Configure compute for jobs
Configure serverless or classic compute for the tasks in a Lakeflow Job, and choose the right type for each task.
Limitations for serverless compute for jobs include the following:
- Continuous scheduling is supported only with bounded Structured Streaming triggers such as
Trigger.AvailableNow. See Run jobs continuously. - No support for default or time-based interval triggers in Structured Streaming.
For more limitations, see Serverless compute limitations.
Each job can have one or more tasks. You define compute resources for each task. Multiple tasks defined for the same job can use the same compute resource.
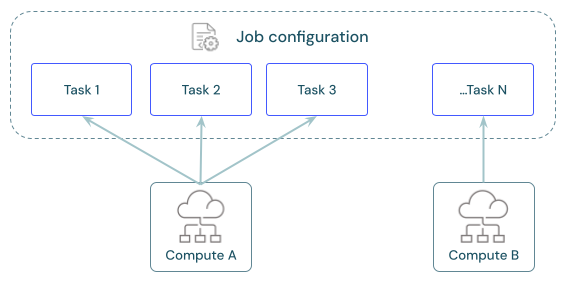
Recommended compute for each task
The following table indicates the recommended and supported compute types for each task type.
Serverless compute for jobs has limitations and does not support all workloads. See Serverless compute limitations.
Task | Recommended compute | Supported compute |
|---|---|---|
Notebooks | Serverless jobs | Serverless jobs, classic jobs, classic all-purpose |
Python script | Serverless jobs | Serverless jobs, classic jobs, classic all-purpose |
Python wheel | Serverless jobs | Serverless jobs, classic jobs, classic all-purpose |
SQL | Serverless SQL warehouse | Serverless SQL warehouse, pro SQL warehouse |
Lakeflow pipelines | Serverless pipeline | Serverless pipeline, classic pipeline |
dbt | Serverless SQL warehouse | Serverless SQL warehouse, pro SQL warehouse |
dbt CLI commands | Serverless jobs | Serverless jobs, classic jobs, classic all-purpose |
JAR | Classic jobs | Classic jobs, classic all-purpose |
Spark Submit | Classic jobs | Classic jobs |
Pricing for Lakeflow Jobs is tied to the compute used to run tasks. For more details, see Databricks pricing.
Configure compute for jobs
Classic jobs compute is configured directly from the Lakeflow Jobs UI, and these configurations are part of the job definition. All other available compute types store their configurations with other workspace assets. The following table has more details:
Compute type | Details |
|---|---|
Classic jobs compute | You configure compute for classic jobs using the same UI and settings available for all-purpose compute. See Compute configuration reference. |
Serverless compute for jobs | Serverless compute for jobs is the default for all tasks that support it. Databricks manages compute settings for serverless compute. See Run your Lakeflow Jobs with serverless compute for workflows. |
SQL warehouses | Serverless and pro SQL warehouses are configured by workspace admins or users with unrestricted cluster creation privileges. You configure tasks to run against existing SQL warehouses. See Connect to a SQL warehouse. |
Lakeflow pipelines compute | You configure compute settings for Lakeflow pipelines during pipeline configuration. See Configure classic compute for pipelines. Databricks manages compute resources for serverless Lakeflow pipelines. See Configure a serverless pipeline. |
All-purpose compute | You can optionally configure tasks using classic all-purpose compute. Databricks does not recommend this configuration for production jobs. See Compute configuration reference and Limited exceptions. |
Share compute across tasks
Configure tasks to use the same jobs compute resources to optimize resource usage with jobs that orchestrate multiple tasks. Sharing compute across tasks can reduce latency associated with start-up times.
You can use a single job compute resource to run all tasks that are part of the job or multiple job resources optimized for specific workloads. Any job compute configured as part of a job is available for all other tasks in the job.
The following table highlights differences between job compute configured for a single task and job compute shared between tasks:
Single task | Shared across tasks | |
|---|---|---|
Start | When the task run begins. | When the first task run configured to use the compute resource begins. |
Terminate | After the task runs. | After the final task configured to use the compute resource runs. |
Idle compute | Not applicable. | Compute remains on and idle while tasks not using the compute resource run. |
A shared job cluster is scoped to a single job run and cannot be used by other jobs or runs of the same job.
Libraries cannot be declared in a shared job cluster configuration. You must add dependent libraries in task settings.
Shared driver state across tasks
When multiple tasks share a jobs compute resource, the tasks run on the same driver JVM. Class state and singletons persist across tasks for the duration of the job run. For most workloads this is transparent, but be aware of the following implications:
- Scala singletons and companion objects are shared across tasks. Mutable state in a Scala companion object persists between tasks that run on the same shared cluster. If parallel tasks read from or write to the same companion-object variable, one task's value can overwrite another's. For a working example, see the Knowledge Base article Multi-task workflows using incorrect parameter values.
- Libraries loaded by one task remain available to subsequent tasks for the duration of the job run.
If your code requires task-level isolation, use one of the following approaches:
- Configure each task to use a separate jobs compute resource.
- Add explicit task dependencies so the tasks run sequentially rather than in parallel.
- Refactor the code to avoid relying on singleton or shared mutable state. For example, pass parameters explicitly to each function instead of reading them from a companion object.
Review, configure, and swap jobs compute
The Compute section in the Job details pane lists all compute configured for tasks in the current job.
Tasks configured to use a compute resource are highlighted in the task graph when you hover over the compute specification.
Use the Swap button to change the compute for all tasks associated with a compute resource.
Classic jobs compute resources have a Configure option. Other compute resources give you options to view and modify compute configuration details.
Additional resources
For additional details on configuring Databricks classic jobs, see Configure classic compute for Lakeflow Jobs.