Tracing Databricks 基盤モデル
MLflow Tracing は、Databricks 基盤モデルの自動トレース機能を提供します。Databricks基盤モデルは OpenAI 互換のAPIを使用しているため、mlflow.openai.autolog 関数を呼び出して自動トレースを有効にでき、MLflow はLLM呼び出しのトレースをキャプチャし、アクティブ エクスペリメントMLflowログに記録します。
import mlflow
mlflow.openai.autolog()
MLflow トレースは、 Databricks 基盤モデルの呼び出しに関する次の情報を自動的にキャプチャします。
- プロンプトと完了応答
- 待ち時間
- モデル名とエンドポイント
temperature、max_tokensなどの追加のメタデータ (指定されている場合)- 応答で返された場合の関数呼び出し
- 例外が発生した場合
サーバレス コンピュート クラスターでは、自動ログは自動的に有効になりません。 この統合の自動トレースを有効にするには、明示的に mlflow.openai.autolog() を呼び出す必要があります。
前提 条件
Databricks基盤モデルで MLflow Tracingを使用するには、MLflowとOpenAI SDK をインストールする必要があります(Databricks 基盤モデルはOpenAI互換のAPI を使用しているため)。
- Development
- Production
開発環境の場合は、Databricks エクストラと OpenAI SDK を含む完全な MLflow パッケージをインストールします。
pip install --upgrade "mlflow[databricks]>=3.1" openai
フル mlflow[databricks] パッケージには、Databricks でのローカル開発と実験のためのすべての機能が含まれています。
本番運用デプロイメントの場合は、 mlflow-tracing と OpenAI SDKをインストールします。
pip install --upgrade mlflow-tracing openai
mlflow-tracingパッケージは、本番運用での使用に最適化されています。
MLflow 3 は、 Databricks 基盤モデルで最適なトレースエクスペリエンスを実現するため、強くお勧めします。
例を実行する前に、環境を構成する必要があります。
Databricks ノートブックの外部ユーザーの場合 : Databricks 環境変数を設定します。
export DATABRICKS_HOST="https://your-workspace.cloud.databricks.com"
export DATABRICKS_TOKEN="your-personal-access-token"
Databricks ノートブック内のユーザーの場合 : これらの資格情報は自動的に設定されます。
サポートされている APIs
MLflow では、次の Databricks 基盤モデル APIsの自動トレースがサポートされています。
チャット完了 | 関数呼び出し | ストリーミング | 非同期 |
|---|---|---|---|
✅ | ✅ | ✅ | ✅ |
追加の のサポートをリクエストするには、 でAPIs 機能リクエスト GitHubを開いてください。
基本的な例
import mlflow
import os
from openai import OpenAI
# Databricks Foundation Model APIs use Databricks authentication.
# Enable auto-tracing for OpenAI (which will trace Databricks Foundation Model API calls)
mlflow.openai.autolog()
# Set up MLflow tracking to Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/databricks-foundation-models-demo")
# Create OpenAI client configured for Databricks
client = OpenAI(
api_key=os.environ.get("DATABRICKS_TOKEN"),
base_url=f"{os.environ.get('DATABRICKS_HOST')}/serving-endpoints"
)
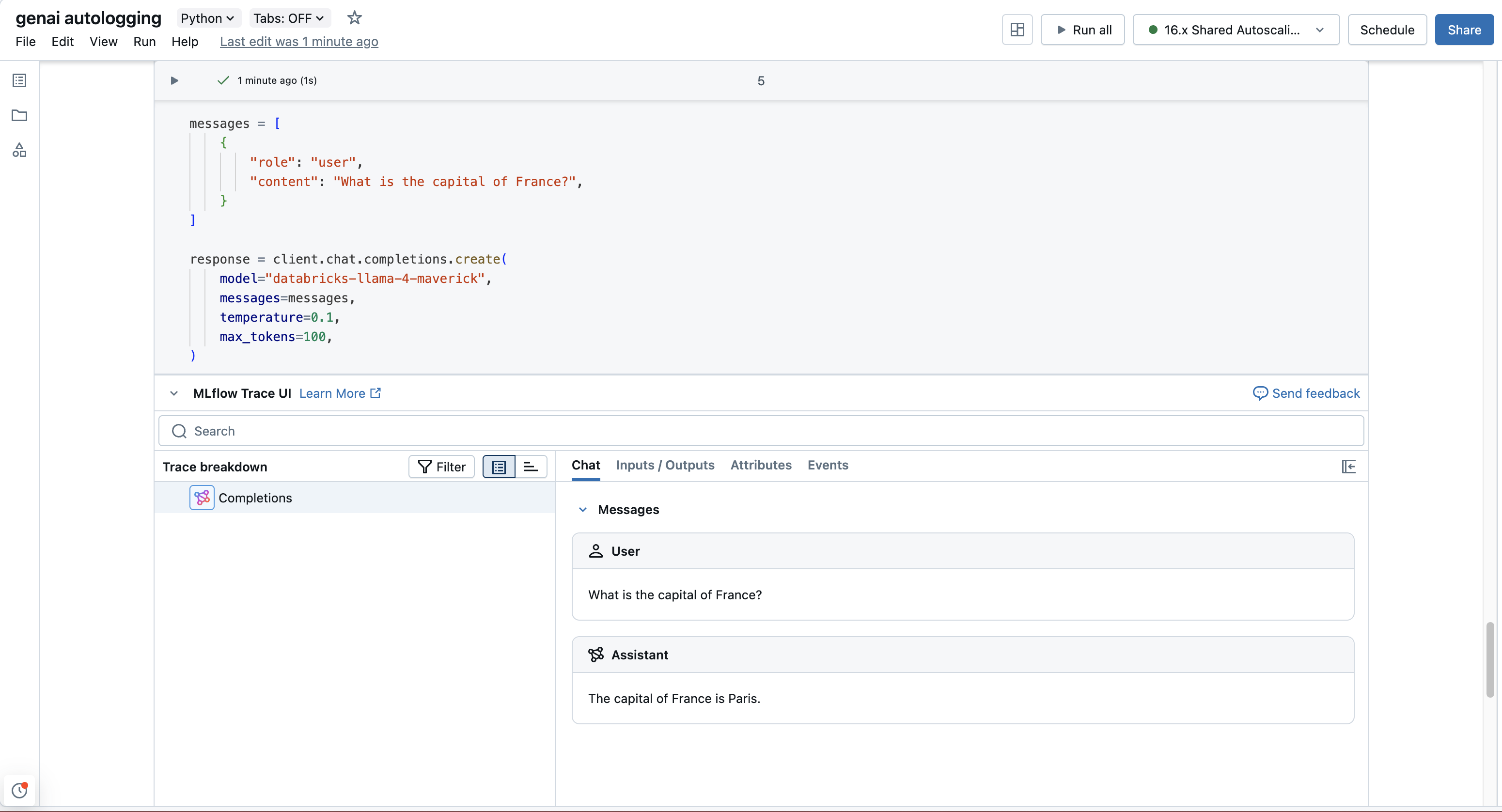
messages = [
{
"role": "user",
"content": "What is the capital of France?",
}
]
response = client.chat.completions.create(
model="databricks-llama-4-maverick",
messages=messages,
temperature=0.1,
max_tokens=100,
)
ストリーミング
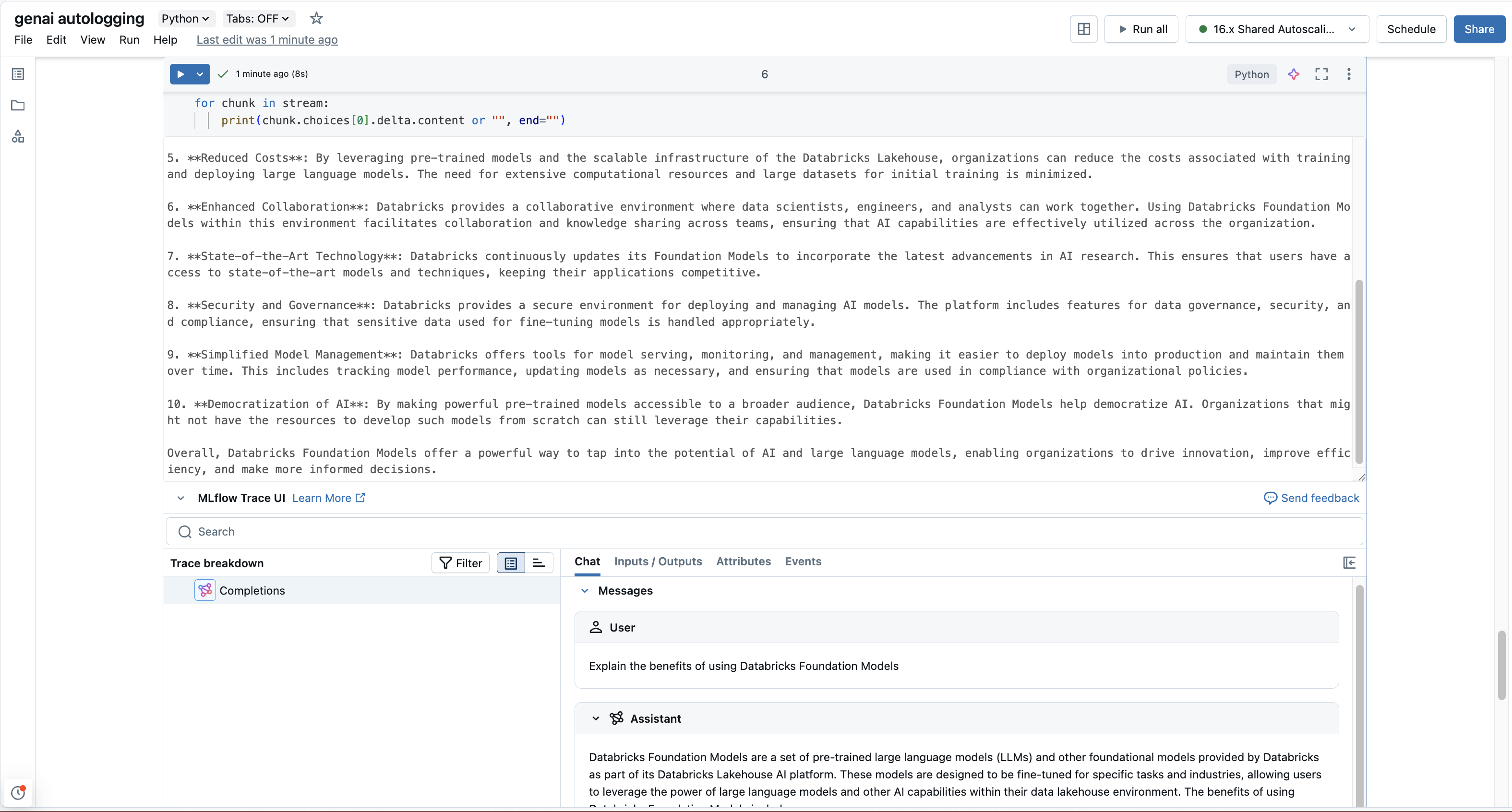
MLflow Tracingは、Databricks 基盤モデルのストリーミングAPIをサポートしています。自動トレースと同じ設定で、MLflow はストリーミング応答を自動的にトレースし、連結された出力をスパン UI にレンダリングします。
import mlflow
import os
from openai import OpenAI
# Enable auto-tracing for OpenAI (which will trace Databricks Foundation Model API calls)
mlflow.openai.autolog()
# Set up MLflow tracking to Databricks if not already configured
# mlflow.set_tracking_uri("databricks")
# mlflow.set_experiment("/Shared/databricks-streaming-demo")
# Create OpenAI client configured for Databricks
client = OpenAI(
api_key=os.environ.get("DATABRICKS_TOKEN"),
base_url=f"{os.environ.get('DATABRICKS_HOST')}/serving-endpoints"
)
stream = client.chat.completions.create(
model="databricks-llama-4-maverick",
messages=[
{"role": "user", "content": "Explain the benefits of using Databricks Foundation Models"}
],
stream=True, # Enable streaming response
)
for chunk in stream:
print(chunk.choices[0].delta.content or "", end="")
関数呼び出し
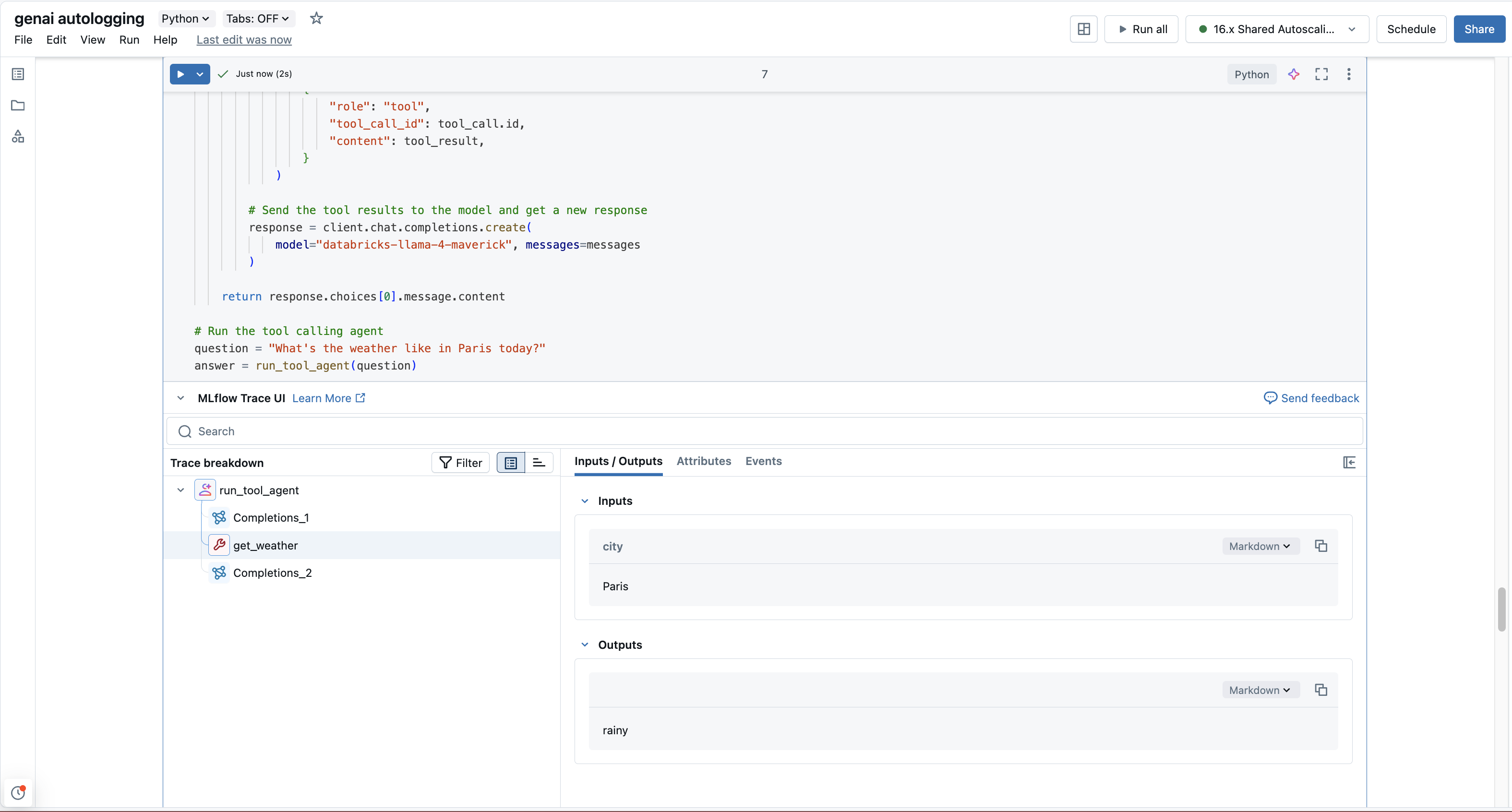
MLflow Tracing は、 Databricks 基盤モデルから関数呼び出し応答を自動的にキャプチャします。 応答内の関数命令は、トレース UI で強調表示されます。さらに、 @mlflow.trace デコレータを使用してツール関数に注釈を付けて、ツール実行のスパンを作成できます。
次の例では、 Databricks 基盤モデルと MLflow Tracingを使用して、エージェントを呼び出す単純な関数を実装します。
import json
import os
from openai import OpenAI
import mlflow
from mlflow.entities import SpanType
# Enable auto-tracing for OpenAI (which will trace Databricks Foundation Model API calls)
mlflow.openai.autolog()
# Set up MLflow tracking to Databricks if not already configured
# mlflow.set_tracking_uri("databricks")
# mlflow.set_experiment("/Shared/databricks-function-agent-demo")
# Create OpenAI client configured for Databricks
client = OpenAI(
api_key=os.environ.get("DATABRICKS_TOKEN"),
base_url=f"{os.environ.get('DATABRICKS_HOST')}/serving-endpoints"
)
# Define the tool function. Decorate it with `@mlflow.trace` to create a span for its execution.
@mlflow.trace(span_type=SpanType.TOOL)
def get_weather(city: str) -> str:
if city == "Tokyo":
return "sunny"
elif city == "Paris":
return "rainy"
return "unknown"
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
},
},
}
]
_tool_functions = {"get_weather": get_weather}
# Define a simple tool calling agent
@mlflow.trace(span_type=SpanType.AGENT)
def run_tool_agent(question: str):
messages = [{"role": "user", "content": question}]
# Invoke the model with the given question and available tools
response = client.chat.completions.create(
model="databricks-llama-4-maverick",
messages=messages,
tools=tools,
)
ai_msg = response.choices[0].message
# If the model requests tool call(s), invoke the function with the specified arguments
if tool_calls := ai_msg.tool_calls:
for tool_call in tool_calls:
function_name = tool_call.function.name
if tool_func := _tool_functions.get(function_name):
args = json.loads(tool_call.function.arguments)
tool_result = tool_func(**args)
else:
raise RuntimeError("An invalid tool is returned from the assistant!")
messages.append(
{
"role": "tool",
"tool_call_id": tool_call.id,
"content": tool_result,
}
)
# Send the tool results to the model and get a new response
response = client.chat.completions.create(
model="databricks-llama-4-maverick", messages=messages
)
return response.choices[0].message.content
# Run the tool calling agent
question = "What's the weather like in Paris today?"
answer = run_tool_agent(question)
利用可能なモデル
Databricks 基盤モデルでは、 Llama、 Anthropic、その他の主要な基盤モデルなど、さまざまな最新モデルにアクセスできます。
使用可能なモデルとそのモデル ID の完全かつ最新のリストについては、 Databricks 基盤モデルのドキュメントを参照してください。
自動トレースを無効にする
Databricks 基盤モデルの自動トレースは、mlflow.openai.autolog(disable=True) または mlflow.autolog(disable=True)を呼び出すことで、グローバルに無効にできます。