Tabelas de métricas de perfil de dados
Esta página descreve as tabelas de métricas criadas pela análise de perfil de dados. Para informações sobre o dashboard criado por um perfil, consulte perfil de dados dashboard.
Quando um perfil é executado em uma tabela Databricks , ele cria ou atualiza duas tabelas de métricas: uma tabela de métricas de perfil e uma tabela de métricas de deriva.
- A tabela de métricas de perfil contém estatísticas resumidas para cada coluna e para cada combinação de janela de tempo, fatia e colunas de agrupamento. Para a análise
InferenceLog, a tabela de análise também contém métricas de precisão do modelo. - A tabela de métricas de deriva contém estatísticas que rastreiam mudanças na distribuição de uma métrica. As tabelas de deriva podem ser usadas para visualizar ou alertar sobre mudanças nos dados em vez de valores específicos. Os seguintes tipos de deriva são calculados:
- A deriva consecutiva compara uma janela de tempo com a janela de tempo anterior. A deriva consecutiva só é calculada se existir uma janela de tempo consecutiva após a agregação, de acordo com as granularidades especificadas.
- A deriva da linha de base compara uma janela com a distribuição da linha de base determinada pela tabela de linha de base. A deriva da linha de base só é calculada se uma tabela de linha de base for fornecida.
Localização das tabelas métricas
As tabelas de métricas são salvas em {output_schema}.{table_name}_profile_metrics e {output_schema}.{table_name}_drift_metrics, onde:
{output_schema}é o catálogo e esquema especificado poroutput_schema_name.{table_name}é o nome da tabela que está sendo analisada.
Como as estatísticas de perfil são calculadas
Cada estatística e métricas nas tabelas de métricas são calculadas para um intervalo de tempo específico (chamado de “janela”). Para a análise Snapshot , a janela de tempo é um único ponto no tempo correspondente ao momento em que os dados foram atualizados. Para a análise TimeSeries e InferenceLog , a janela de tempo é baseada nas granularidades especificadas em create_monitor e nos valores em timestamp_col especificados no argumento profile_type .
Os números são sempre calculados para a tabela inteira. Além disso, se você fornecer uma expressão de fatiamento, as métricas serão calculadas para cada fatia de dados definida por um valor da expressão.
Por exemplo:
slicing_exprs=["col_1", "col_2 > 10"]
gera as seguintes fatias: uma para col_2 > 10, uma para col_2 <= 10 e uma para cada valor único em col1.
As fatias são identificadas nas tabelas de métricas pelos nomes das colunas slice_key e slice_value. Neste exemplo, uma key de fatiamento seria “col_2 > 10” e os valores correspondentes seriam “true” e “false”. A tabela inteira é equivalente a slice_key = NULL e slice_value = NULL. As fatias são definidas por uma única key de fatia.
Os cálculos são feitos para todos os grupos possíveis definidos pelas janelas de tempo e pelas chaves e valores de cada fatia. Além disso, para a análise InferenceLog , as métricas são calculadas para cada ID de modelo. Para obter detalhes, consulte Esquemas de coluna para tabelas geradas.
Estatísticas adicionais para a precisão do modelo (apenas para a análise InferenceLog )
Estatísticas adicionais são calculadas para a análise InferenceLog .
- A qualidade do modelo é calculada se ambos
label_coleprediction_colforem fornecidos. - As fatias são criadas automaticamente com base nos valores distintos de
model_id_col. - Para modelos de classificação, as estatísticas de imparcialidade e viés são calculadas para fatias que possuem um valor Boolean .
Tabelas de métricas de análise de consultas e desvios
Você pode consultar as tabelas de métricas diretamente. O exemplo a seguir é baseado na análise InferenceLog :
SELECT
window.start, column_name, count, num_nulls, distinct_count, frequent_items
FROM census_monitor_db.adult_census_profile_metrics
WHERE model_id = 1 — Constrain to version 1
AND slice_key IS NULL — look at aggregate metrics over the whole data
AND column_name = "income_predicted"
ORDER BY window.start
Esquemas de colunas para tabelas geradas
Para cada coluna na tabela principal, as tabelas de métricas contêm uma linha para cada combinação de colunas de agrupamento. A coluna associada a cada linha é mostrada na coluna column_name.
Para métricas baseadas em mais de uma coluna, como métricas de precisão do modelo, column_name é definido como :table.
Para as métricas de perfil, são utilizadas as seguintes colunas de agrupamento:
- janela de tempo
- granularidade (análise apenas de
TimeSerieseInferenceLog) - Tipo de log - tabela de entrada ou tabela de linha de base
- key e valor de fatia
- ID do modelo (apenas análise
InferenceLog)
Para as métricas de deriva, são utilizadas as seguintes colunas de agrupamento adicionais:
- janela de tempo de comparação
- Tipo de deriva (comparação com a janela anterior ou comparação com a tabela de referência)
Os esquemas das tabelas de métricas são mostrados abaixo, e também são mostrados na documentação de referência API perfil de dados.
Esquema da tabela de métricas de perfil
A tabela a seguir mostra o esquema da tabela de métricas de perfil. Quando uma medida não se aplica a uma linha, a célula correspondente é nula.
Nome da coluna | Tipo | Descrição |
|---|---|---|
Agrupamento de colunas | ||
janela | Estrutura. Veja [1] abaixo. | Janela de tempo. |
Granularidade | string | Duração da janela, definida pelo parâmetro |
coluna_id_modelo | string | Opcional. Utilizado apenas para o tipo de análise |
tipo_de_log | string | Tabela utilizada para calcular as métricas. LINHA DE BASE ou ENTRADA. |
chave_de_fatia | string | Expressão de fatia. NULL para default, que é todos os dados. |
valor_da_fatia | string | Valor da expressão de fatiamento. |
nome_da_coluna | string | Nome da coluna na tabela principal. |
tipo_de_dados | string | Tipo de dados Spark de |
versão_de_commit_da_tabela_de_registros | int | Ignorar. |
versão_do_monitor | BigInt | Versão da configuração de perfil usada para calcular as métricas na linha. Veja [3] abaixo para detalhes. |
Colunas de métricas - estatísticas resumidas | ||
contar | BigInt | Número de valores não nulos. |
num_nulos | BigInt | Número de valores nulos em |
média | double | Média aritmética da coluna, ignorando valores nulos. |
quantis |
| Conjunto de 1000 quantis. Veja [4] abaixo. |
contagem distinta | BigInt | Número aproximado de valores distintos em |
Mín | double | Valor mínimo em |
Máx | double | Valor máximo em |
desvio padrão | double | Desvio padrão de |
num_zeros | BigInt | Número de zeros em |
num_nan | BigInt | Número de valores NaN em |
tamanho_mínimo | double | Tamanho mínimo de arrays ou estruturas em |
tamanho_máximo | double | Tamanho máximo de arrays ou estruturas em |
tamanho médio | double | Tamanho médio de matrizes ou estruturas em |
comprimento_mínimo | double | Comprimento mínimo de strings e valores binários em |
comprimento_máximo | double | Comprimento máximo de strings e valores binários em |
comprimento médio | double | Comprimento médio de strings e valores binários em |
itens_frequentes | Estrutura. Veja [1] abaixo. | Os 100 itens que ocorrem com maior frequência. |
colunas_não_nulas |
| Lista de colunas com pelo menos um valor não nulo. |
Mediana | double | Valor mediano de |
percentual_nulo | double | Percentagem de valores nulos em |
percent_zeros | double | Percentagem de valores que são zero em |
percent_distinto | double | Percentagem de valores que são distintos em |
Colunas de métricas - precisão do modelo de classificação [5] | ||
pontuação_de_precisão | double | Precisão do modelo, calculada como:
Valores nulos são ignorados. |
perda de log | double | A perda logarítmica para problemas de classificação é calculada como:
Requer |
pontuação_roc_auc | Estrutura. Veja [1] abaixo. | Pontuação AUC da curva ROC para classificação binária e multiclasse. Requer |
matriz_de_confusão | Estrutura. Veja [1] abaixo. | |
Precisão | Estrutura. Veja [1] abaixo. | |
Recall | Estrutura. Veja [1] abaixo. | |
f1_score | Estrutura. Veja [1] abaixo. | |
Colunas de métricas - precisão do modelo de regressão [5] | ||
erro_quadrado_médio | double | Erro quadrático médio entre |
erro_quadrado_médio | double | Erro quadrático médio entre |
erro médio | double | Erro médio entre |
erro percentual absoluto médio | double | Erro percentual absoluto médio entre |
pontuação r2 | double | Pontuação R-quadrado entre |
Colunas de métricas - imparcialidade e viés [6] | ||
paridade_preditiva | double | Mede se os dois grupos têm precisão igual em todas as classes previstas. |
igualdade_preditiva | double | Mede se os dois grupos têm taxas iguais de falsos positivos em todas as classes previstas. |
igualdade_de_oportunidades | double | Mede se os dois grupos têm o mesmo nível de recall em todas as classes previstas. |
paridade_estatística | double | Mede se os dois grupos têm taxas de aceitação iguais. A taxa de aceitação aqui é definida como a probabilidade empírica de ser previsto como pertencente a uma determinada classe, dentre todas as classes previstas. |

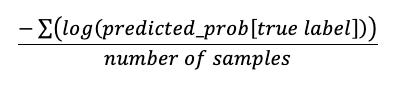
[1] Formato da estrutura para confusion_matrix, precision, recall, f1_score e roc_auc_score:
Nome da coluna | Tipo |
|---|---|
janela |
|
itens_frequentes |
|
matriz_de_confusão |
|
Precisão |
|
Recall |
|
f1_score |
|
pontuação_roc_auc |
|
[2] Para séries temporais ou perfis de inferência, o perfil olha para trás 30 dias a partir do momento em que o perfil é criado. Devido a esse limite, a primeira análise pode incluir uma janela parcial. Por exemplo, o limite de 30 dias pode cair no meio de uma semana ou de um mês, caso em que a semana ou o mês inteiro não é incluído no cálculo. Este problema afeta apenas a primeira janela.
[3] A versão mostrada nesta coluna é a versão que foi usada para calcular as estatísticas na linha e pode não ser a versão atual do perfil. Cada vez que você refresh as métricas, o perfil tenta recalcular as métricas calculadas anteriormente usando a configuração de perfil atual. A versão atual do perfil aparece nas informações de perfil retornadas pela API e pelo cliente Python .
[4] Código de exemplo para recuperar o 50º percentil: SELECT element_at(quantiles, int((size(quantiles)+1)/2)) AS p50 ... ou SELECT quantiles[500] ....
[5] Só é mostrado se o perfil tiver o tipo de análise InferenceLog e ambos label_col e prediction_col forem fornecidos.
[6] Mostrado apenas se o perfil tiver tipo de análise InferenceLog e problem_type for classification.
Esquema da tabela de métricas de deriva
A tabela a seguir mostra o esquema da tabela de métricas de deriva. A tabela de deriva só é gerada se uma tabela de referência for fornecida ou se existir uma janela de tempo consecutiva após a agregação, de acordo com as granularidades especificadas. Quando uma medida não se aplica a uma linha, a célula correspondente é nula.
Nome da coluna | Tipo | Descrição |
|---|---|---|
Agrupamento de colunas | ||
janela |
| Janela de tempo. |
janela_cmp |
| Janela de comparação para drift_type |
tipo de deriva | string | LINHA DE BASE ou CONSECUTIVA. Se as métricas de deriva forem comparadas com a janela de tempo anterior ou com a tabela de referência. |
Granularidade | string | Duração da janela, definida pelo parâmetro |
coluna_id_modelo | string | Opcional. Utilizado apenas para o tipo de análise |
chave_de_fatia | string | Expressão de fatia. NULL para default, que é todos os dados. |
valor_da_fatia | string | Valor da expressão de fatiamento. |
nome_da_coluna | string | Nome da coluna na tabela principal. |
tipo_de_dados | string | Tipo de dados Spark de |
versão_do_monitor | BigInt | Versão da configuração do monitor usada para calcular as métricas na linha. Veja [8] abaixo para detalhes. |
Colunas de métricas - desvio | As diferenças são calculadas como janela atual - janela de comparação. | |
contagem_delta | double | Diferença em |
delta médio | double | Diferença em |
percentual_nulo_delta | double | Diferença em |
percent_zeros_delta | double | Diferença em |
percent_distinct_delta | double | Diferença em |
delta de colunas não nulas |
| Número de colunas com qualquer aumento ou diminuição nos valores não nulos. |
teste_qui_quadrado |
| Teste do qui-quadrado para deriva na distribuição. Calculado apenas para colunas categóricas. |
ks_test |
| Teste KS para deriva na distribuição. Calculado apenas para colunas numéricas. |
distância_tv | double | Distância de variação total para deriva na distribuição. Calculado apenas para colunas categóricas. |
distância_infinita | double | Distância L-infinito para deriva na distribuição. Calculado apenas para colunas categóricas. |
js_distance | double | Distância de Jensen-Shannon para deriva na distribuição. Calculado apenas para colunas categóricas. |
distância_wasserstein | double | Desvio entre duas distribuições numéricas usando a métrica de distância de Wasserstein. Calculado apenas para colunas numéricas. |
índice_de_estabilidade_populacional | double | medidas para comparar a deriva entre duas distribuições numéricas usando o índice de estabilidade populacional medidas. Veja [9] abaixo para detalhes. Calculado apenas para colunas numéricas. |
[7] Para séries temporais ou perfis de inferência, o perfil olha para trás 30 dias a partir do momento em que o perfil é criado. Devido a esse limite, a primeira análise pode incluir uma janela parcial. Por exemplo, o limite de 30 dias pode cair no meio de uma semana ou de um mês, caso em que a semana ou o mês inteiro não é incluído no cálculo. Este problema afeta apenas a primeira janela.
[8] A versão mostrada nesta coluna é a versão que foi usada para calcular as estatísticas na linha e pode não ser a versão atual do perfil. Cada vez que você refresh as métricas, o perfil tenta recalcular as métricas calculadas anteriormente usando a configuração de perfil atual. A versão atual do perfil aparece nas informações de perfil retornadas pela API e pelo cliente Python .
[9] O resultado do índice de estabilidade populacional é um valor numérico que representa o quão diferentes são duas distribuições. O intervalo é [0, infinito). PSI < 0,1 significa que não houve alteração significativa na população. PSI < 0,2 indica mudança populacional moderada. PSI ≥ 0,2 indica mudança populacional significativa.