On-demand feature computation
In Databricks, on-demand features are computed at inference time using Python user-defined functions (UDFs). Use them when feature values are not known ahead of time and depend on request-time inputs.
To use on-demand features, your workspace must be enabled for Unity Catalog and you must use Databricks Runtime 13.3 LTS ML or above.
What are on-demand features?
“On-demand” refers to features whose values are not known ahead of time, but are calculated at the time of inference. In Databricks, you use Python user-defined functions (UDFs) to specify how to calculate on-demand features. These functions are governed by Unity Catalog and discoverable through Catalog Explorer.
Workflow
To compute features on-demand, you specify a Python user-defined function (UDF) that describes how to calculate the feature values.
- During training, you provide this function and its input bindings in the
feature_lookupsparameter of thecreate_training_setAPI. - You must log the trained model using the Feature Store method
log_model. This ensures that the model automatically evaluates on-demand features when it is used for inference. - For batch scoring, the
score_batchAPI automatically calculates and returns all feature values, including on-demand features. - When you serve a model with Model Serving, the model automatically uses the Python UDF to compute on-demand features for each scoring request.
Create a Python UDF
You can create a Python UDF using SQL or Python code. The following examples create a Python UDF in the catalog main and schema default.
- Python
- Databricks SQL
To use Python, you must first install the databricks-sdk[openai] package. Use %pip install as follows:
%pip install unitycatalog-ai[databricks]
dbutils.library.restartPython()
Then, use code similar to the following to create a Python UDF:
from unitycatalog.ai.core.databricks import DatabricksFunctionClient
client = DatabricksFunctionClient()
CATALOG = "main"
SCHEMA = "default"
def add_numbers(number_1: float, number_2: float) -> float:
"""
A function that accepts two floating point numbers, adds them,
and returns the resulting sum as a float.
Args:
number_1 (float): The first of the two numbers to add.
number_2 (float): The second of the two numbers to add.
Returns:
float: The sum of the two input numbers.
"""
return number_1 + number_2
function_info = client.create_python_function(
func=add_numbers,
catalog=CATALOG,
schema=SCHEMA,
replace=True
)
The following code shows how to use Databricks SQL to create a Python UDF:
%sql
CREATE OR REPLACE FUNCTION main.default.add_numbers(x INT, y INT)
RETURNS INT
LANGUAGE PYTHON
COMMENT 'add two numbers'
AS $$
def add_numbers(n1: int, n2: int) -> int:
return n1 + n2
return add_numbers(x, y)
$$
After running the code, you can navigate through the three-level namespace in Catalog Explorer to view the function definition:
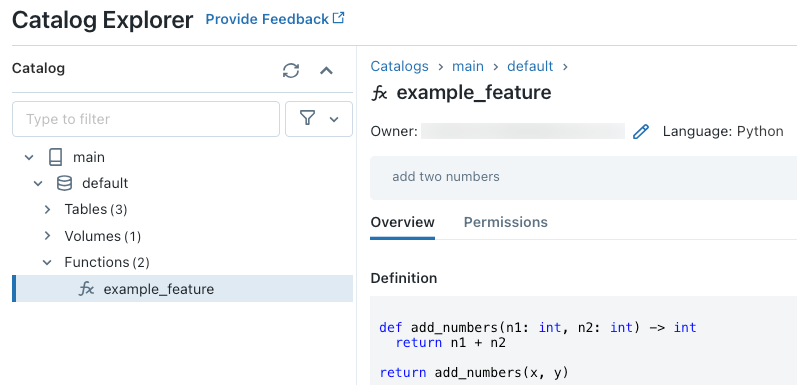
For more details about creating Python UDFs, see Register a Python UDF to Unity Catalog and the SQL language manual.
How to handle missing feature values
When a Python UDF depends on the result of a FeatureLookup, the value returned if the requested lookup key is not found depends on the environment. When using score_batch, the value returned is None. When using online serving, the value returned is float("nan").
The following code is an example of how to handle both cases.
%sql
CREATE OR REPLACE FUNCTION square(x INT)
RETURNS INT
LANGUAGE PYTHON AS
$$
import numpy as np
if x is None or np.isnan(x):
return 0
return x * x
$$
Train a model using on-demand features
To train the model, you use a FeatureFunction, which is passed to the create_training_set API in the feature_lookups parameter.
The following example code uses the Python UDF main.default.example_feature that was defined in the previous section.
# Install databricks-feature-engineering first with:
# %pip install databricks-feature-engineering
# dbutils.library.restartPython()
from databricks.feature_engineering import FeatureEngineeringClient
from databricks.feature_engineering import FeatureFunction, FeatureLookup
from sklearn import linear_model
fe = FeatureEngineeringClient()
features = [
# The feature 'on_demand_feature' is computed as the sum of the input value 'new_source_input'
# and the pre-materialized feature 'materialized_feature_value'.
# - 'new_source_input' must be included in base_df and also provided at inference time.
# - For batch inference, it must be included in the DataFrame passed to 'FeatureEngineeringClient.score_batch'.
# - For real-time inference, it must be included in the request.
# - 'materialized_feature_value' is looked up from a feature table.
FeatureFunction(
udf_name="main.default.example_feature", # UDF must be in Unity Catalog so uses a three-level namespace
input_bindings={
"x": "new_source_input",
"y": "materialized_feature_value"
},
output_name="on_demand_feature",
),
# retrieve the prematerialized feature
FeatureLookup(
table_name = 'main.default.table',
feature_names = ['materialized_feature_value'],
lookup_key = 'id'
)
]
# base_df includes the columns 'id', 'new_source_input', and 'label'
training_set = fe.create_training_set(
df=base_df,
feature_lookups=features,
label='label',
exclude_columns=['id', 'new_source_input', 'materialized_feature_value'] # drop the columns not used for training
)
# The training set contains the columns 'on_demand_feature' and 'label'.
training_df = training_set.load_df().toPandas()
# training_df columns ['materialized_feature_value', 'label']
X_train = training_df.drop(['label'], axis=1)
y_train = training_df.label
model = linear_model.LinearRegression().fit(X_train, y_train)
Specify default values
To specify default values for features, use the default_values parameter in the FeatureLookup.
FeatureLookup(
table_name = 'main.default.table',
feature_names = ['materialized_feature_value'],
lookup_key = 'id',
default_values={
"materialized_feature_value": 0
}
)
If the feature columns are renamed using the rename_outputs parameter, default_values must use the renamed feature names.
FeatureLookup(
table_name = 'main.default.table',
feature_names = ['materialized_feature_value'],
lookup_key = 'id',
rename_outputs={"materialized_feature_value": "feature_value"},
default_values={
"feature_value": 0
}
)
Log the model and register it to Unity Catalog
Models packaged with feature metadata can be registered to Unity Catalog. The feature tables used to create the model must be stored in Unity Catalog.
To ensure that the model automatically evaluates on-demand features when it is used for inference, you must set the registry URI and then log the model, as follows:
import mlflow
mlflow.set_registry_uri("databricks-uc")
fe.log_model(
model=model,
artifact_path="main.default.model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name="main.default.recommender_model"
)
If the Python UDF that defines the on-demand features imports any Python packages, you must specify these packages using the argument extra_pip_requirements. For example:
import mlflow
mlflow.set_registry_uri("databricks-uc")
fe.log_model(
model=model,
artifact_path="model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name="main.default.recommender_model",
extra_pip_requirements=["scikit-learn==1.20.3"]
)
Limitations
- For Feature Serving endpoints, all data types supported by Feature Store are supported as feature function output types, except
ArrayType,MapType, andStructType.StructTypeis also not supported as a feature function input type. - For
databricks-feature-engineeringversions below 0.14.0, the following Unity Catalog permissions are required to use a user-defined function (UDF) to create training set or to create a Feature Serving endpoint.USE CATALOGprivilege on thesystemcatalogUSE SCHEMAprivilege on thesystem.information_schemaschema
Notebook examples: On-demand features
The following notebook shows an example of how to train and score a model that uses an on-demand feature.
Basic on-demand features demo notebook
The following notebook shows an example of a restaurant recommendation model. The restaurant's location is looked up from a Databricks online table. The user's current location is sent as part of the scoring request. The model uses an on-demand feature to compute the real-time distance from the user to the restaurant. That distance is then used as an input to the model.