Cálculo de recursos sob demanda
No Databricks, recursos sob demanda são computados no tempo de inferência usando funções definidas pelo usuário (UDFs) Python. Use-os quando os valores de recurso não são conhecidos antecipadamente e dependem de entradas no momento da solicitação.
Para usar o recurso on-demand, seu workspace deve estar habilitado para Unity Catalog e o senhor deve usar Databricks Runtime 13.3 LTS ML ou acima.
O que é recurso on-demand?
"On-demand" refere-se a recursos cujos valores não são conhecidos antecipadamente, mas são calculados no momento da inferência. No site Databricks, o usuário utiliza as funções definidas pelo usuário (UDFs) do sitePython para especificar como calcular o recurso on-demand. Essas funções são controladas pelo Unity Catalog e podem ser descobertas por meio do Catalog Explorer.
fluxo de trabalho
Para compute recurso on-demand, o senhor especifica uma função definida pelo usuário Python (UDF) que descreve como calcular os valores do recurso.
- Durante o treinamento, o senhor fornece essa função e seus vínculos de entrada no parâmetro
feature_lookupsda APIcreate_training_set. - O senhor deve log o modelo treinado usando o método Recurso Store
log_model. Isso garante que o modelo avalie automaticamente o recurso on-demand quando for usado para inferência. - Para a pontuação de lotes, o
score_batchAPI calcula e retorna automaticamente todos os valores de recurso, inclusive o recurso on-demand. - Ao disponibilizar um modelo com o método `serving modelo`, o modelo utiliza automaticamente a UDF Python para compute recursos sob demanda para cada solicitação de pontuação.
Criar uma UDF Python
O senhor pode criar um UDF Python usando código SQL ou Python. Os exemplos a seguir criam um UDF Python no catálogo main e no esquema default.
- Python
- Databricks SQL
Para usar o Python, o senhor deve primeiro instalar o pacote databricks-sdk[openai]. Use %pip install da seguinte forma:
%pip install unitycatalog-ai[databricks]
dbutils.library.restartPython()
Em seguida, use um código semelhante ao seguinte para criar um Python UDF:
from unitycatalog.ai.core.databricks import DatabricksFunctionClient
client = DatabricksFunctionClient()
CATALOG = "main"
SCHEMA = "default"
def add_numbers(number_1: float, number_2: float) -> float:
"""
A function that accepts two floating point numbers, adds them,
and returns the resulting sum as a float.
Args:
number_1 (float): The first of the two numbers to add.
number_2 (float): The second of the two numbers to add.
Returns:
float: The sum of the two input numbers.
"""
return number_1 + number_2
function_info = client.create_python_function(
func=add_numbers,
catalog=CATALOG,
schema=SCHEMA,
replace=True
)
O código a seguir mostra como usar o Databricks SQL para criar um UDF Python:
%sql
CREATE OR REPLACE FUNCTION main.default.add_numbers(x INT, y INT)
RETURNS INT
LANGUAGE PYTHON
COMMENT 'add two numbers'
AS $$
def add_numbers(n1: int, n2: int) -> int:
return n1 + n2
return add_numbers(x, y)
$$
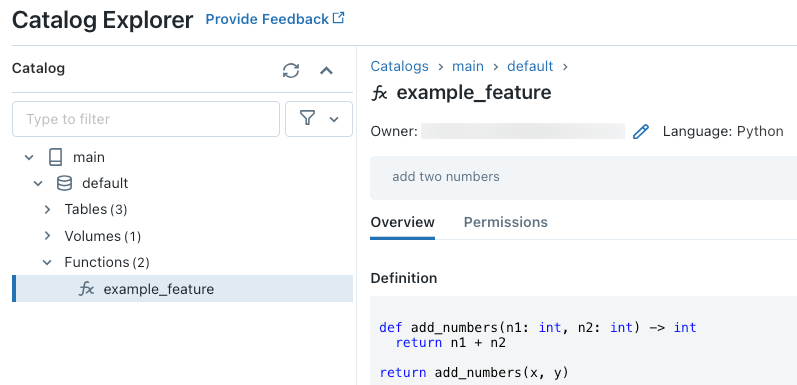
Depois de executar o código, o senhor pode navegar pelo namespace de três níveis no Catalog Explorer para view a definição da função:
Para obter mais detalhes sobre a criação de UDFs em Python, consulte o registro em Python UDF a Unity Catalog e o manual da linguagem SQL.
Como lidar com valores de recurso ausentes
Quando um Python UDF depende do resultado de um FeatureLookup, o valor retornado se a pesquisa solicitada key não for encontrada depende do ambiente. Ao usar score_batch, o valor retornado é None. Ao usar o serviço on-line, o valor retornado é float("nan").
O código a seguir é um exemplo de como lidar com os dois casos.
%sql
CREATE OR REPLACE FUNCTION square(x INT)
RETURNS INT
LANGUAGE PYTHON AS
$$
import numpy as np
if x is None or np.isnan(x):
return 0
return x * x
$$
Treinar um modelo usando recurso on-demand
Para treinar o modelo, o senhor usa um FeatureFunction, que é passado para a API create_training_set no parâmetro feature_lookups.
O código de exemplo a seguir usa o Python UDF main.default.example_feature que foi definido na seção anterior.
# Install databricks-feature-engineering first with:
# %pip install databricks-feature-engineering
# dbutils.library.restartPython()
from databricks.feature_engineering import FeatureEngineeringClient
from databricks.feature_engineering import FeatureFunction, FeatureLookup
from sklearn import linear_model
fe = FeatureEngineeringClient()
features = [
# The feature 'on_demand_feature' is computed as the sum of the input value 'new_source_input'
# and the pre-materialized feature 'materialized_feature_value'.
# - 'new_source_input' must be included in base_df and also provided at inference time.
# - For batch inference, it must be included in the DataFrame passed to 'FeatureEngineeringClient.score_batch'.
# - For real-time inference, it must be included in the request.
# - 'materialized_feature_value' is looked up from a feature table.
FeatureFunction(
udf_name="main.default.example_feature", # UDF must be in Unity Catalog so uses a three-level namespace
input_bindings={
"x": "new_source_input",
"y": "materialized_feature_value"
},
output_name="on_demand_feature",
),
# retrieve the prematerialized feature
FeatureLookup(
table_name = 'main.default.table',
feature_names = ['materialized_feature_value'],
lookup_key = 'id'
)
]
# base_df includes the columns 'id', 'new_source_input', and 'label'
training_set = fe.create_training_set(
df=base_df,
feature_lookups=features,
label='label',
exclude_columns=['id', 'new_source_input', 'materialized_feature_value'] # drop the columns not used for training
)
# The training set contains the columns 'on_demand_feature' and 'label'.
training_df = training_set.load_df().toPandas()
# training_df columns ['materialized_feature_value', 'label']
X_train = training_df.drop(['label'], axis=1)
y_train = training_df.label
model = linear_model.LinearRegression().fit(X_train, y_train)
Especifique os valores d default
Para especificar valores de default para recurso, utilize o parâmetro default_values em FeatureLookup.
FeatureLookup(
table_name = 'main.default.table',
feature_names = ['materialized_feature_value'],
lookup_key = 'id',
default_values={
"materialized_feature_value": 0
}
)
Se as colunas de recurso forem renomeadas usando o parâmetro " rename_outputs ", o comando " default_values " deverá utilizar os nomes renomeados dos recursos.
FeatureLookup(
table_name = 'main.default.table',
feature_names = ['materialized_feature_value'],
lookup_key = 'id',
rename_outputs={"materialized_feature_value": "feature_value"},
default_values={
"feature_value": 0
}
)
registre o modelo e registre-o no Unity Catalog
Os modelos de pacote com metadados de recurso podem ser registrados em Unity Catalog. As tabelas de recurso usadas para criar o modelo devem ser armazenadas em Unity Catalog.
Para garantir que o modelo avalie automaticamente o recurso on-demand quando for usado para inferência, o senhor deve definir o URI do registro e, em seguida, log o modelo, como segue:
import mlflow
mlflow.set_registry_uri("databricks-uc")
fe.log_model(
model=model,
artifact_path="main.default.model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name="main.default.recommender_model"
)
Se o Python UDF que define o recurso on-demand importar qualquer Python pacote, o senhor deverá especificar esse pacote usando o argumento extra_pip_requirements. Por exemplo:
import mlflow
mlflow.set_registry_uri("databricks-uc")
fe.log_model(
model=model,
artifact_path="model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name="main.default.recommender_model",
extra_pip_requirements=["scikit-learn==1.20.3"]
)
Limitações
- Para endpoints de Feature Serving, todos os tipos de dados compatíveis com Feature Store são compatíveis como tipos de saída de função de recurso, exceto
ArrayType,MapTypeeStructType.StructTypetambém não é compatível como um tipo de entrada de função de recurso. - Para versões
databricks-feature-engineeringanteriores a 0.14.0, as seguintes permissões Unity Catalog são necessárias para usar uma função definida pelo usuário (UDF) para criar um conjunto de treinamento ou para criar um endpointFeature Serving.USE CATALOGprivilégio no catálogosystemUSE SCHEMAprivilégio no esquemasystem.information_schema
Notebook exemplos: Recurso sob demanda
O Notebook a seguir mostra um exemplo de como treinar e pontuar um modelo que usa um recurso on-demand.
Demonstração básica do recurso on-demand Notebook
O Notebook a seguir mostra um exemplo de um modelo de recomendação de restaurante. A localização do restaurante é pesquisada em uma tabela on-line do Databricks. A localização atual do usuário é enviada como parte da solicitação de pontuação. O modelo usa um recurso sob demanda para compute o tempo real de distância do usuário até o restaurante. Essa distância é então usada como entrada para o modelo.