstr(length) returns a random string of
lengthalpha-numeric characters.
Named parameter invocation for more functions
The following functions support named parameter invocation:
Nested types now properly accept NULL constraints
This release fixes a bug affecting some Delta generated columns of nested types, for example, STRUCT. These columns would sometimes incorrectly reject expressions based on NULL or NOT NULL constraints of nested fields. This has been fixed.
SQL editor user interface updates
January 15, 2025
The new SQL editor (Public Preview) includes the following user interface improvements:
- Enhanced download experience: Query outputs are automatically named after the query when downloaded.
- Keyboard shortcuts for font sizing: Use
Alt +andAlt -(Windows/Linux) orOpt +andOpt -(macOS) to quickly adjust font size in the SQL editor. - User mentions in comments: Tag specific users with
@in comments to send them email notifications. - Faster tab navigation: Tab switching is now up to 80% faster for loaded tabs and 62% faster for unloaded tabs.
- Streamlined warehouse selection: SQL Warehouse size information is displayed directly in the compute selector for easier selection.
- Parameter editing shortcuts: Use
Ctrl + Enter(Windows/Linux) orCmd + Enter(macOS) to execute queries while editing parameter values. - Enhanced version control: Query results are preserved in version history for better collaboration.
Chart visualization updates
January 15, 2025
The new chart system with improved performance, enhanced color schemes, and faster interactivity is now generally available. See Visualizations in Databricks notebooks and SQL editor and Notebook and SQL editor visualization types.