Tarefa comum de manutenção pipeline
Aprenda como realizar operações contínuas para gerenciar o pipeline de ingestão.
Reinicie o pipeline de ingestão.
Aplica-se a : ![]() Conectores SaaS
Conectores SaaS ![]() Conectores de banco de dados
Conectores de banco de dados
Reinicie o pipeline de ingestão quando uma execução do pipeline falhar inesperadamente ou travar. Isso pode corrigir falhas transitórias, como problemas temporários de rede, tempos limite do banco de dados de origem ou erros de configuração que já foram corrigidos.
Interface | Instruções |
|---|---|
interface do usuário da casa do lago | |
APIde pipeline | |
CLI do Databricks |
Reinicie o gateway de ingestão.
Aplica-se a : ![]() Conectores de banco de dados
Conectores de banco de dados
Para diminuir a carga no banco de dados de origem, o gateway de ingestão verifica a existência de novas tabelas apenas periodicamente. Pode levar até seis horas para descobrir novas mesas. Para acelerar esse processo, reinicie o gateway.
Interface | Instruções |
|---|---|
interface do usuário da casa do lago | |
APIde pipeline | |
CLI do Databricks |
executar uma refresh completa para reingerir dados
Aplica-se a : ![]() Conectores SaaS
Conectores SaaS ![]() Conectores de banco de dados
Conectores de banco de dados
Uma refresh completa apaga os dados existentes e reinsere todos os registros. refresh completamente as tabelas de destino quando os dados forem inconsistentes, incompletos ou precisarem ser reprocessados a partir da origem.
Para obter mais informações sobre o comportamento refresh completa, consulte refresh totalmente as tabelas de destino.
Interface | Instruções |
|---|---|
interface do usuário da casa do lago | |
APIde pipeline | |
CLI do Databricks |
Atualizar o programador pipeline
Aplica-se a : ![]() Conectores SaaS
Conectores SaaS ![]() Conectores de banco de dados
Conectores de banco de dados
Ajuste a frequência com que os dados são ingeridos da fonte para equilibrar os requisitos de atualização dos dados com a carga do sistema de origem.
Interface | Instruções |
|---|---|
interface do usuário da casa do lago | |
API de jobs | |
CLI do Databricks |
ALTER tabelas de transmissão de destino
Aplica-se a : ![]() Conectores SaaS
Conectores SaaS ![]() Conectores de banco de dados
Conectores de banco de dados
Você pode usar instruções SQL ALTER para modificar o conjunto de dados pipeline de ingestão de gerenciamento. Para obter a sintaxe completa e exemplos, consulte ALTER STREAMING TABLE.
Você não pode modificar o programar ou o gatilho de um dataset pipeline de ingestão gerenciado com uma instrução ALTER . Consulte Atualizar o programador pipeline.
Configure alertas e notificações.
Aplica-se a : ![]() Conectores SaaS
Conectores SaaS ![]() Conectores de banco de dados
Conectores de banco de dados
LakeFlow Connect configura automaticamente notificações para o pipeline de ingestão e para os trabalhos de programação, permitindo que você monitore a integridade pipeline e receba alertas oportunos sobre falhas. Você pode personalizar as notificações, se necessário.
Interface | Instruções |
|---|---|
interface do usuário da casa do lago | |
APIde pipeline | |
CLI do Databricks |
Remova os arquivos de preparação não utilizados.
Aplica-se a : ![]() Conectores de banco de dados
Conectores de banco de dados
Para pipelines de ingestão criados após 6 de janeiro de 2025, Databricks programa automaticamente o volume de dados de preparação para exclusão após 25 dias e os remove fisicamente após 30 dias. Um pipeline de ingestão que não seja concluído com sucesso em 25 dias ou mais pode resultar em lacunas de dados nas tabelas de destino. Para evitar lacunas, você deve acionar uma refresh completa das tabelas de destino.
Para pipelines de ingestão criados antes de 6 de janeiro de 2025, entre em contato com o Suporte Databricks para solicitar a ativação manual do gerenciamento automático de retenção para dados de preparação CDC .
Os seguintes dados são limpos automaticamente:
- Arquivos de dados do CDC
- Arquivos Snapshot
- dados da tabela de preparação
Especifique as tabelas a serem ingeridas.
Aplica-se a : ![]() Conectores SaaS
Conectores SaaS ![]() Conectores de banco de dados
Conectores de banco de dados
A API do pipeline fornece dois métodos para especificar as tabelas a serem ingeridas no campo objects do ingestion_definition:
- Especificação da tabela: Importa uma tabela individual do catálogo e esquema de origem especificados para o catálogo e esquema de destino especificados.
- Especificação do esquema: Importa todas as tabelas do catálogo e esquema de origem especificados para o catálogo e esquema especificados.
Caso opte por ingerir um esquema completo, verifique as limitações quanto ao número de tabelas por pipeline para o seu conector.
Interface | Instruções |
|---|---|
APIde pipeline | |
CLI do Databricks |
Verificar se a ingestão de dados foi bem-sucedida
Aplica-se a : ![]() Conectores de banco de dados
Conectores de banco de dados
A view em lista na página de detalhes pipeline mostra o número de registros processados à medida que os dados são ingeridos. Esses números refresh automaticamente.
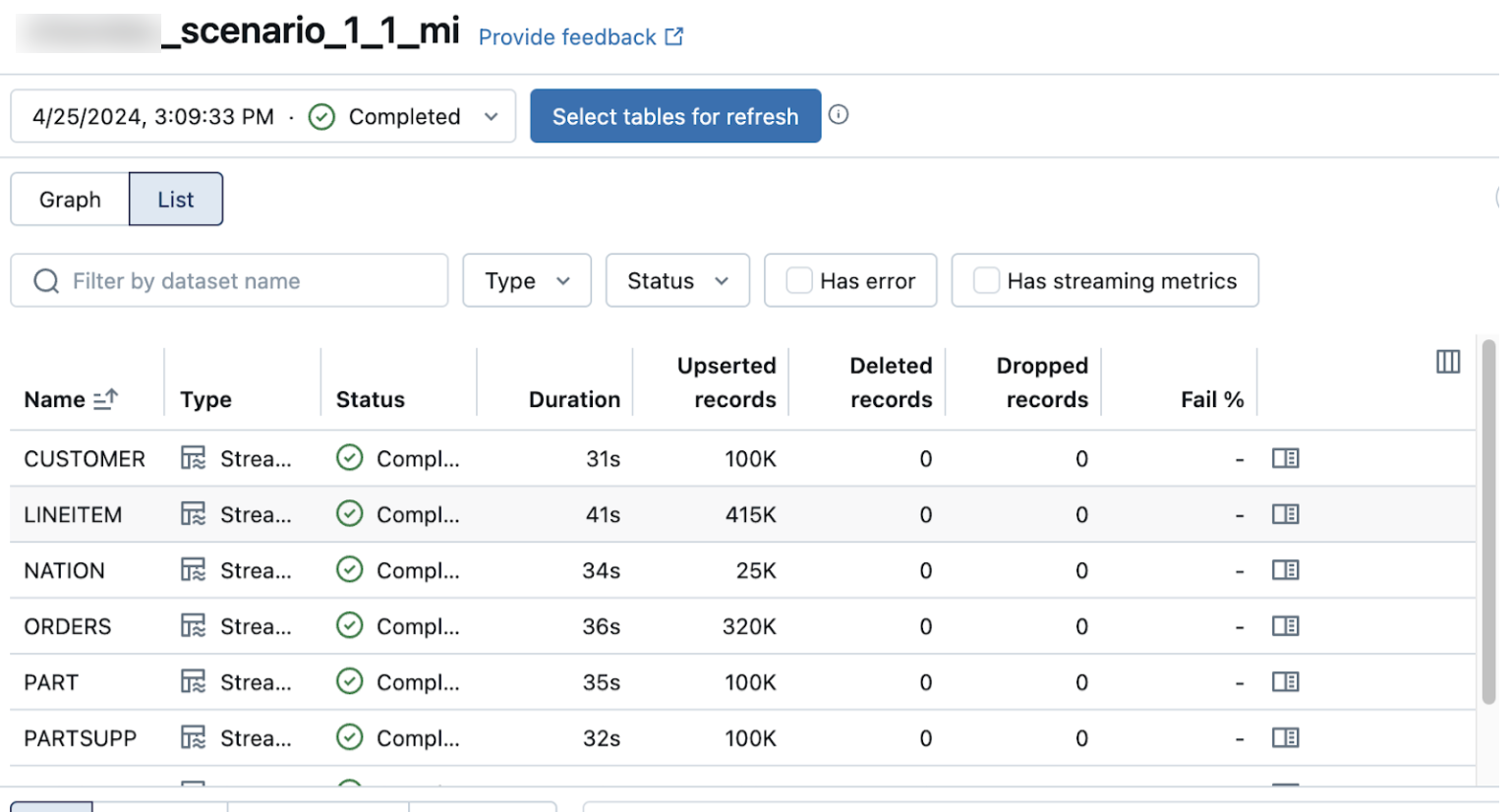
As colunas Upserted records e Deleted records não são exibidas por default. Você pode habilitá-las clicando na configuração das colunas.![]() botão e selecionando-os.
botão e selecionando-os.