ワークスペースでのバンドルの作成
宣言型自動化バンドルは、ワークスペース内で直接作成および変更できます。
ワークスペースでバンドルを使用するための要件については、ワークスペース要件の「宣言型自動化バンドル」を参照してください。
バンドルに関する詳細については、 「宣言型自動化バンドルとは?」を参照してください。
バンドルを作成する
Databricks ワークスペースにバンドルを作成するには:
-
バンドルを作成するGitフォルダに移動します。
-
「作成」 ボタンをクリックし、次に 「バンドル」 をクリックします。または、ワークスペースツリー内の Git フォルダーまたはそれに関連付けられたケバブを右クリックし、 [作成] > [バンドル] をクリックします。
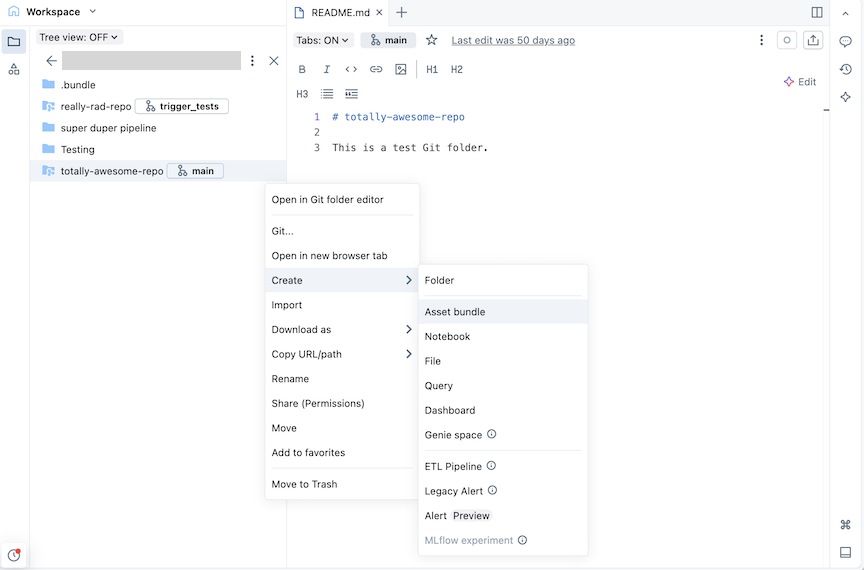
-
「バンドルの作成」 ダイアログで、バンドルに 「totally-awesome-bundle」 などの名前を付けます。バンドル名には、文字、数字、ハイフン、アンダースコアのみを使用できます。
-
「 テンプレート 」で、カスタムテンプレートを使用してバンドル、空のバンドル、サンプルPythonノートブックを実行するバンドル、またはSQLを実行するバンドルを作成するかを選択します。Lakeflow Pipelines Editorが有効になっている場合は、ETLパイプラインプロジェクトを作成するオプションも表示されます。ワークスペースで設定されたカスタムテンプレートも利用可能になります。
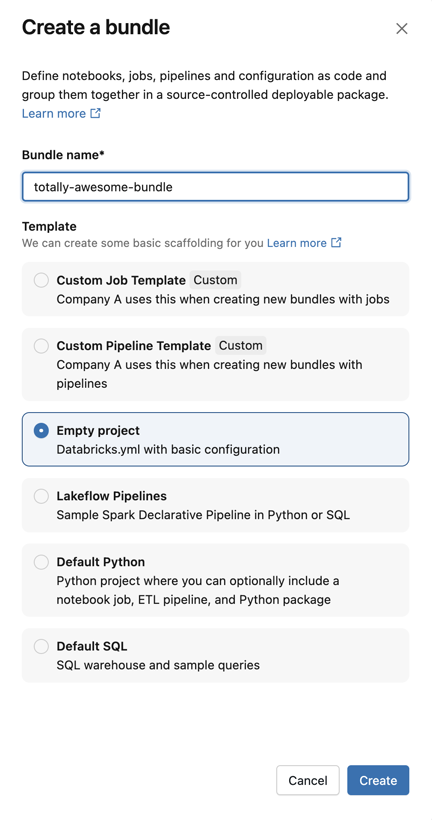
-
一部のテンプレートには追加の設定が必要です。[ 次へ ] をクリックして、プロジェクトの構成を完了します。
テンプレート | 構成オプション |
|---|---|
Lakeflowパイプライン |
|
デフォルトのPython |
|
デフォルト SQL |
|
- [ 作成とデプロイ ] をクリックします。
これにより、Git フォルダー内に初期バンドルが作成されます。このバンドルには、選択したプロジェクト テンプレートのファイル、 .gitignore Git 設定ファイル、および必要な Declarative Automation Bundles databricks.ymlファイルが含まれます。databricks.ymlファイルには、バンドルの主要な設定が含まれています。詳細については、 「宣言型自動化バンドルの構成」を参照してください。
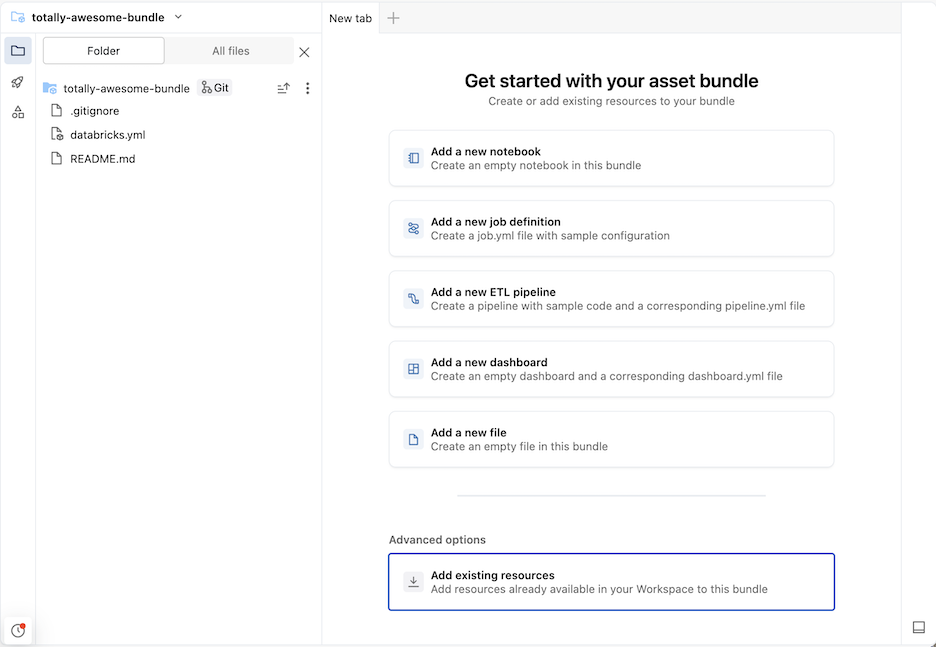
バンドル内のファイルに加えられた変更は、Git フォルダに関連付けられたリモートリポジトリと同期できます。Git フォルダーには、多数のバンドルを含めることができます。
バンドルに新しいファイルを追加する
バンドルには、デプロイメントとワークスペース構成を定義する databricks.yml ファイル、ノートブック、Python ファイル、テスト ファイルなどのソース ファイル、Lakeflow Jobs や Lakeflow Pipelines などの Databricks リソースの定義と設定が含まれます。他のワークスペースフォルダと同様に、バンドルに新しいファイルを追加できます。
バンドル ビューの新しいタブを開いてバンドル ファイルを変更するには、ワークスペース内のバンドル フォルダーに移動し、バンドル名の右側にある エディターで開く をクリックします。
ソースコードファイルの追加
ワークスペース UI で新しいノートブックまたはその他のファイルをバンドルに追加するには、バンドル フォルダーに移動し、次の操作を行います。
- 右上の 作成 をクリックし、バンドルに追加するファイル タイプとして [ノートブック]、[ファイル]、[クエリ]、[ダッシュボード] のいずれかを選択します。
- または、[ 共有 ] の左側にあるケバブをクリックして、ファイルをインポートします。
ファイルをバンドル デプロイメントの一部にするには、バンドル フォルダにファイルを追加した後、そのファイルを databricks.yml バンドル設定に追加するか、そのファイルを含むジョブまたはパイプライン定義ファイルを作成する必要があります。バンドルへの既存のリソースの追加を参照してください。
リソース定義を作成する
バンドルには、デプロイメントに含めるジョブやパイプラインなどのリソースの定義が含まれています。バンドルがデプロイされると、バンドルで定義されたリソースがワークスペースに作成されます (すでにデプロイされている場合は更新されます)。これらの定義は YAML または Python で指定され、UI で直接これらの構成を作成および編集できます。
- 新しいリソースを定義するワークスペース内のバンドル フォルダーに移動します。
以前にワークスペースのエディターでバンドルを開いたことがある場合は、ワークスペース・ブラウザーのオーサリング・コンテキスト・リストを使用して、バンドル・フォルダーにナビゲートできます。オー サリングコンテキストを参照してください。
-
バンドル名の右側にある「 エディターで開く 」をクリックして、バンドル・エディター・ビューに移動します。
-
バンドルのデプロイメント・アイコンをクリックして、 デプロイメント パネルに切り替えます。
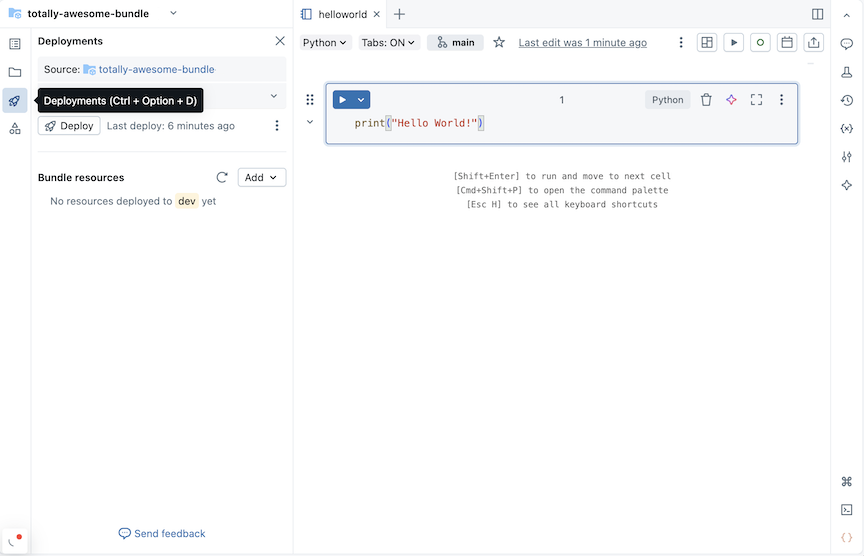
-
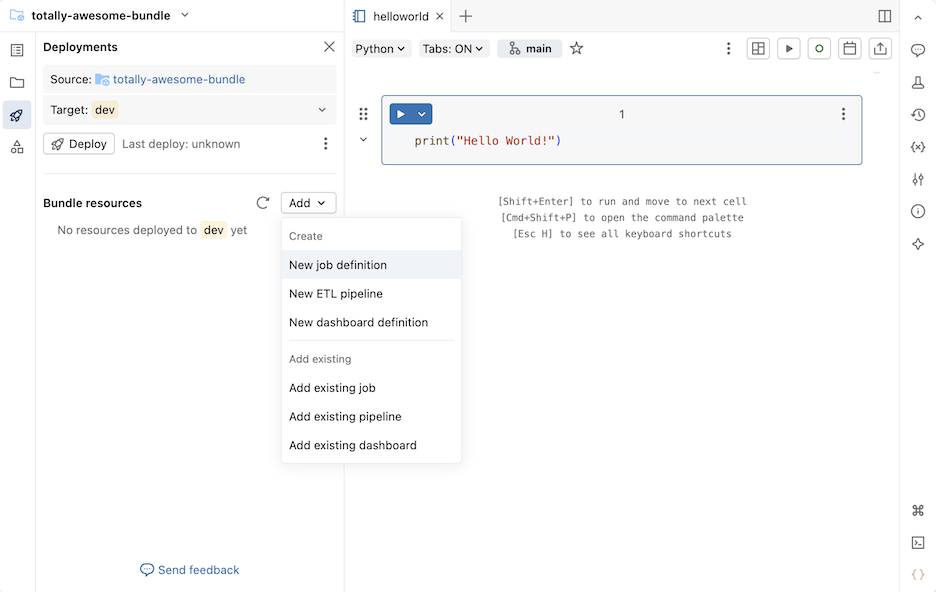
[バンドル リソース] セクションで、 [追加] をクリックし、作成するリソース定義を選択します。
新しいジョブ定義
ジョブを定義するバンドル設定ファイルを作成するには、次のようにします。
-
[デプロイメント] パネルの [バンドル リソース] セクションで、 [追加] をクリックし、 [新しいジョブ定義] を クリックします。
-
ジョブ定義の作成 ダイアログの ジョブ名 フィールドにジョブの名前を入力します。 作成 をクリックします。
-
作成されたジョブ定義ファイルに YAML を追加します。次の YAML の例では、ノートブックを実行するジョブを定義しています。
YAMLresources:
jobs:
run_notebook:
name: run-notebook
queue:
enabled: true
tasks:
- task_key: my-notebook-task
notebook_task:
notebook_path: ../helloworld.ipynb
YAML でのジョブの定義の詳細については、 「ジョブ」を参照してください。 サポートされている他のジョブ タスク タイプの YAML 構文については、 「宣言的オートメーション バンドルのジョブにタスクを追加する」を参照してください。
新しいパイプラインの定義
ワークスペースでLakeFlow Pipelines Editorを有効にしている場合は、 「新しいETLパイプライン」を参照してください。
バンドルにパイプライン定義を追加するには:
-
[デプロイメント] パネルの [バンドル リソース] セクションで、 [追加] をクリックし、 [新しいパイプライン定義] を クリックします。
-
[既存のバンドルにパイプラインを追加] ダイアログ の [パイプライン 名] フィールドにパイプライン の名前を入力します。
-
[追加してデプロイ]を クリックします。
ノートブックを実行するtest_pipelineという名前のパイプラインの場合、ファイルtest_pipeline.pipeline.ymlに次の YAML が作成されます。
resources:
pipelines:
test_pipeline:
name: test_pipeline
libraries:
- notebook:
path: ../test_pipeline.ipynb
serverless: true
catalog: main
target: test_pipeline_${bundle.environment}
既存のノートブックを実行するように構成を変更できます。YAML でのパイプラインの定義の詳細については、 「パイプライン」を参照してください。
新しいETLパイプライン
新しい ETL パイプライン定義を追加するには:
-
デプロイメント パネルの バンドル リソース セクションで、 [追加] をクリックし、 [新しい ETL パイプライン] を クリックします。
-
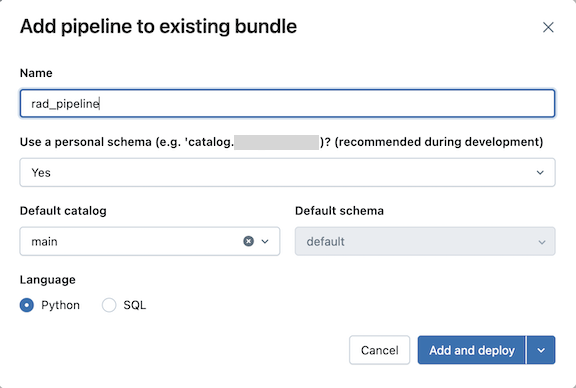
[既存のバンドルにパイプラインを追加] ダイアログ の [名前] フィールドにパイプラインの名前を入力します。名前はワークスペース内で一意である必要があります。
-
個人スキーマの使用 フィールドで、開発シナリオの場合は はい を選択し、本番運用シナリオの場合は いいえ を選択します。
-
パイプラインの デフォルトカタログ と デフォルトスキーマ を選択します。
-
パイプラインソースコードの言語を選択します。
-
[追加してデプロイ]を クリックします。
-
「Dev にデプロイ」 確認ダイアログで詳細を確認し、 「デプロイ」 をクリックします。
ETL パイプラインは、探索テーブルと変換テーブルの例を使用して作成されます。
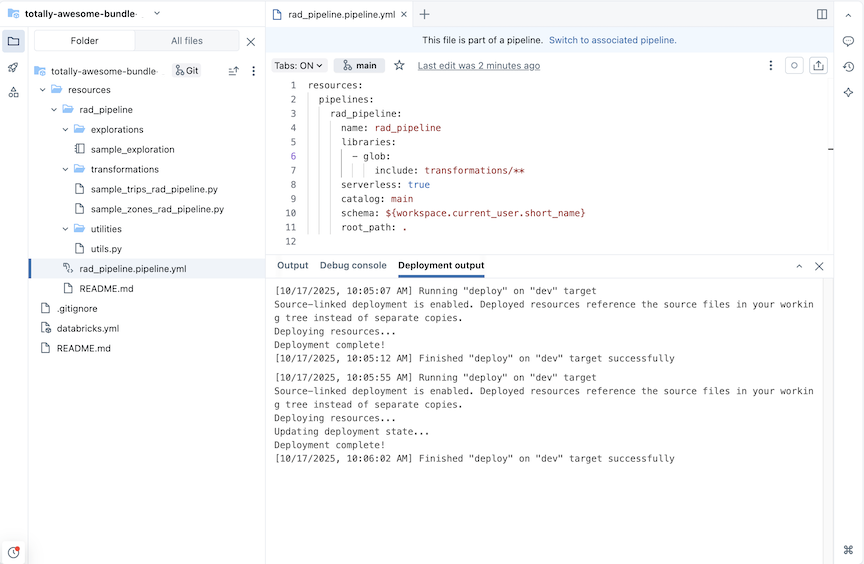
rad_pipelineという名前のパイプラインの場合、次の YAML がファイルrad_pipeline.pipeline.ymlに作成されます。このパイプラインはサーバレスコンピュート上で実行するように設定されています。 パイプライン構成のリファレンスについては、 「パイプライン」を参照してください。
resources:
pipelines:
rad_pipeline:
name: rad_pipeline
libraries:
- glob:
include: transformations/**
serverless: true
catalog: main
schema: ${workspace.current_user.short_name}
root_path: .
新しいダッシュボードの定義
ダッシュボードを定義するバンドル構成ファイルを作成するには:
-
[デプロイメント] パネルの [バンドル リソース] セクションで、 [追加] をクリックし、 [新しいダッシュボード定義] を クリックします。
-
「既存のバンドルにダッシュボードを追加」ダイアログ の 「ダッシュボード名」 フィールドにダッシュボードの名前を入力します。
-
ダッシュボードの ウェアハウス を選択します。 [追加してデプロイ] をクリックします。
新しい空のダッシュボードと構成*.dashboard.ymlファイルがバンドルに作成されます。ダッシュボードは、構成ファイルで指定されたウェアハウスに保存されます。
ダッシュボードの詳細については、 「ダッシュボード」を参照してください。ダッシュボード構成の YAML 構文については、 dashboard を参照してください。
既存のリソースをバンドルに追加する
ワークスペース UI を使用するか、バンドルにリソース構成を追加することによって、既存のリソースをバンドルに追加できます。
バンドルのワークスペース UI を使用する
既存のジョブ、パイプライン、またはダッシュボードをバンドルに追加するには:
- リソースを追加するワークスペース内のバンドル フォルダーに移動します。
以前にワークスペースのエディターでバンドルを開いたことがある場合は、ワークスペース・ブラウザーのオーサリング・コンテキスト・リストを使用して、バンドル・フォルダーにナビゲートできます。オー サリングコンテキストを参照してください。
-
バンドル名の右側にある「 エディターで開く 」をクリックして、バンドル・エディター・ビューに移動します。
-
バンドルのデプロイメント・アイコンをクリックして、 デプロイメント パネルに切り替えます。
-
バンドル リソース セクションで、 [追加] をクリックし、 [既存のジョブの追加] 、 [既存のパイプラインの追加] 、または [既存のダッシュボードの追加] を クリックします。
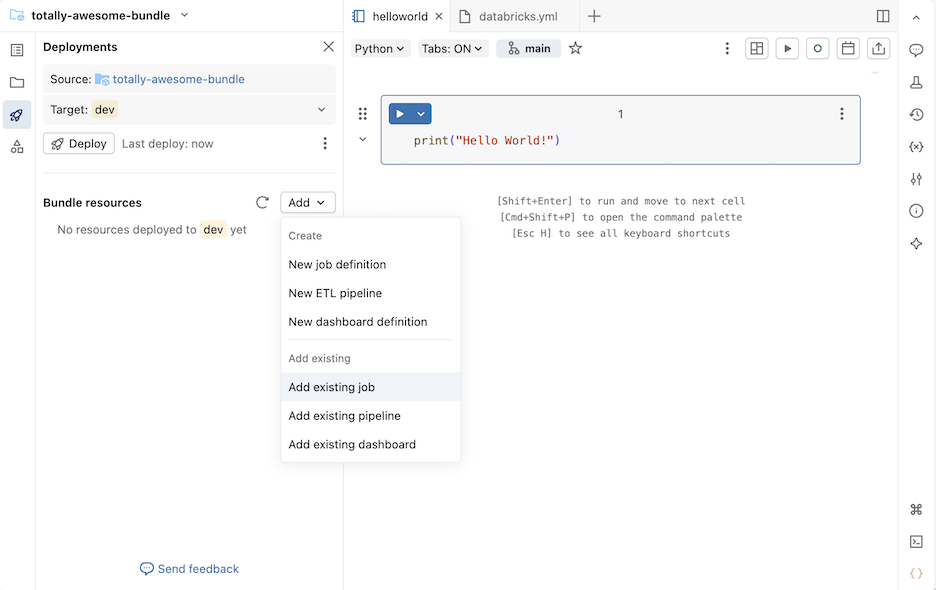
-
[既存の追加...] ダイアログで、ドロップダウンから既存のリソースを選択します。
-
既存のリソースをバンドルに追加すると、Databricks によってバンドル構成ファイルにこのリソースの定義が作成されます。この定義はバンドル内で変更できるため、バンドル内で定義されたリソースは、バンドルの作成に使用されたリソースと異なる場合があります。
バンドル リソース構成の更新を処理する方法のオプションを選択します。
- 本番運用デプロイに関する更新 : 既存のリソースはバンドル内のリソースにリンクされ、バンドル内のリソースに加えた変更は、
prodターゲットにデプロイするときに既存のリソースに適用されます。 - 開発デプロイ時の更新 : 既存のリソースはバンドル内のリソースにリンクされ、バンドル内のリソースに加えた変更は、
devターゲットにデプロイするときに既存のリソースに適用されます。 - (詳細) 更新しない : 既存のリソースはバンドルにリンクされていません。バンドル内のリソースに加えられた変更は、既存のリソースには適用されません。代わりに、コピーが作成されます。バンドル リソースを対応するワークスペース リソースにバインドする方法の詳細については、 「 databricks バンドル展開バインド 」を参照してください。
- 本番運用デプロイに関する更新 : 既存のリソースはバンドル内のリソースにリンクされ、バンドル内のリソースに加えた変更は、
-
既存のリソースをバンドルに追加するには、 [追加...] をクリックします。
バンドル設定を追加する
バンドル構成を定義してバンドルのデプロイメントに含めることで、既存のリソースをバンドルに追加することもできます。次の例では、既存のパイプラインをバンドルに追加します。
共有ワークスペースで taxifilter.ipynb ノートブックを実行する taxifilter という名前のパイプラインがあるとします。
-
Databricks ワークスペースのサイドバーで、[ ジョブとパイプライン] をクリックします。
-
必要に応じて、 [パイプライン ] フィルターと [自分が所有 ] フィルターを選択します。
-
既存の
taxifilterパイプラインを選択します。 -
パイプライン ページで、 開発 、デプロイメントモードボタンの左側にあるケバブをクリックします。次に、[ 設定 YAML の表示 ] をクリックします。
-
コピーアイコンをクリックして、パイプラインのバンドル設定をコピーします。
-
ワークスペース でバンドルに移動します。
-
バンドルのデプロイメント・アイコンをクリックして、 デプロイメント パネルに切り替えます。
-
バンドル リソース セクションで、 [追加] をクリックし、 [新しいパイプライン定義] を クリックします。
代わりに [新しいETLパイプライン] メニュー項目が表示される場合は、 Lakeflow Pipelinesエディターが有効になっています。 バンドルに ETL パイプラインを追加するには、 「ソース管理されたパイプラインを作成する」を参照してください。
-
「既存のバンドルにパイプラインを追加」ダイアログ の 「パイプライン名」 フィールドに
taxifilterと入力します。 [作成]を クリックします。 -
既存のパイプラインの構成をファイルに貼り付けます。このパイプライン例は、
taxifilterノートブックを実行するように定義されています。YAMLresources:
pipelines:
taxifilter:
name: taxifilter
catalog: main
libraries:
- notebook:
path: /Workspace/Shared/taxifilter.ipynb
target: taxifilter_${bundle.environment}
これで、バンドルをデプロイし、UI を使用してパイプライン リソースを実行できます。
バンドルリソースを編集する
ベータ版
この機能はベータ版です。
ワークスペースのUIで、バンドルに含まれるジョブとパイプラインを直接編集できます。変更内容は、バンドル内の該当リソースの設定YAMLファイルに自動的に適用されます。
バンドル内のジョブまたはパイプラインを編集するには:
- バンドルエディターの「 デプロイメント」 ペインから、 「バンドルリソース」 内のジョブまたはパイプラインをクリックして、ジョブまたはパイプラインを開きます。
- ノートブックタスクの追加やパイプラインスキーマの変更など、ジョブまたはパイプラインに変更を加えます。
- ワークスペースに通知が表示され、ジョブまたはパイプラインへの編集がバンドル構成に適用されたことが確認できます。通知内のYAMLファイルリンクをクリックすると、バンドルエディタで設定変更内容を確認できます。
- バンドルをデプロイして、構成変更がデプロイメントに適用されるようにします。
本番運用モードでは、リソースの編集は常に無効になります。
制限事項
ワークスペース内のリソースを編集する際には、以下の制限事項が適用されます。
- バンドル変数または置換によって値が取得されるフィールドを編集した場合、変更はそのフィールドのみに反映されます。変数の定義は更新されないため、同じ変数を参照する他のフィールドには影響しません。
- ジョブ権限の更新は、現時点ではサポートされていません。
- パイプラインまたはダッシュボードをスケジュールすると、スケジュールに従ってリソースを開始するジョブが作成されますが、ジョブと関連するパイプラインまたはダッシュボードはリンクされず、スケジュールはパイプラインまたはダッシュボード UI に表示されません。 スケジュールを変更するには、作成されたジョブのトリガーを編集してください。