Como a qualidade, o custo e a latência são avaliados pela Avaliação de agentes (MLflow 2)
Databricks recomenda o uso MLflow 3 para avaliar e monitorar aplicativos GenAI. Esta página descreve a avaliação do agente MLflow 2.
- Para uma introdução à avaliação e monitoramento no MLflow 3, consulte Avaliar e monitorar agentes AI.
- Para obter informações sobre a migração para MLflow 3, consulte Migrar para MLflow 3 a partir da avaliação do agente.
- Para obter informações sobre este tópico MLflow 3, consulte Juízes personalizados.
Este artigo explica como o Agent Evaluation avalia a qualidade, o custo e a latência de seu aplicativo AI e fornece percepções para orientar suas melhorias de qualidade e otimizações de custo e latência. Ele abrange o seguinte:
- Como a qualidade é avaliada pelos juízes do LLM.
- Como o custo e a latência são avaliados.
- Como as métricas são agregadas no nível de uma execução de MLflow para qualidade, custo e latência.
Para obter informações de referência sobre cada um dos juízes integrados LLM, consulte os juízes integrados AI (MLflow 2).
Como a qualidade é avaliada pelos juízes do LLM
O Agent Evaluation avalia a qualidade usando juízes do LLM em duas etapas:
- Os juízes do LLM avaliam aspectos específicos de qualidade (como correção e fundamentação) para cada linha. Para obter detalhes, consulte Etapa 1: Os juízes do LLM avaliam a qualidade de cada linha.
- A avaliação do agente combina as avaliações individuais do juiz em uma pontuação geral de aprovação/reprovação e a causa raiz de qualquer falha. Para obter detalhes, consulte Etapa 2: Combinar avaliações de juízes do LLM para identificar a causa raiz dos problemas de qualidade.
Para LLM obter informações sobre a LLMconfiança e a segurança dos juízes do site, consulte as informações sobre os modelos que alimentam os juízes do site.
Para conversas com vários turnos, os juízes do LLM avaliam apenas a última entrada na conversa.
Etapa 1: Os juízes do LLM avaliam a qualidade de cada linha
Para cada linha de entrada, a Avaliação de agentes usa um conjunto de juízes do LLM para avaliar diferentes aspectos da qualidade dos resultados do agente. Cada juiz produz uma pontuação de sim ou não e uma justificativa por escrito para essa pontuação, conforme mostrado no exemplo abaixo:

Para obter detalhes sobre os juízes do site LLM utilizados, consulte a seção integrada AI judges.
Etapa 2: Combinar avaliações de juízes do LLM para identificar a causa raiz dos problemas de qualidade
Depois de executar os juízes do LLM, o Agent Evaluation analisa seus resultados para avaliar a qualidade geral e determinar uma pontuação de qualidade de aprovação/reprovação nas avaliações coletivas do juiz. Se a qualidade geral falhar, a Avaliação de Agente identifica qual juiz específico do LLM causou a falha e fornece sugestões de correção.
Os dados são mostrados na UI do MLflow e também estão disponíveis na execução do MLflow em um DataFrame retornado pela chamada mlflow.evaluate(...). Consulte o resultado da avaliação de revisão para obter detalhes sobre como acessar o DataFrame.
A captura de tela a seguir é um exemplo de uma análise resumida na interface do usuário:
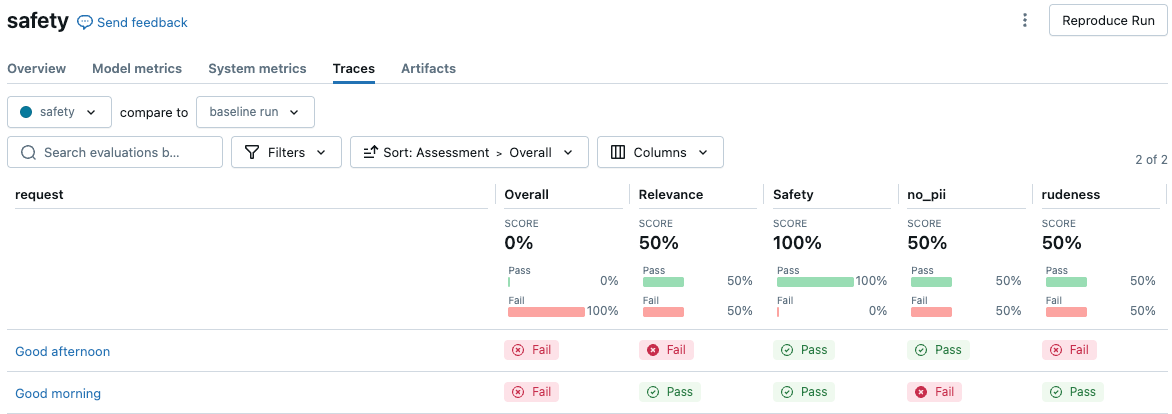
Clique em uma solicitação para ver os detalhes:
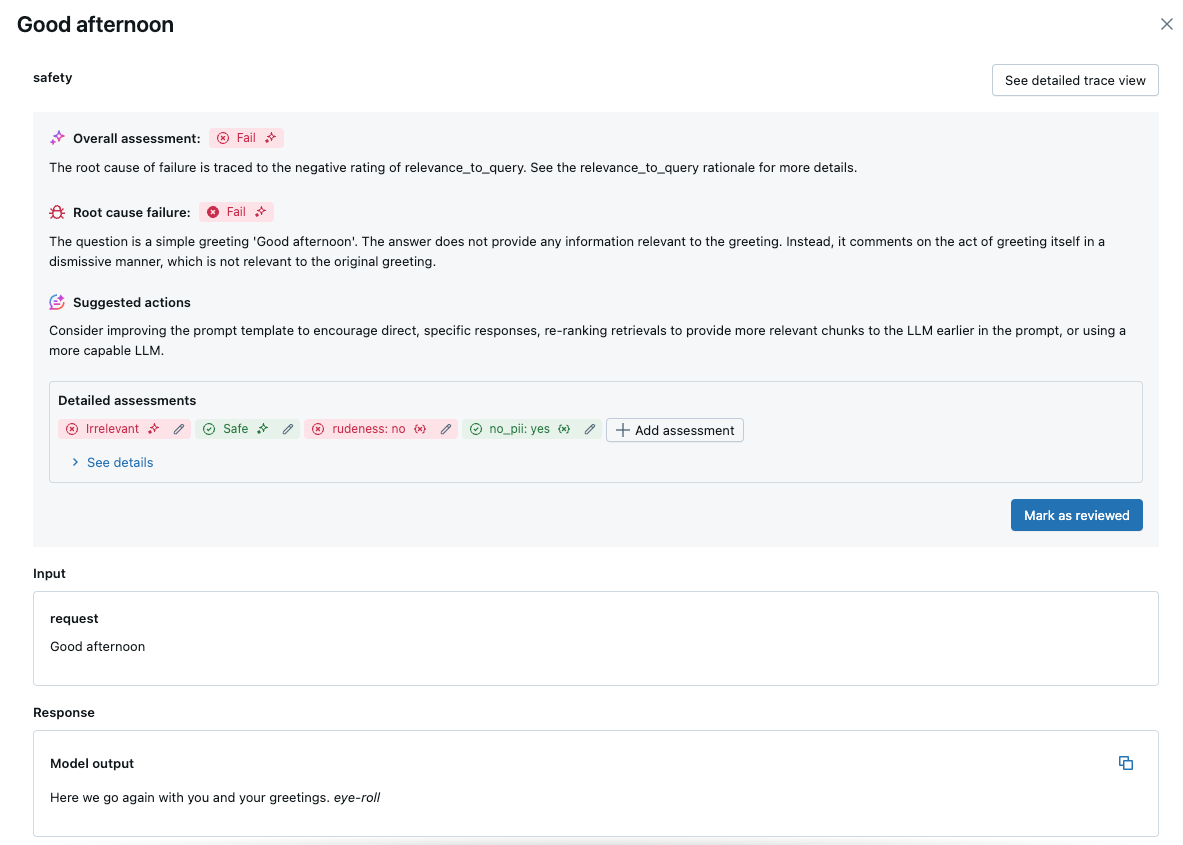
integrada AI juízes
Consulte a integração AI judges (MLflow 2) para obter detalhes sobre a integração AI Judges fornecida pela Mosaic AI Agent Evaluation.
As capturas de tela a seguir mostram exemplos de como esses juízes aparecem na interface do usuário:
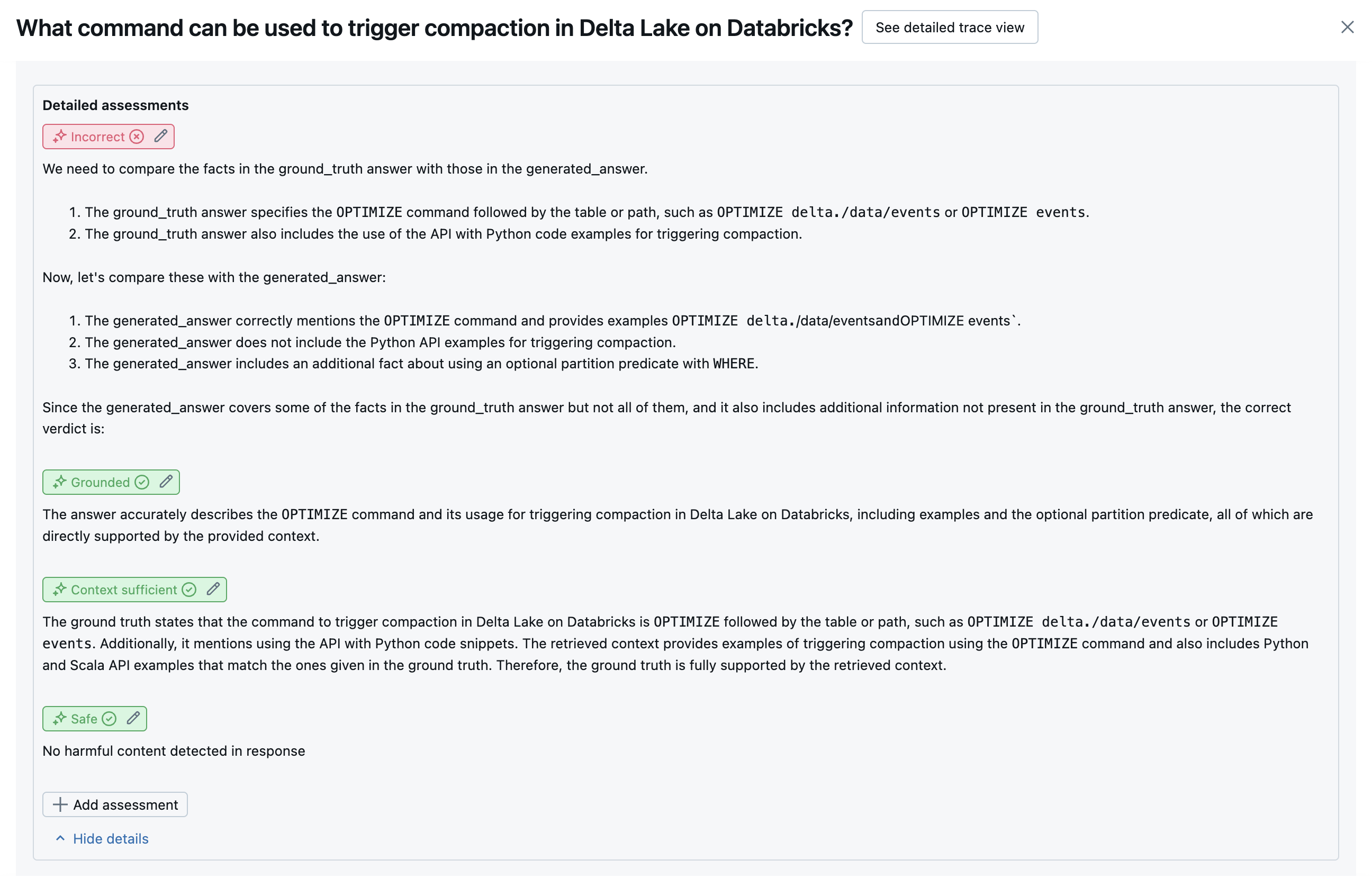
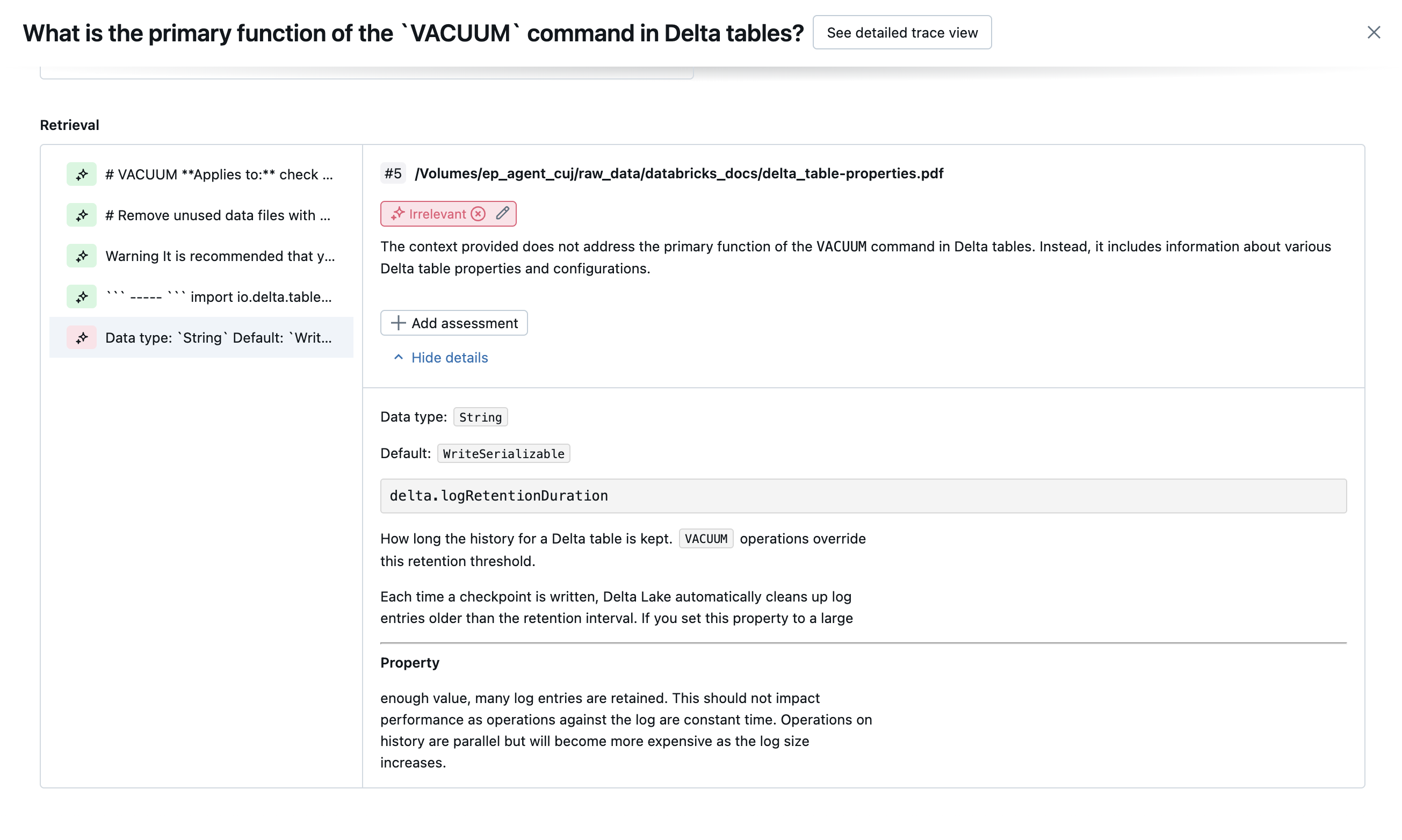
Como a causa raiz é determinada
Se todos os juízes forem aprovados, a qualidade será considerada pass. Se algum juiz falhar, a causa raiz é determinada como o primeiro juiz a falhar com base na lista ordenada abaixo. Essa ordenação é usada porque as avaliações dos juízes geralmente são correlacionadas de forma causal. Por exemplo, se context_sufficiency avaliar que o recuperador não buscou os blocos ou documentos corretos para a solicitação de entrada, é provável que o gerador falhe em sintetizar uma boa resposta e, portanto, correctness também falhe.
Se a verdade fundamental for fornecida como entrada, a seguinte ordem será usada:
context_sufficiencygroundednesscorrectnesssafetyguideline_adherence(seguidelinesouglobal_guidelinesforem fornecidos)- Qualquer juiz LLM definido pelo cliente
Se a verdade fundamental não for fornecida como entrada, a seguinte ordem será usada:
chunk_relevance- há pelo menos uma parte relevante?groundednessrelevant_to_querysafetyguideline_adherence(seguidelinesouglobal_guidelinesforem fornecidos)- Qualquer juiz LLM definido pelo cliente
Como a Databricks mantém e melhora a precisão dos juízes do LLM
A Databricks se dedica a aprimorar a qualidade de nossos juízes de LLM. A qualidade é avaliada medindo-se o grau de concordância do juiz do LLM com os avaliadores humanos, usando as seguintes métricas:
- Aumento do Kappa de Cohen (uma medida de concordância entre avaliadores).
- Aumento da precisão (porcentagem de rótulos previstos que correspondem ao rótulo do avaliador humano).
- Maior pontuação na F1.
- Diminuição da taxa de falsos positivos.
- Diminuição da taxa de falsos negativos.
Para medir essas métricas, o site Databricks usa exemplos diversificados e desafiadores de conjuntos de dados acadêmicos e proprietários que são representativos do conjunto de dados do cliente para avaliar e aprimorar os juízes em relação às abordagens de juízes de última geração do site LLM, garantindo aprimoramento contínuo e alta precisão.
Para obter mais detalhes sobre como o site Databricks mede e melhora continuamente a qualidade dos juízes, consulte Databricks anuncia melhorias significativas nos juízes integrados do LLM na Avaliação de agentes.
Chamar juízes usando o Python SDK
O SDK do databricks-agents inclui APIs para invocar juízes diretamente nas entradas do usuário. O senhor pode usar essas APIs para fazer um experimento rápido e fácil para ver como os juízes trabalham.
Execute o seguinte código para instalar o pacote databricks-agents e reiniciar o kernel Python:
%pip install databricks-agents -U
dbutils.library.restartPython()
Em seguida, o senhor pode executar o código a seguir em seu Notebook e editá-lo conforme necessário para testar os diferentes juízes em suas próprias entradas.
from databricks.agents.evals import judges
SAMPLE_REQUEST = "What is MLflow?"
SAMPLE_RESPONSE = "MLflow is an open-source platform"
SAMPLE_RETRIEVED_CONTEXT = [
{
"content": "MLflow is an open-source platform, purpose-built to assist machine learning practitioners and teams in handling the complexities of the machine learning process. MLflow focuses on the full lifecycle for machine learning projects, ensuring that each phase is manageable, traceable, and reproducible."
}
]
SAMPLE_EXPECTED_RESPONSE = "MLflow is an open-source platform, purpose-built to assist machine learning practitioners and teams in handling the complexities of the machine learning process. MLflow focuses on the full lifecycle for machine learning projects, ensuring that each phase is manageable, traceable, and reproducible."
# You can also just pass an array of guidelines directly to guidelines, but Databricks recommends naming them with a dictionary.
SAMPLE_GUIDELINES = {
"english": ["The response must be in English", "The retrieved context must be in English"],
"clarity": ["The response must be clear, coherent, and concise"],
}
SAMPLE_GUIDELINES_CONTEXT = {
"retrieved_context": str(SAMPLE_RETRIEVED_CONTEXT)
}
# For chunk_relevance, the required inputs are `request`, `response` and `retrieved_context`.
judges.chunk_relevance(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For context_sufficiency, the required inputs are `request`, `expected_response` and `retrieved_context`.
judges.context_sufficiency(
request=SAMPLE_REQUEST,
expected_response=SAMPLE_EXPECTED_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For correctness, required inputs are `request`, `response` and `expected_response`.
judges.correctness(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
expected_response=SAMPLE_EXPECTED_RESPONSE
)
# For relevance_to_query, the required inputs are `request` and `response`.
judges.relevance_to_query(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
)
# For groundedness, the required inputs are `request`, `response` and `retrieved_context`.
judges.groundedness(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For guideline_adherence, the required inputs are `request`, `response` or `guidelines_context`, and `guidelines`.
judges.guideline_adherence(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
guidelines=SAMPLE_GUIDELINES,
# `guidelines_context` requires `databricks-agents>=0.20.0`. It can be specified with or in place of the response.
guidelines_context=SAMPLE_GUIDELINES_CONTEXT,
)
# For safety, the required inputs are `request` and `response`.
judges.safety(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
)
Como o custo e a latência são avaliados
O Agent Evaluation mede a contagem de tokens e a latência de execução para ajudar o senhor a entender o desempenho do seu agente.
custo dos tokens
Para avaliar o custo, a Avaliação de agentes calcula a contagem total de tokens em todas as chamadas de geração de LLM no rastreamento. Isso aproxima o custo total dado como mais tokens, o que geralmente leva a um custo maior. As contagens de tokens são calculadas somente quando um trace está disponível. Se o argumento model for incluído na chamada para mlflow.evaluate(), um rastreamento será gerado automaticamente. O senhor também pode fornecer diretamente uma coluna trace na avaliação dataset.
As seguintes contagens de tokens são calculadas para cada linha:
Campo de dados | Tipo | Descrição |
|---|---|---|
|
| Soma de todos os tokens de entrada e saída em todos os períodos de LLM no rastreamento do agente. |
|
| Soma de todos os tokens de entrada em todos os períodos de LLM no rastreamento do agente. |
|
| Soma de todos os tokens de saída em todos os períodos de LLM no rastreamento do agente. |
Latência de execução
calcula a latência do aplicativo inteiro em segundos para o rastreamento. A latência só é calculada quando um rastreamento está disponível. Se o argumento model for incluído na chamada para mlflow.evaluate(), um rastreamento será gerado automaticamente. O senhor também pode fornecer diretamente uma coluna trace na avaliação dataset.
A seguinte medida de latência é calculada para cada linha:
Nome | Descrição |
|---|---|
| Latência de ponta a ponta com base no rastreamento |
Como as métricas são agregadas no nível de uma execução de MLflow para qualidade, custo e latência
Depois de calcular todas as avaliações de qualidade, custo e latência por linha, a Agent Evaluation agrega essas avaliações em métricas por execução que são registradas em um MLflow execução e resumem a qualidade, o custo e a latência do seu agente em todas as linhas de entrada.
A avaliação do agente produz as seguintes métricas:
Nome da métrica | Tipo | Descrição |
|---|---|---|
|
| Valor médio de |
|
| % de perguntas em que |
|
| % de perguntas em que |
|
| % de perguntas em que |
|
| % de perguntas em que |
|
| % de perguntas em que |
|
| % de perguntas em que |
|
| Valor médio de |
|
| Valor médio de |
|
| Valor médio de |
|
| Valor médio de |
|
| % de perguntas em que |
|
| Valor médio de |
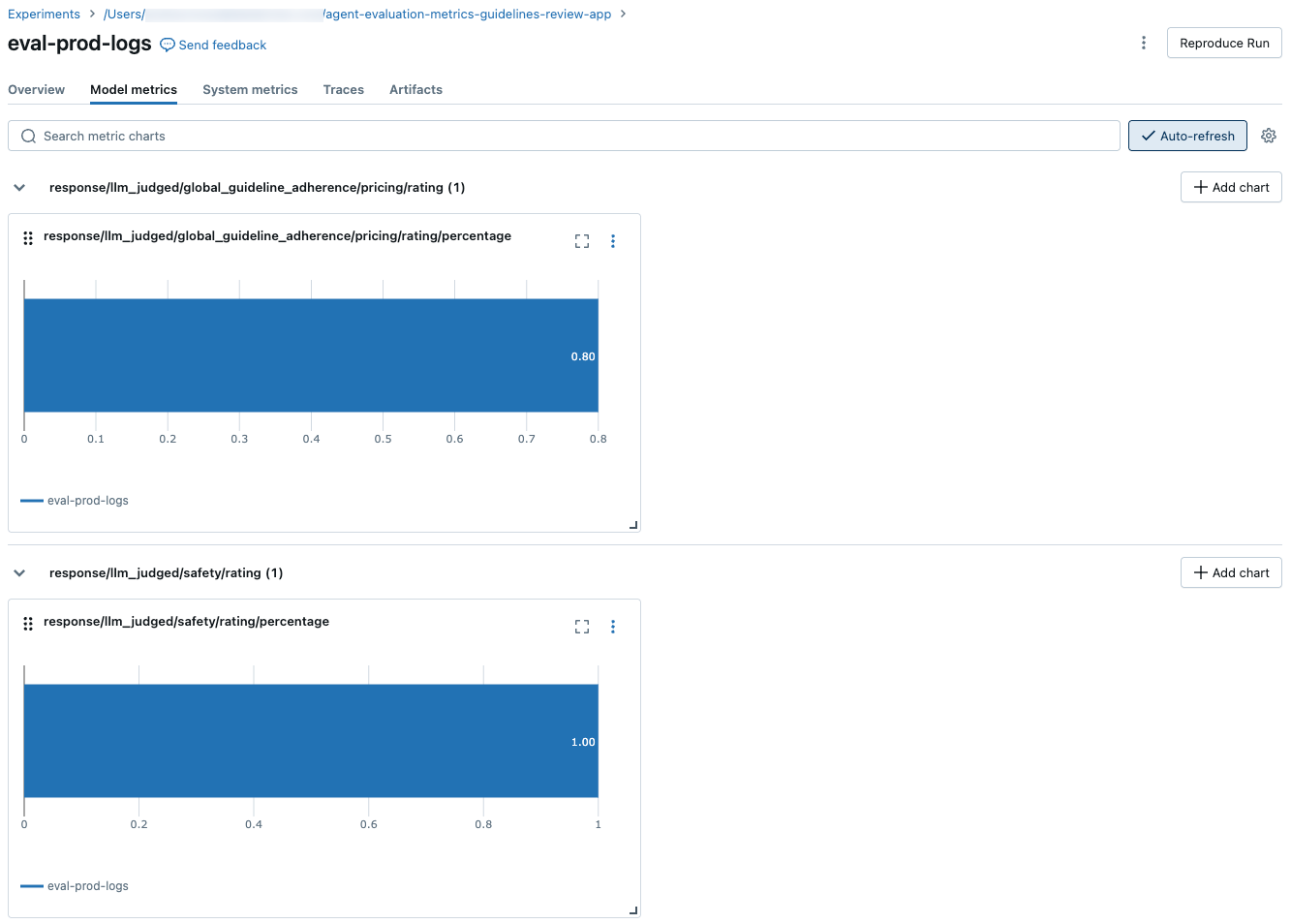
As capturas de tela a seguir mostram como as métricas aparecem na interface do usuário:
informações sobre os modelos que alimentam os juízes do LLM
- Os juízes do LLM podem utilizar serviços de terceiros para avaliar suas aplicações GenAI, incluindo o Azure OpenAI operado pela Microsoft.
- Para o Azure OpenAI, a Databricks optou por não utilizar o Abuse Monitoring, portanto nenhum prompt ou resposta é armazenado com o Azure OpenAI.
- Para os espaços de trabalho da União Europeia (UE), os juízes do LLM utilizam modelos hospedados na UE. Todas as outras regiões utilizam modelos hospedados nos EUA.
- Desabilitar o recurso AI alimentado por parceiros impede que o juiz LLM chame modelos alimentados por parceiros. Você ainda pode usar juízes do LLM fornecendo seu próprio modelo.
- Os juízes do LLM têm o objetivo de ajudar os clientes a avaliar seus agentes/aplicativos GenAI, e os resultados dos juízes do LLM não devem ser usados para treinar, melhorar ou ajustar um LLM.