Debug code using Databricks Connect for the Databricks extension for Visual Studio Code
This article describes how to use the Databricks Connect integration in the Databricks extension for Visual Studio Code to run and debug individual Python (.py) files. For information about the extension, see Databricks extension for Visual Studio Code.
The Databricks Connect integration also allows you to run and debug notebook cells. See Run and debug notebook cells with Databricks Connect using the Databricks extension for Visual Studio Code.
Requirements
Before you can use Databricks Connect from within the Databricks extension for Visual Studio Code, you must first meet the Databricks Connect requirements. These requirements include things such as a Unity Catalog-enabled workspace, compute requirements, and version requirements for your local installation of Python.
Activate a Python virtual environment
Activate a Python virtual environment for your Python project. Python virtual environments help to make sure that your project is using compatible versions of Python and Python packages (in this case, the Databricks Connect package).
In the Configuration pane:
- Click the red Activate Virtual Environment item under Python Environment.
- In the Command Palette, select Venv or Conda.
- Select the dependencies you want to install, if any.
Install Databricks Connect
In the Configuration view under Python Environment:
- Click the red Install databricks-connect play button.
- Attach a cluster.
- If the Cluster section is not already configured in the extension, the following message appears: “Please attach a cluster to use Databricks Connect.” Click Attach Cluster and select a cluster that meets the Databricks Connect requirements.
- If the Cluster section is configured but the cluster is not compatible with Databricks Connect, click the red Databricks Connect disabled button, click Attach Cluster, and select a compatible cluster.
- If the Databricks Connect package (and its dependencies) are not already installed, the following message appears: “For interactive debugging and autocompletion you need Databricks Connect. Would you like to install it in the environment
<environment-name>.” Click Install. - In the Visual Studio Code status bar, if the red Databricks Connect disabled button appears, click it, and complete the on-screen instructions to enable it.
- After the Databricks Connect enabled button appears, you are now ready to use Databricks Connect.
If you use Poetry, you can synchronize your pyproject.toml and poetry.lock files with the installed Databricks Connect package (and its dependencies) by running the following command. Be sure to replace 16.4.1 with the version of the Databricks Connect package that matches the one that was installed by the Databricks extension for Visual Studio Code for your project.
poetry add databricks-connect==16.4.1
Run or debug your Python code
After you enable Databricks Connect, run or debug your Python file (.py):
-
In your project, open the Python file that you want to run or debug.
-
Set any debugging breakpoints within the Python file.
-
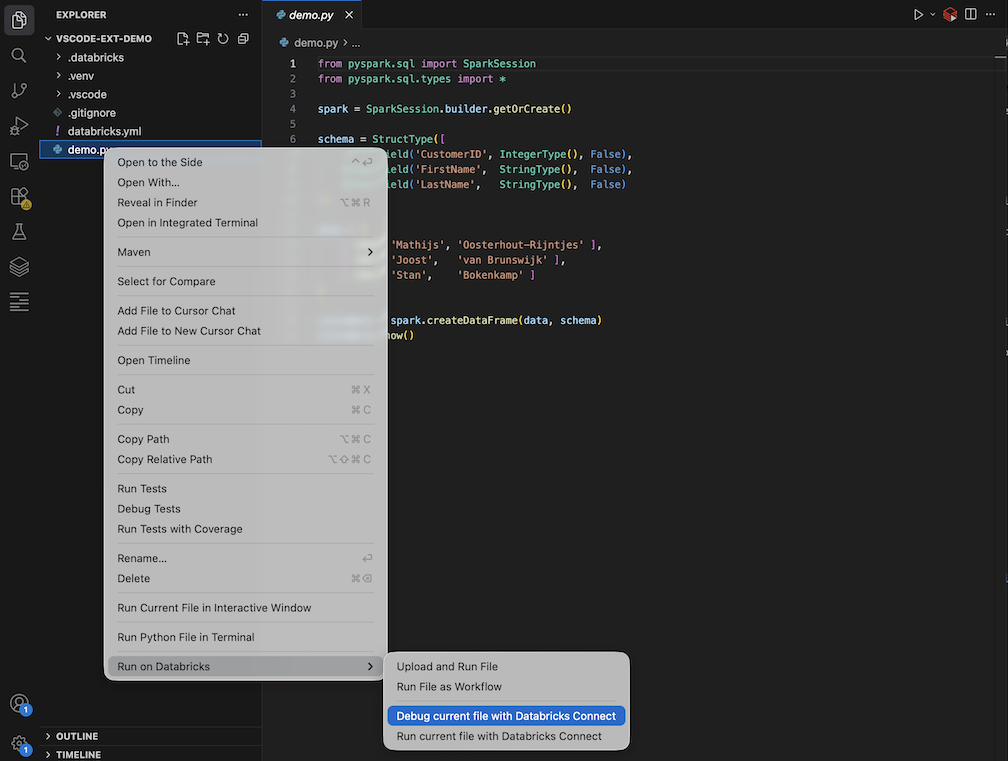
Click the Run on Databricks icon next to the list of editor tabs, and then click Debug current file with Databricks Connect.
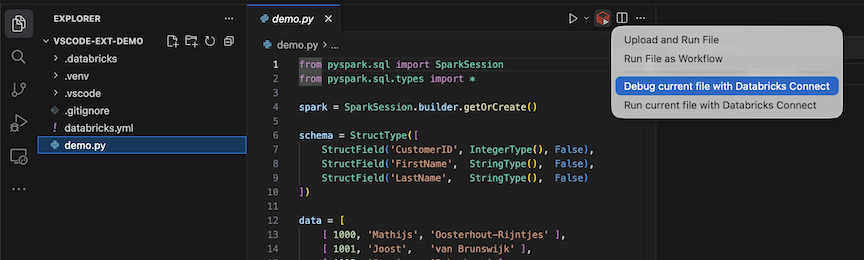
The output appears in the Debug Console pane.
You can also right-click the
.pyfile, and then click Run on Databricks > Debug current file with Databricks Connect.