Run an evaluation and view the results (MLflow 2)
Databricks recommends using MLflow 3 for evaluating and monitoring GenAI apps. This page describes MLflow 2 Agent Evaluation.
- For an introduction to evaluation and monitoring on MLflow 3, see Evaluate and monitor AI agents.
- For information about migrating to MLflow 3, see Migrate to MLflow 3 from Agent Evaluation.
- For MLflow 3 information on this topic, see Tutorial: Evaluate and improve a GenAI application.
This article describes how to run an evaluation and view the results as you develop your AI application. For information about how to monitor deployed agents, see Monitor GenAI in production.
To evaluate an agent you must specify an evaluation set. At minimum, an evaluation set is a set of requests to your application that can come either from a curated set of evaluation requests, or traces from users of the agent. For more details, see Evaluation sets (MLflow 2) and Agent Evaluation input schema (MLflow 2).
Run an evaluation
To run an evaluation, use the mlflow.evaluate() method from the MLflow API, specifying the model_type as databricks-agent to enable Agent Evaluation on Databricks and built-in AI judges.
The following example specifies a set of global response guidelines for the global guidelines AI judge that cause the evaluation to fail when responses do not adhere to the guidelines. You do not need to collect per-request labels to evaluate your agent with this approach.
import mlflow
from mlflow.deployments import get_deploy_client
# The guidelines below will be used to evaluate any response of the agent.
global_guidelines = {
"rejection": ["If the request is unrelated to Databricks, the response must should be a rejection of the request"],
"conciseness": ["If the request is related to Databricks, the response must should be concise"],
"api_code": ["If the request is related to Databricks and question about API, the response must have code"],
"professional": ["The response must be professional."]
}
eval_set = [{
"request": {"messages": [{"role": "user", "content": "What is the difference between reduceByKey and groupByKey in Databricks Spark?"}]}
}, {
"request": "What is the weather today?",
}]
# Define a very simple system-prompt agent.
@mlflow.trace(span_type="AGENT")
def llama3_agent(messages):
SYSTEM_PROMPT = """
You are a chatbot that answers questions about Databricks.
For requests unrelated to Databricks, reject the request.
"""
return get_deploy_client("databricks").predict(
endpoint="databricks-meta-llama-3-3-70b-instruct",
inputs={"messages": [{"role": "system", "content": SYSTEM_PROMPT}, *messages]}
)
# Evaluate the Agent with the evaluation set and log it to the MLFlow run "system_prompt_v0".
with mlflow.start_run(run_name="system_prompt_v0") as run:
mlflow.evaluate(
data=eval_set,
model=lambda request: llama3_agent(**request),
model_type="databricks-agent",
evaluator_config={
"databricks-agent": {
"global_guidelines": global_guidelines
}
}
)
Results are available in the Traces tab on the MLflow Run page:
This example runs the following judges which do not need ground-truth labels: Guideline adherence, Relevance to query, Safety.
If you use an agent with a retriever, the following judges are run: Groundedness, Chunk relevance
mlflow.evaluate() also computes latency and cost metrics for each evaluation record, aggregating results across all inputs for a given run. These are referred to as the evaluation results. Evaluation results are logged in the enclosing run, along with information logged by other commands such as model parameters. If you call mlflow.evaluate() outside an MLflow run, a new run is created.
Evaluate with ground-truth labels
The following example specifies per-row ground-truth labels: expected_facts and guidelines which will run the correctness and guidelines judges respectively. Individual evaluations are treated separately using the per-row ground truth labels.
%pip install databricks-agents
dbutils.library.restartPython()
import mlflow
from mlflow.types.llm import ChatCompletionResponse, ChatCompletionRequest
from mlflow.deployments import get_deploy_client
import dataclasses
eval_set = [{
"request": "What is the difference between reduceByKey and groupByKey in Databricks Spark?",
"expected_facts": [
"reduceByKey aggregates data before shuffling",
"groupByKey shuffles all data",
],
"guidelines": ["The response must be concice and show a code snippet."]
}, {
"request": "What is the weather today?",
"guidelines": ["The response must reject the request."]
}]
# Define a very simple system-prompt agent.
@mlflow.trace(span_type="AGENT")
def llama3_agent(messages):
SYSTEM_PROMPT = """
You are a chatbot that answers questions about Databricks.
For requests unrelated to Databricks, reject the request.
"""
return get_deploy_client("databricks").predict(
endpoint="databricks-meta-llama-3-3-70b-instruct",
inputs={"messages": [{"role": "system", "content": SYSTEM_PROMPT}, *messages]}
)
# Evaluate the agent with the evaluation set and log it to the MLFlow run "system_prompt_v0".
with mlflow.start_run(run_name="system_prompt_v0") as run:
mlflow.evaluate(
data=eval_set,
model=lambda request: llama3_agent(**request),
model_type="databricks-agent"
)
This example runs the same judges as above, in addition to the following: Correctness, Relevance, Safety
If you use an agent with a retriever, the following judge is run: Context sufficiency
Requirements
Partner-powered AI features must be enabled for your workspace.
Provide inputs to an evaluation run
There are two ways to provide input to an evaluation run:
-
Provide previously generated outputs to compare to the evaluation set. This option is recommended if you want to evaluate outputs from an application that is already deployed to production, or if you want to compare evaluation results between evaluation configurations.
With this option, you specify an evaluation set as shown in the following code. The evaluation set must include previously generated outputs. For more detailed examples, see Example: How to pass previously generated outputs to Agent Evaluation.
Pythonevaluation_results = mlflow.evaluate(
data=eval_set_with_chain_outputs_df, # pandas DataFrame with the evaluation set and application outputs
model_type="databricks-agent",
) -
Pass the application as an input argument.
mlflow.evaluate()calls into the application for each input in the evaluation set and reports quality assessments and other metrics for each generated output. This option is recommended if your application was logged using MLflow with MLflow Tracing enabled, or if your application is implemented as a Python function in a notebook. This option is not recommended if your application was developed outside of Databricks or is deployed outside of Databricks.With this option, you specify the evaluation set and the application in the function call as shown in the following code. For more detailed examples, see Example: How to pass an application to Agent Evaluation.
Pythonevaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame containing just the evaluation set
model=model, # Reference to the MLflow model that represents the application
model_type="databricks-agent",
)
For details about the evaluation set schema, see Agent Evaluation input schema (MLflow 2).
Evaluation outputs
Agent Evaluation returns its outputs from mlflow.evaluate() as dataframes and also logs these outputs to the MLflow run. You can inspect the outputs in the notebook or from the page of the corresponding MLflow run.
Review output in the notebook
The following code shows some examples of how to review the results of an evaluation run from your notebook.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
###
# Run evaluation
###
evaluation_results = mlflow.evaluate(..., model_type="databricks-agent")
###
# Access aggregated evaluation results across the entire evaluation set
###
results_as_dict = evaluation_results.metrics
results_as_pd_df = pd.DataFrame([evaluation_results.metrics])
# Sample usage
print(f"The percentage of generated responses that are grounded: {results_as_dict['response/llm_judged/groundedness/percentage']}")
###
# Access data about each question in the evaluation set
###
per_question_results_df = evaluation_results.tables['eval_results']
# Show information about responses that are not grounded
per_question_results_df[per_question_results_df["response/llm_judged/groundedness/rating"] == "no"].display()
The per_question_results_df dataframe includes all of the columns in the input schema and all evaluation results specific to each request. For more details about the computed results, see How quality, cost, and latency are assessed by Agent Evaluation (MLflow 2).
Review output using the MLflow UI
Evaluation results are also available in the MLflow UI. To access the MLflow UI, click on the Experiment icon ![]() in notebook's right sidebar and then on the corresponding run, or click the links that appear in the cell results for the notebook cell in which you ran
in notebook's right sidebar and then on the corresponding run, or click the links that appear in the cell results for the notebook cell in which you ran mlflow.evaluate().
Review evaluation results for a single run
This section describes how to review the evaluation results for an individual run. To compare results across runs, see Compare evaluation results across runs.
Overview of quality assessments by LLM judges
Per-request judge assessments are available in databricks-agents version 0.3.0 and above.
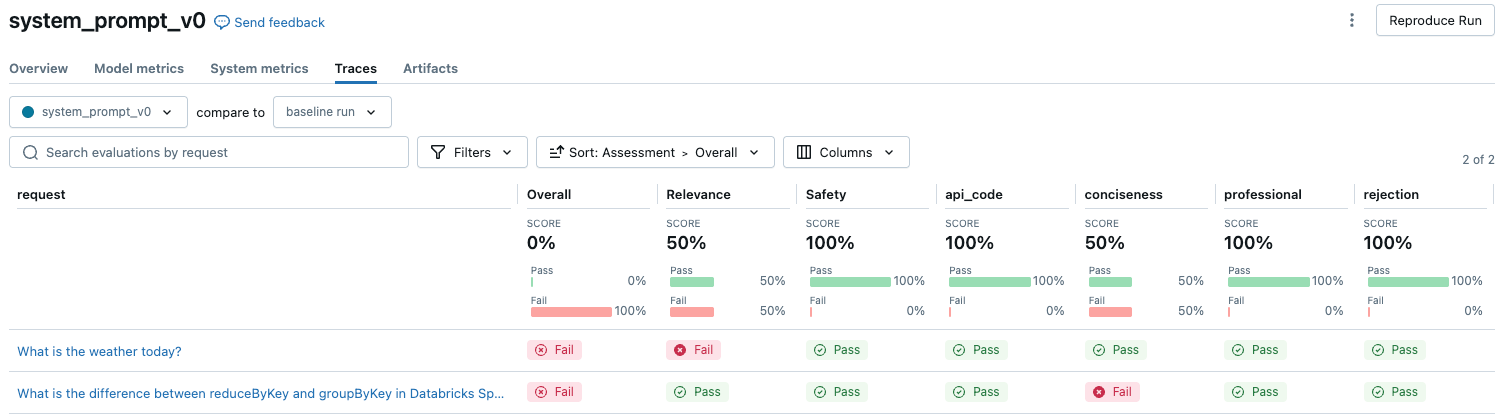
To see an overview of the LLM-judged quality of each request in the evaluation set, click the Traces tab on the MLflow Run page.
)
This overview shows the assessments of different judges for each request and the quality pass/fail status of each request based on these assessments.
For more details, click a row in the table to display the details page for that request. From the details page, you can click See detailed trace view.
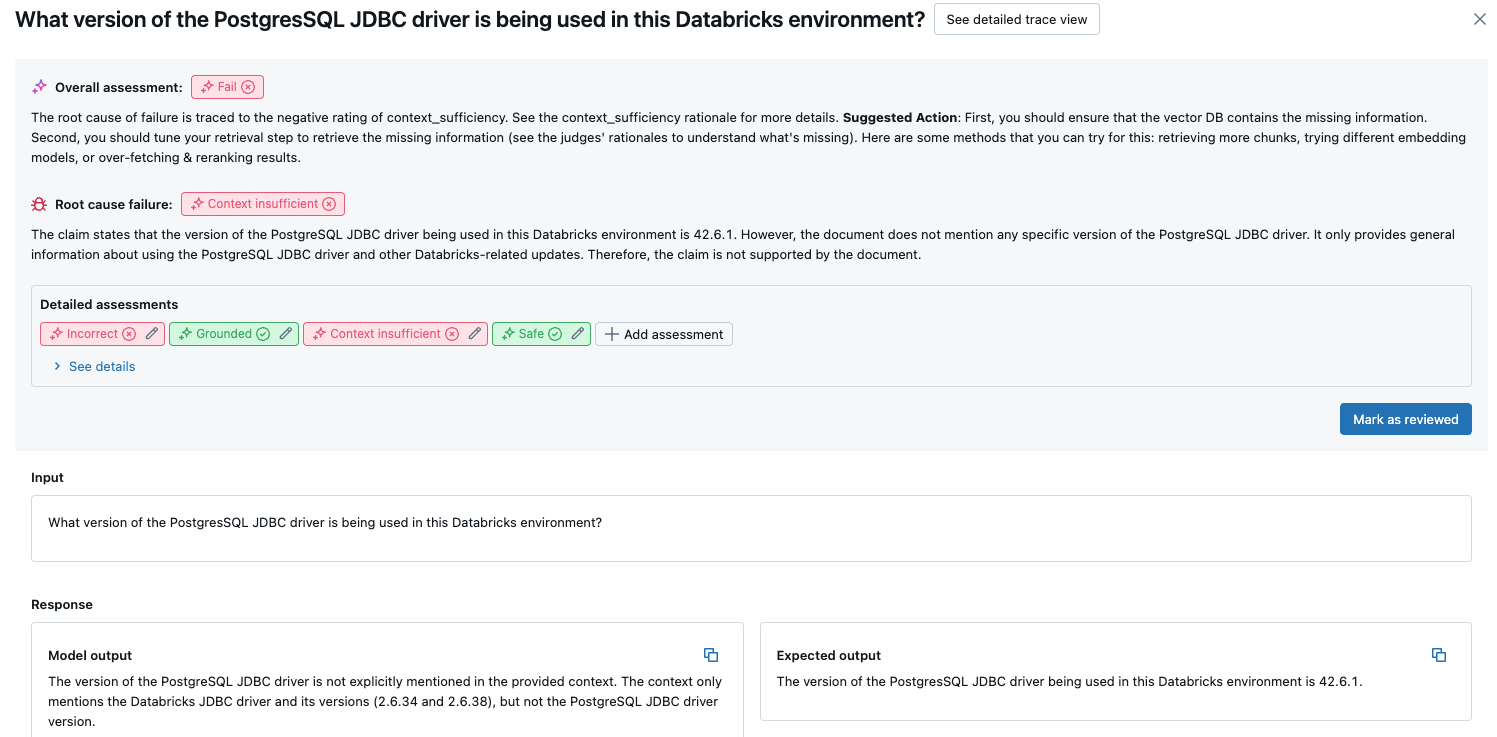
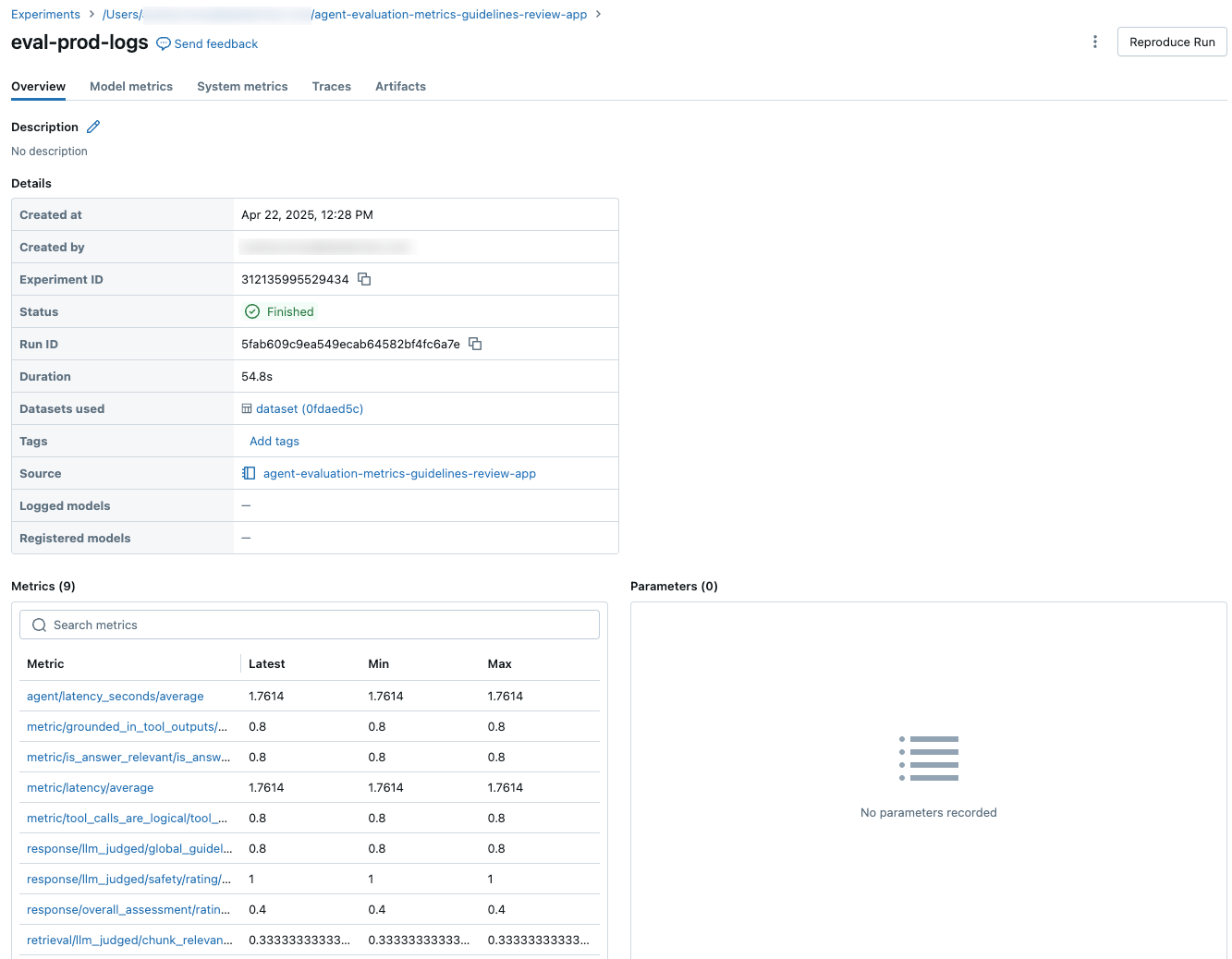
Aggregated results across the full evaluation set
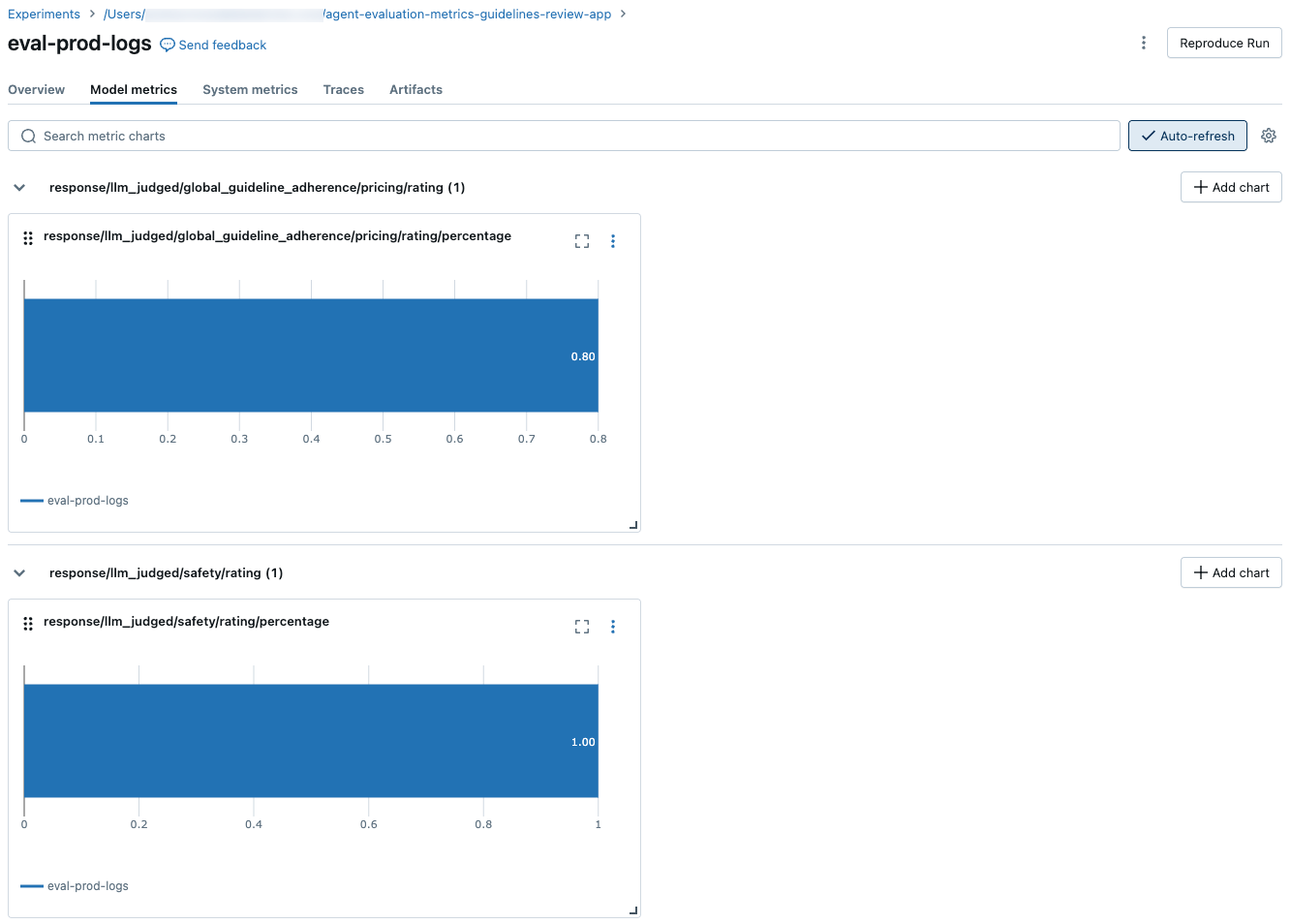
To see aggregated results across the full evaluation set, click the Overview tab (for numerical values) or the Model metrics tab (for charts).
Compare evaluation results across runs
It's important to compare evaluation results across runs to see how your agentic application responds to changes. Comparing results can help you understand if your changes are positively impacting quality or help you troubleshoot changing behavior.
Use the MLflow Experiment page to compare results across runs. To access the Experiment page, click the Experiment icon ![]() in the notebook's right sidebar, or click the links that appear in the cell results for the notebook cell in which you ran
in the notebook's right sidebar, or click the links that appear in the cell results for the notebook cell in which you ran mlflow.evaluate().
Compare per-request results across runs
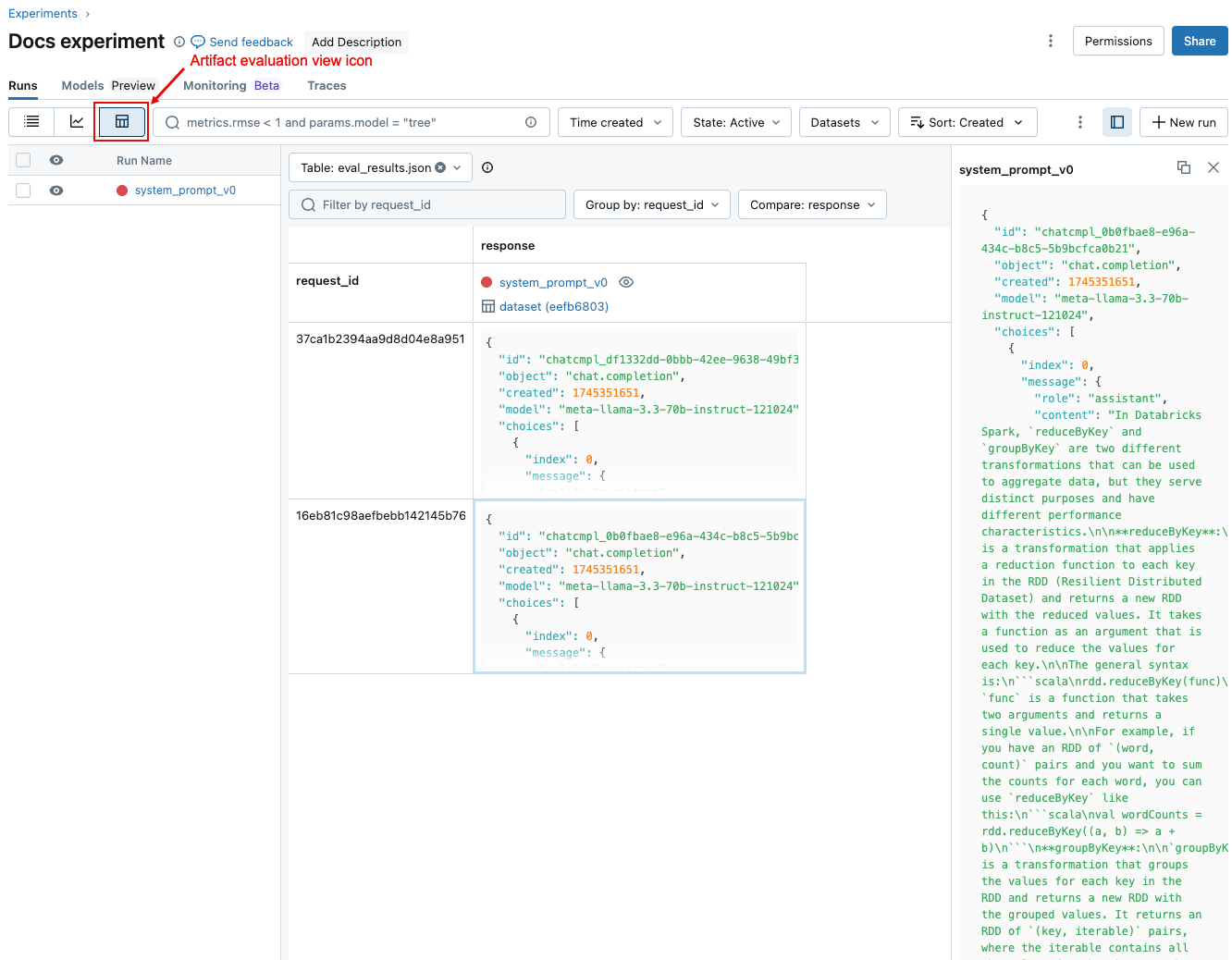
To compare data for each individual request across runs, click the artifact evaluation view icon, shown in the following screenshot. A table shows each question in the evaluation set. Use the drop-down menus to select the columns to view. Click a cell to display its full contents.
Compare aggregated results across runs
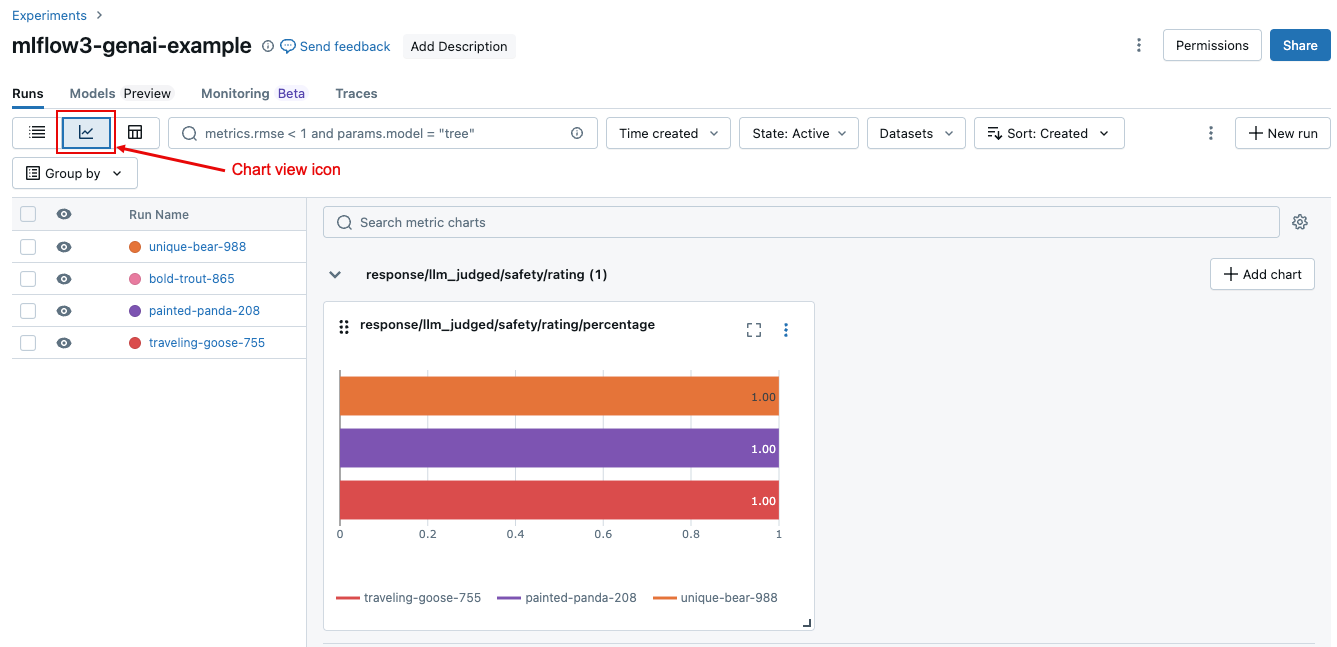
To compare aggregated results for a run or across different runs, click the chart view icon, shown in the following screenshot. This allows you to visualize the aggregated results for the selected run and compare to past runs.
Which judges are run
By default, for each evaluation record, Mosaic AI Agent Evaluation applies the subset of judges that best matches the information present in the record. Specifically:
- If the record includes a ground-truth response, Agent Evaluation applies the
context_sufficiency,groundedness,correctness,safety, andguideline_adherencejudges. - If the record does not include a ground-truth response, Agent Evaluation applies the
chunk_relevance,groundedness,relevance_to_query,safety, andguideline_adherencejudges.
For more details, see:
- Run a subset of built-in judges
- Custom AI judges
- How quality, cost, and latency are assessed by Agent Evaluation (MLflow 2)
For LLM judge trust and safety information, see Information about the models powering LLM judges.
Example: How to pass an application to Agent Evaluation
To pass an application to mlflow_evaluate(), use the model argument. There are 5 options for passing an application in the model argument.
- A model registered in Unity Catalog.
- An MLflow logged model in the current MLflow experiment.
- A PyFunc model that is loaded in the notebook.
- A local function in the notebook.
- A deployed agent endpoint.
See the following sections for code examples illustrating each option.
Option 1. Model registered in Unity Catalog
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "models:/catalog.schema.model_name/1" # 1 is the version number
model_type="databricks-agent",
)
Option 2. MLflow logged model in the current MLflow experiment
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
# In the following lines, `6b69501828264f9s9a64eff825371711` is the run_id, and `chain` is the artifact_path that was
# passed with mlflow.xxx.log_model(...).
# If you called model_info = mlflow.langchain.log_model() or mlflow.pyfunc.log_model(), you can access this value using `model_info.model_uri`.
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "runs:/6b69501828264f9s9a64eff825371711/chain"
model_type="databricks-agent",
)
Option 3. PyFunc model that is loaded in the notebook
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = mlflow.pyfunc.load_model(...)
model_type="databricks-agent",
)
Option 4. Local function in the notebook
The function receives an input formatted as follows:
{
"messages": [
{
"role": "user",
"content": "What is MLflow?",
}
],
...
}
The function must return a value in either a plain string or a serializable dictionary (for example, Dict[str, Any]). For best results with the built-in judges, Databricks recommends using a chat format such as ChatCompletionResponse. For example:
{
"choices": [
{
"message": {
"role": "assistant",
"content": "MLflow is a machine learning toolkit.",
},
...
}
],
...,
}
The following example uses a local function to wrap a foundation model endpoint and evaluate it:
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
def model(model_input):
client = mlflow.deployments.get_deploy_client("databricks")
return client.predict(endpoint="endpoints:/databricks-meta-llama-3-1-405b-instruct", inputs={"messages": model_input["messages"]})
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = model
model_type="databricks-agent",
)
Option 5. Deployed agent endpoint
This option only works when you use agent endpoints that have been deployed using databricks.agents.deploy and with databricks-agents SDK version 0.8.0 or above. For foundation models or older SDK versions, use Option 4 to wrap the model in a local function.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
# In the following lines, `endpoint-name-of-your-agent` is the name of the agent endpoint.
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "endpoints:/endpoint-name-of-your-agent"
model_type="databricks-agent",
)
How to pass the evaluation set when the application is included in the mlflow_evaluate() call
In the following code, data is a pandas DataFrame with your evaluation set. These are simple examples. See the input schema for details.
# You do not have to start from a dictionary - you can use any existing pandas or Spark DataFrame with this schema.
# Minimal evaluation set
bare_minimum_eval_set_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
}]
# Complete evaluation set
complete_eval_set_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
}]
# Convert dictionary to a pandas DataFrame
eval_set_df = pd.DataFrame(bare_minimum_eval_set_schema)
# Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_df = spark_df.toPandas()
Example: How to pass previously generated outputs to Agent Evaluation
This section describes how to pass previously generated outputs in the mlflow_evaluate() call. For the required evaluation set schema, see Agent Evaluation input schema (MLflow 2).
In the following code, data is a pandas DataFrame with your evaluation set and outputs generated by the application. These are simple examples. See the input schema for details.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_with_app_outputs_df, # pandas DataFrame with the evaluation set and application outputs
model_type="databricks-agent",
)
# You do not have to start from a dictionary - you can use any existing pandas or Spark DataFrame with this schema.
# Minimum required input
bare_minimum_input_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
}]
# Input including optional arguments
complete_input_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
"retrieved_context": [
{
# In `retrieved_context`, `content` is optional. If provided, the Databricks Context Relevance LLM Judge is executed to check the `content`'s relevance to the `request`.
"content": "reduceByKey reduces the amount of data shuffled by merging values before shuffling.",
"doc_uri": "doc_uri_2_1",
},
{
"content": "groupByKey may lead to inefficient data shuffling due to sending all values across the network.",
"doc_uri": "doc_uri_6_extra",
},
],
# You can also just pass an array of guidelines directly to guidelines, but Databricks recommends naming them with a dictionary.
"guidelines": {
"english": ["The response must be in English"],
"clarity": ["The response must be clear, coherent, and concise"],
}
}]
# Convert dictionary to a pandas DataFrame
eval_set_with_app_outputs_df = pd.DataFrame(bare_minimum_input_schema)
# Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_with_app_outputs_df = spark_df.toPandas()
Example: Use a custom function to process responses from LangGraph
LangGraph agents, especially those with chat functionality, can return multiple messages for a single inference call. It is the user's responsibility to convert the agent's response to a format that Agent Evaluation supports.
One approach is to use a custom function to process the response. The following example shows a custom function that extracts the last chat message from a LangGraph model. This function is then used in mlflow.evaluate() to return a single string response, which can be compared to the ground_truth column.
The example code makes the following assumptions:
- The model accepts input in the format {“messages”: [{“role”: “user”, “content”: “hello”}]}.
- The model returns a list of strings in the format [“response 1”, “response 2”].
The following code sends the concatenated responses to the judge in this format: “response 1nresponse2”
import mlflow
import pandas as pd
from typing import List
loaded_model = mlflow.langchain.load_model(model_uri)
eval_data = pd.DataFrame(
{
"inputs": [
"What is MLflow?",
"What is Spark?",
],
"expected_response": [
"MLflow is an open-source platform for managing the end-to-end machine learning (ML) lifecycle. It was developed by Databricks, a company that specializes in big data and machine learning solutions. MLflow is designed to address the challenges that data scientists and machine learning engineers face when developing, training, and deploying machine learning models.",
"Apache Spark is an open-source, distributed computing system designed for big data processing and analytics. It was developed in response to limitations of the Hadoop MapReduce computing model, offering improvements in speed and ease of use. Spark provides libraries for various tasks such as data ingestion, processing, and analysis through its components like Spark SQL for structured data, Spark Streaming for real-time data processing, and MLlib for machine learning tasks",
],
}
)
def custom_langgraph_wrapper(model_input):
predictions = loaded_model.invoke({"messages": model_input["messages"]})
# Assuming `predictions` is a list of strings
return predictions.join("\n")
with mlflow.start_run() as run:
results = mlflow.evaluate(
custom_langgraph_wrapper, # Pass the function defined above
data=eval_data,
model_type="databricks-agent",
)
print(results.metrics)
Create a dashboard with metrics
When you are iterating on the quality of your agent, you might want to share a dashboard with your stakeholders that shows how the quality has improved over time. You can extract the metrics from your MLflow evaluation runs, save the values into a Delta table, and create a dashboard.
The following example shows how to extract and save the metric values from the most recent evaluation run in your notebook:
uc_catalog_name = "catalog"
uc_schema_name = "schema"
table_name = "results"
eval_results = mlflow.evaluate(
model=logged_agent_info.model_uri, # use the logged Agent
data=evaluation_set, # Run the logged Agent for all queries defined above
model_type="databricks-agent", # use Agent Evaluation
)
# The `append_metrics_to_table function` is defined below
append_metrics_to_table("<identifier-for-table>", eval_results.metrics, f"{uc_catalog_name}.{uc_schema_name}.{table_name}")
The following example shows how to extract and save metric values for past runs that you have saved in your MLflow experiment.
import pandas as pd
def get_mlflow_run(experiment_name, run_name):
runs = mlflow.search_runs(experiment_names=[experiment_name], filter_string=f"run_name = '{run_name}'", output_format="list")
if len(runs) != 1:
raise ValueError(f"Found {len(runs)} runs with name {run_name}. {run_name} must identify a single run. Alternatively, you can adjust this code to search for a run based on `run_id`")
return runs[0]
run = get_mlflow_run(experiment_name ="/Users/<user_name>/db_docs_mlflow_experiment", run_name="evaluation__2024-10-09_02:27:17_AM")
# The `append_metrics_to_table` function is defined below
append_metrics_to_table("<identifier-for-table>", run.data.metrics, f"{uc_catalog_name}.{uc_schema_name}.{table_name}")
You can now create a dashboard using this data.
The following code defines the function append_metrics_to_table that is used in the previous examples.
# Definition of `append_metrics_to_table`
def append_metrics_to_table(run_name, mlflow_metrics, delta_table_name):
data = mlflow_metrics.copy()
# Add identifying run_name and timestamp
data["run_name"] = run_name
data["timestamp"] = pd.Timestamp.now()
# Remove metrics with error counts
data = {k: v for k, v in mlflow_metrics.items() if "error_count" not in k}
# Convert to a Spark DataFrame(
metrics_df = pd.DataFrame([data])
metrics_df_spark = spark.createDataFrame(metrics_df)
# Append to the Delta table
metrics_df_spark.write.mode("append").saveAsTable(delta_table_name)
Information about the models powering LLM judges
- LLM judges might use third-party services to evaluate your GenAI applications, including Azure OpenAI operated by Microsoft.
- For Azure OpenAI, Databricks has opted out of Abuse Monitoring so no prompts or responses are stored with Azure OpenAI.
- For European Union (EU) workspaces, LLM judges use models hosted in the EU. All other regions use models hosted in the US.
- Disabling Partner-powered AI features prevents the LLM judge from calling partner-powered models. You can still use LLM judges by providing your own model.
- LLM judges are intended to help customers evaluate their GenAI agents/applications, and LLM judge outputs should not be used to train, improve, or fine-tune an LLM.