Troubleshoot Salesforce ingestion
This page describes common issues with the Salesforce ingestion connector in Databricks Lakeflow Connect and how to resolve them.
General pipeline troubleshooting
If a pipeline fails while executing, click on the step that failed and confirm whether the error message provides sufficient information about the nature of the error.
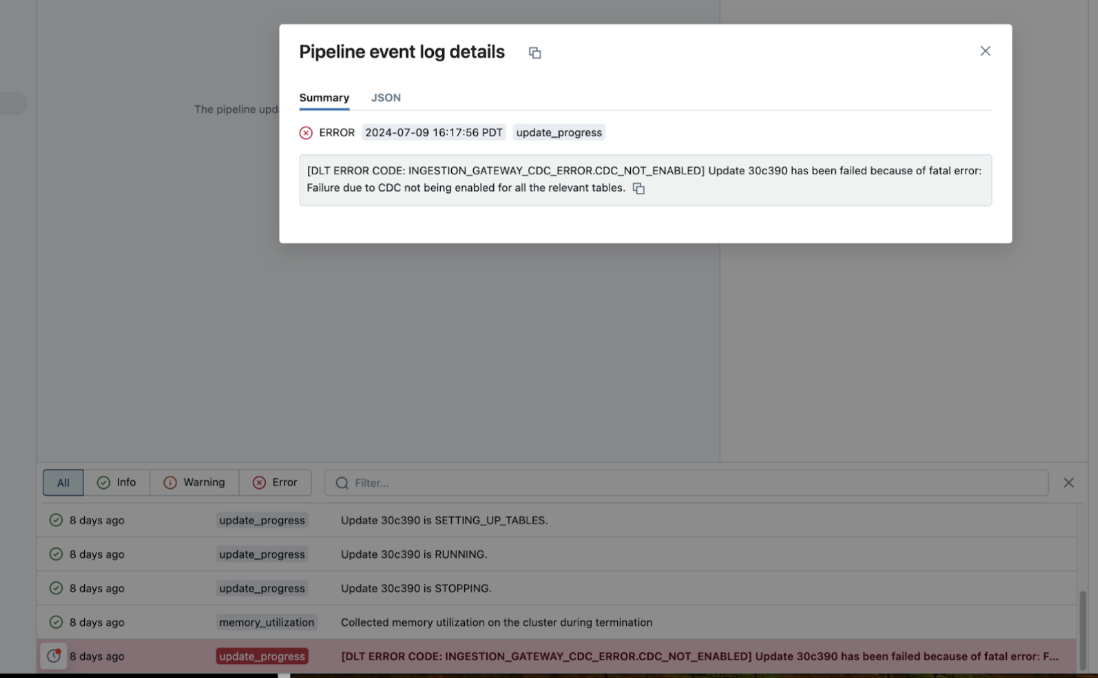
You can also check and download the cluster logs from the pipeline details page by clicking Update details in the right-hand panel, then Logs. Scan the logs for errors or exceptions.
Column selection using Declarative Automation Bundles
Issue:
You're unable to use the column selection feature when you create a managed ingestion pipeline using Declarative Automation Bundles.
Resolution:
Check your Databricks CLI version. If the version is below v0.251.0, reinstall the CLI.
Network connectivity and DNS resolution failures
Error:
java.net.UnknownHostException: salesforce.com
or
Failed to connect to Salesforce: Connection refused
Cause:
These errors typically indicate that network policies are preventing the connector from resolving or reaching Salesforce domains. This commonly occurs when using serverless egress control without proper allowlist configuration.
Resolution:
Add salesforce.com to your network policy allowlist. For more information, see Manage network policies for serverless egress control.
Firewalls and virtual network settings block access to storage services
Firewalls and virtual networks' settings may be blocking access to storage services. Please verify your Azure storage credentials or firewall exception settings
This issue stems from your networking settings. To troubleshoot, try the following:
LIMIT_EXCEEDED
[SAAS_CONNECTOR_SOURCE_API_ERROR] An error occurred in the Salesforce API call. Source API type: CREATE_BULK_QUERY_JOB. Error code: LIMIT_EXCEEDED.
Try refreshing the destination table. If the issue persists, please file a ticket.
This occurs when you hit an API limit in your Salesforce account. As a first step, wait for your API limits to reset, then refresh your destination table. If the issue persists, file a ticket. You can limit the prevalence of this error by reducing your schedule or ingestion volume.
INVALID_USER
[SAAS_CONNECTOR_SOURCE_API_ERROR] An error occurred in the Salesforce API call. Source API type: CREATE_BULK_QUERY_JOB. Error code: INVALID_USER.
Try refreshing the destination table. If the issue persists, please file a ticket.
Salesforce's developer documentation indicates that this error can happen for two reasons:
- The user running the ingestion pipeline doesn't have the correct permissions
- The job was created by a different user than the user that's currently running it
Therefore, you can troubleshoot as follows:
- Validate that the credentials in your connection remain correct. This can be resolved by fixing the credentials.
- Confirm whether the user may have changed since you first started using the connection. This can be resolved by fully refreshing the pipeline.
If the issue persists, file a support ticket.
STREAM_FAILED
STREAM_FAILED: Terminated with exception: Ingestion for object XYZ is incomplete because the Salesforce API query job took too long, failed, or was manually cancelled. To try again, you can either re-run the entire pipeline or refresh this specific destination table. If the error persists, file a ticket. SQLSTATE: XXKST
When the connector is ingesting from Salesforce, the Salesforce query can return an error. This happens for a variety of reasons (for example, it takes too long, it fails, or it's manually canceled).
This error can be transient, so we recommend that you start by retrying the pipeline or refreshing the specific destination table. If this doesn't resolve the issue, file a support ticket.
The destination table has fewer rows than the source table
The destination table has fewer rows than the source table.
The connector aims to ingest all unique rows from the source table.
First, validate that the connection has access to all rows in the table. From there, confirm whether there are any duplicate rows in the source table; these are not ingested. If neither of these issues is the root cause, file a support ticket.
A table can only be owned by one pipeline
ExtendedAnalysisException: Table XYZ is already managed by pipeline ABC. A table can only be owned by one pipeline. Concurrent pipeline operations such as maintenance full refresh with conflict with each other. Please rename the table XYZ to proceed.
Each destination table maps to a single ingestion pipeline. If you attempt to create a pipeline that writes a table named "XYZ" to a destination schema that already contains a table named "XYZ," then the pipeline will fail. You can write it to a different destination schema.
Null values in a newly added column
You might see new columns in your table for one of several reasons:
- A new column was added to the table.
- The column has always existed in the table, but the user only recently gained access to it.
- The column has always existed in the source but was previously excluded from ingestion, but the user recently included it.
This issue happens in the second scenario. For any row that has already been ingested, the data will be NULL in the new column. To backfill this data, run a full refresh of the table.
(In the first scenario, the column is fully backfilled. In the third scenario, the pipeline fails after you make this change; you can run a full refresh to reset the data and continue running the pipeline.)
Table or column is missing
You might not be able to find a Salesforce object or column for the following reasons:
- You don't have sufficient Salesforce permissions to access the object or column.
- The missing column represents:
- A compound Salesforce object field (for example: address, location)
- A base64 binary field
- The table name in Salesforce is different from the table name that you provided. The object name is case-sensitive and customer objects have a
__csuffix.
Failed to create a Salesforce connection using OAuth
If you see errors when you try to create a connection to Salesforce using OAuth (for example, "invalid grant of token"):
- Confirm that the OAuth credentials are correct.
- If you're trying to connect to a sandbox instance in Salesforce, confirm that you've selected Is Sandbox.
Salesforce bulk query job failure
When you ingest large volumes of data from Salesforce, the connector sends bulk query jobs to the Salesforce server to retrieve the data. You might receive an error like the following:
Ingestion for object `<object-name>` is incomplete because the Salesforce API query job took too long, failed, or was manually canceled. To try again, you can either re-run the entire pipeline or refresh this specific destination table. If the error persists, file a ticket. Job ID: 750TU00000DEdbWYAT. Job status: <Failed|Aborted|NOT_FOUND>.
In this example, the bulk query job failed, was canceled, or was deleted on the Salesforce side. To investigate why the query failed, you can visit the Bulk Data Load Jobs page in the Salesforce UI:
https://<your-url>/lightning/setup/AsyncApiJobStatus/home
Retrying the pipeline might fix the issue.
Connector ingests fewer rows than expected
Confirm that you have access to all rows in the object.
Why do I have null values in a new column?
You might see null values in a new column when:
- You run the pipeline with the original version of the table.
- The column is added in the data source.
- You run the pipeline on a new version of the table, including the new column.
If new columns are automatically added after the initial load because of Databricks column selection or source updates, the connector backfills rows from earlier cursor values. However, if you receive access to a new column, the connector does not backfill.
To resolve this, run a full refresh of the table.
invalid_grant, expired access/refresh token
This error happens in the following scenarios:
- You have more than four connections for the authenticating Salesforce user. Confirm that the authenticating user doesn't exceed the connection limit.
- Your Salesforce instance restricts connected app access. Add the Databricks connected app to your allowlist.
- You revoked the connected app's access in the Salesforce UI.
- Salesforce detected abnormal activity and invalidated the refresh token.
- The connected app refresh token expired.
To resolve this issue, edit and reauthorize the connection. If the issue persists, file a support ticket.
Formula field values show as NULL (incremental ingestion)
When you use incremental formula field ingestion, you might see NULL values for some formula fields. This occurs when a formula uses unsupported functions or operations. To diagnose, query the error tracking table.
-
To see which formula fields are unsupported for a specific object, for example the
Accountobject:SQLSELECT * FROM <pipeline-id>_formula_fields_error_reasons
WHERE object_name = 'Account'To see all unsupported formula fields across all objects:
SQLSELECT object_name, formula_field_name, error_message
FROM <pipeline-id>_formula_fields_error_reasons
ORDER BY object_name, formula_field_name -
Review the list of unsupported formula functions in Limitations.
If a formula is unsupported, the field will always show NULL values in the destination table. To ingest an unsupported field, use the default snapshot approach. Do not enable incremental formula field ingestion for the pipeline.
Pipeline fails with decimal precision error (formula fields)
Error:
Pipeline failed: Formula field exceeds maximum decimal precision (38, 18)
This occurs when a formula field computes a value that exceeds Databricks' decimal precision limit. Formula fields with values exceeding decimal(38,18) cannot be ingested incrementally.
Resolution:
Disable incremental formula field ingestion for this pipeline, or exclude the problematic formula field using the exclude_columns configuration. See Select columns to ingest.
Error in Salesforce authentication
Error:
We can't authorize you because of an OAuth error. For more information, contact your Salesforce administrator. OAUTH_APPROVAL_ERROR_GENERIC: An unexpected error has occurred during authentication. Please try again.
Cause:
This is likely due to changes that Salesforce made to their connected app requirements. Historically, it was sufficient to consent as part of the authentication process. In September 2025, however, Salesforce began restricting the use of uninstalled connected apps.
Solution:
If you don't have the required permissions for a successful first-time authentication, an admin must install the Databricks connected app in your Salesforce instance when you create or reauthorize a connection. See Create a Salesforce connection.