Execução adaptável de consultas
A execução adaptativa de consultas (AQE) é a reotimização de consultas que ocorre durante a execução da consulta.
A motivação para a reotimização do tempo de execução é que a Databricks tem as estatísticas precisas mais atualizadas no final de uma troca de embaralhamento e transmissão (chamada de estágio de consulta no AQE). Como resultado, o site Databricks pode optar por uma estratégia física melhor, escolher um tamanho e um número de partição pós-baralhamento ideais ou fazer otimizações que costumavam exigir dicas, por exemplo, o manuseio do skew join.
Isso pode ser muito útil quando a coleta de estatísticas não está ativada ou quando as estatísticas estão desatualizadas. Também é útil em locais onde as estatísticas derivadas estaticamente são imprecisas, como no meio de uma consulta complicada ou após a ocorrência de distorção de dados.
Capacidades
O AQE é ativado pelo site default. Ele tem 4 recursos principais:
- Altera dinamicamente a classificação merge join para broadcast hash join.
- Coalesce dinamicamente as partições (combine partições pequenas em partições de tamanho razoável) após a troca aleatória. Tarefas muito pequenas têm taxas de transferência de E/S piores e tendem a sofrer mais com o overhead de programação e o overhead de configuração da tarefa. A combinação de pequenas tarefas economiza recurso e melhora o agrupamento Taxa de transferência.
- Lida dinamicamente com a inclinação na classificação merge join e embaralha o hash join dividindo (e replicando, se necessário) a tarefa inclinada em uma tarefa de tamanho aproximadamente igual.
- Detecta e propaga dinamicamente relações vazias.
Aplicação
O AQE se aplica a todas as consultas que são:
- Não-transmissão
- Contém pelo menos uma troca (geralmente quando há um join, agregado ou janela), uma subconsulta ou ambos.
Nem todas as consultas aplicadas ao AQE são necessariamente reotimizadas. A reotimização pode ou não resultar em um plano de consulta diferente daquele compilado estaticamente. Para determinar se o plano de uma consulta foi alterado pelo AQE, consulte a seção a seguir, Planos de consulta.
Planos de consulta
Esta seção discute como você pode examinar os planos de consulta de maneiras diferentes.
Nesta secção:
Spark UI
NodoAdaptiveSparkPlan
As consultas aplicadas ao AQE contêm um ou mais nós AdaptiveSparkPlan, geralmente como o nó raiz de cada consulta principal ou subconsulta.
Antes de a consulta ser executada ou quando estiver sendo executada, o sinalizador isFinalPlan do nó AdaptiveSparkPlan correspondente será exibido como false; após a conclusão da execução da consulta, o sinalizador isFinalPlan será alterado para true.
Plano em evolução
O diagrama do plano de consulta evolui à medida que a execução avança e reflete o plano mais atual que está sendo executado. Os nós que já foram executados (nos quais as métricas estão disponíveis) não serão alterados, mas os que não foram podem mudar ao longo do tempo como resultado de re-otimizações.
Veja a seguir um exemplo de diagrama de plano de consulta:
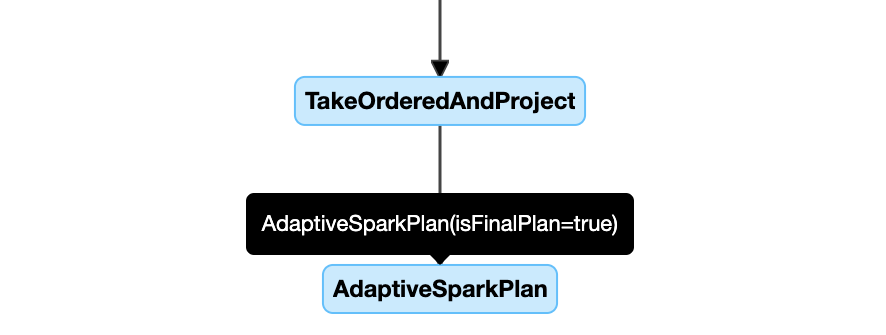
DataFrame.explain()
NodoAdaptiveSparkPlan
As consultas aplicadas ao AQE contêm um ou mais nós AdaptiveSparkPlan, geralmente como o nó raiz de cada consulta principal ou subconsulta. Antes da execução da consulta ou quando ela estiver em execução, o sinalizador isFinalPlan do nó AdaptiveSparkPlan correspondente será exibido como false; após a conclusão da execução da consulta, o sinalizador isFinalPlan será alterado para true.
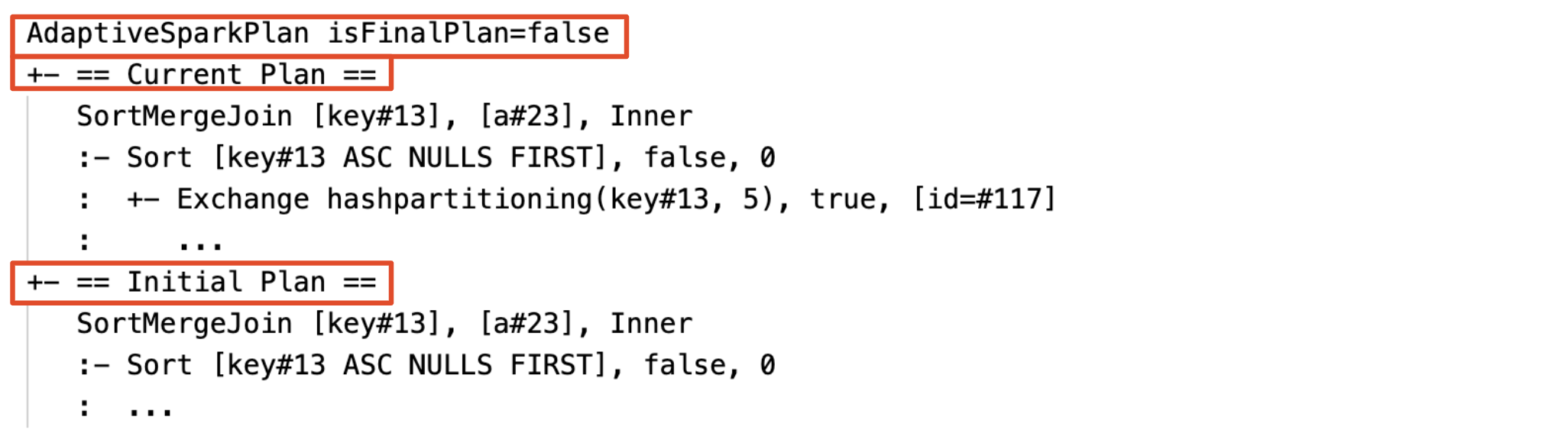
Plano atual e inicial
Em cada nó AdaptiveSparkPlan, haverá o plano inicial (o plano antes de aplicar qualquer otimização de AQE) e o plano atual ou final, dependendo se a execução foi concluída. O plano atual evoluirá à medida que a execução progride.
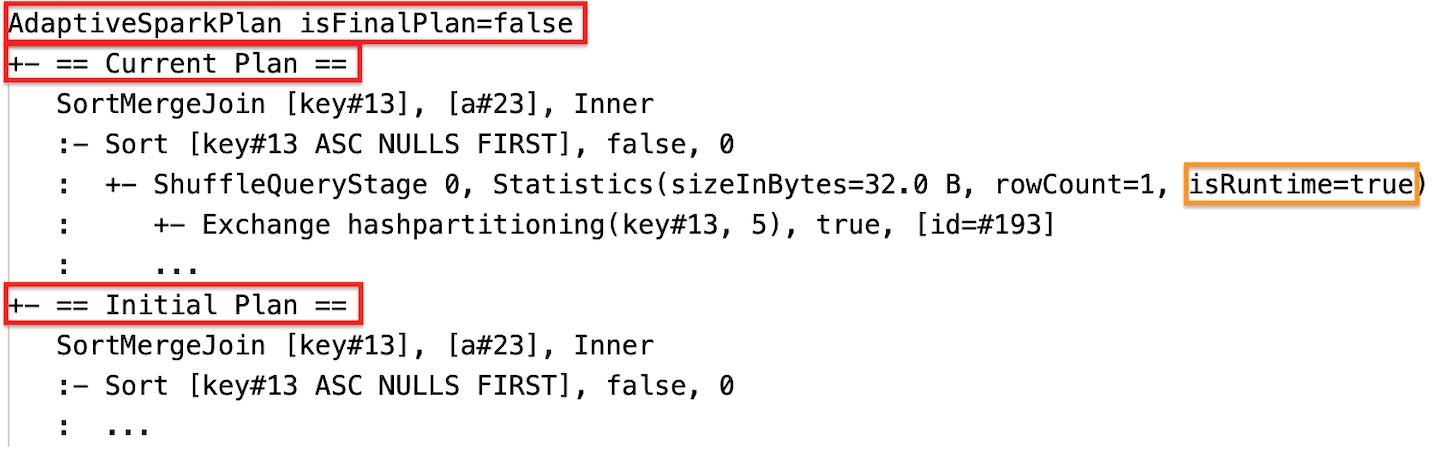
Runtime estatísticas
Cada estágio aleatório e de transmissão contém estatísticas de dados.
Antes da execução do estágio ou quando o estágio está em execução, as estatísticas são estimativas de tempo de compilação e o sinalizador isRuntime é false, por exemplo: Statistics(sizeInBytes=1024.0 KiB, rowCount=4, isRuntime=false);
Depois que a execução do estágio for concluída, as estatísticas serão coletadas em tempo de execução e o sinalizador isRuntime se tornará true, por exemplo: Statistics(sizeInBytes=658.1 KiB, rowCount=2.81E+4, isRuntime=true)
Veja a seguir um exemplo de DataFrame.explain:
-
Antes da execução
-
Durante a execução
-
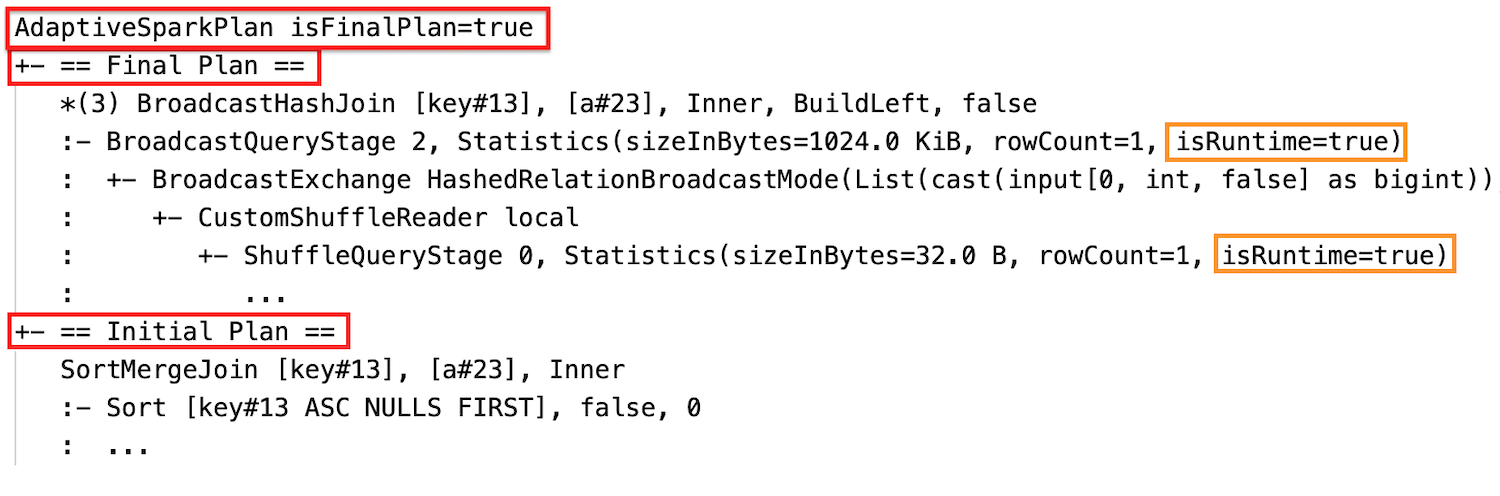
Depois da execução
SQL EXPLAIN
NodoAdaptiveSparkPlan
As consultas aplicadas ao AQE contêm um ou mais nós AdaptiveSparkPlan, geralmente como o nó raiz de cada consulta principal ou subconsulta.
Nenhum plano atual
Como o SQL EXPLAIN não executa a consulta, o plano atual é sempre igual ao plano inicial e não reflete o que acabaria sendo executado pelo AQE.
A seguir, um exemplo de explicação SQL:

Eficácia
O plano de consulta mudará se uma ou mais otimizações de AQE entrarem em vigor. O efeito dessas otimizações de AQE é demonstrado pela diferença entre os planos atual e final e o plano inicial e os nós específicos do plano nos planos atual e final.
-
Alterar dinamicamente a classificação merge join para broadcast hash join: diferentes nós físicos join entre o plano atual/final e o plano inicial
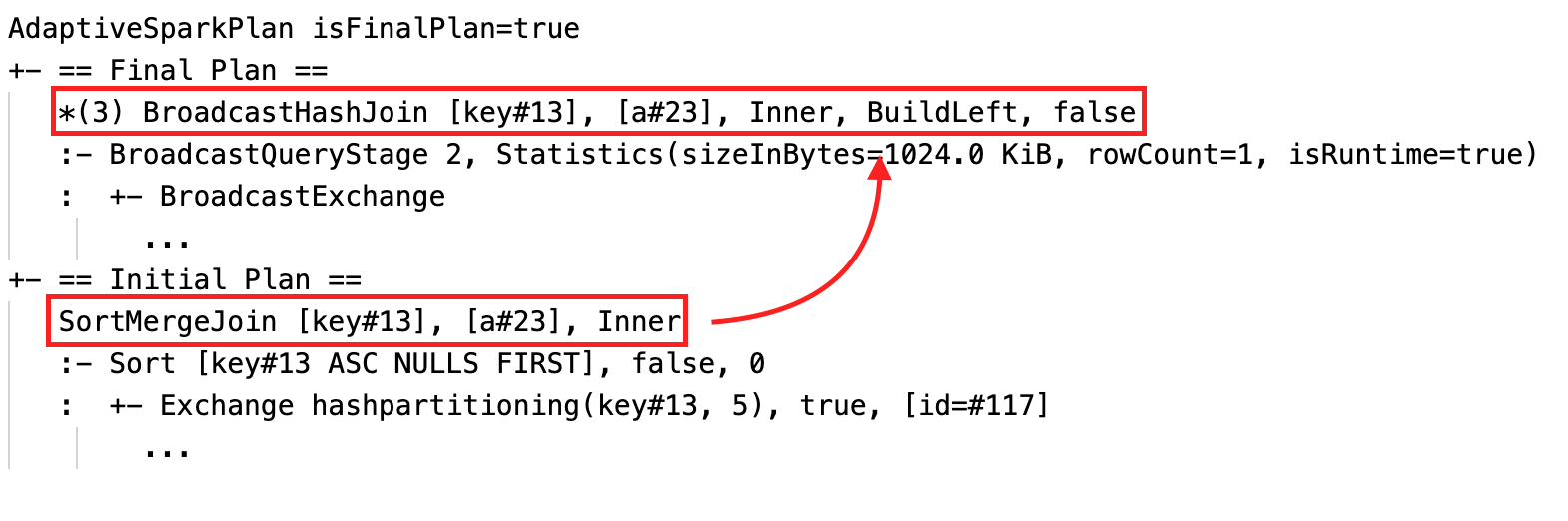
-
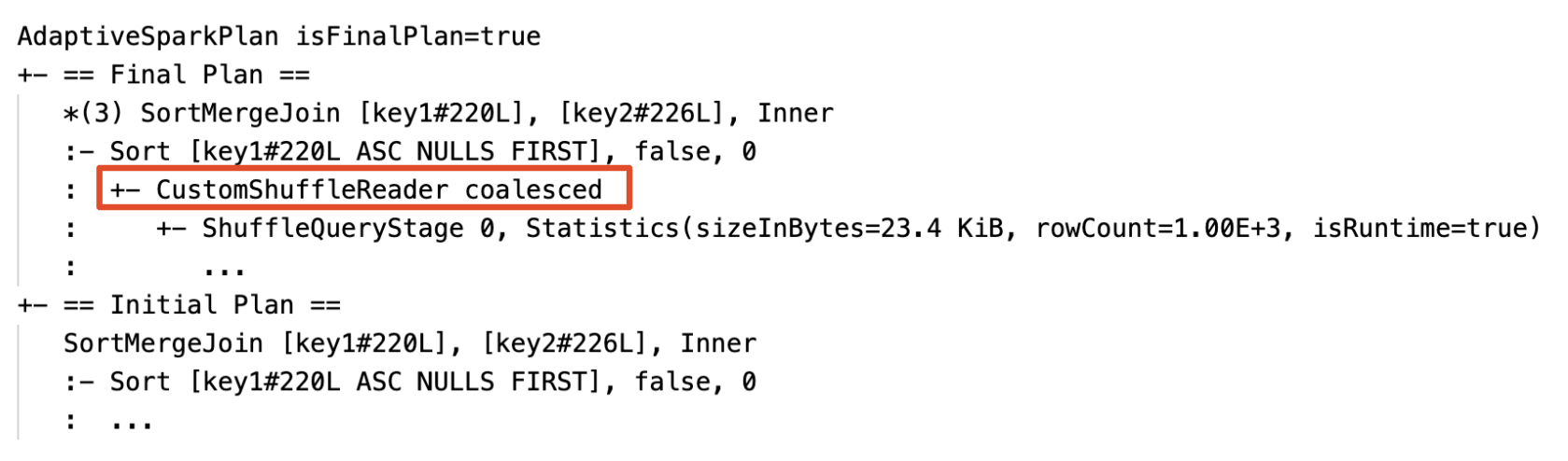
Coalesça partições dinamicamente: node
CustomShuffleReadercom propriedadeCoalesced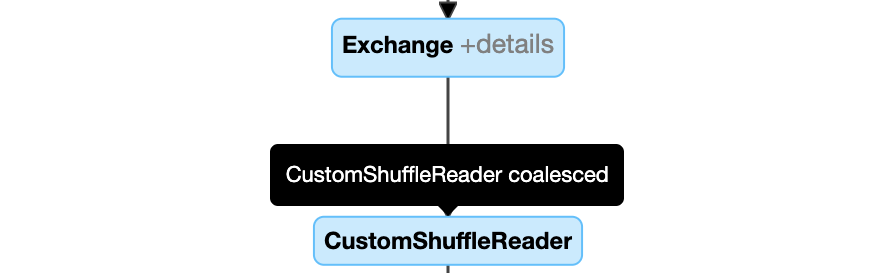
-
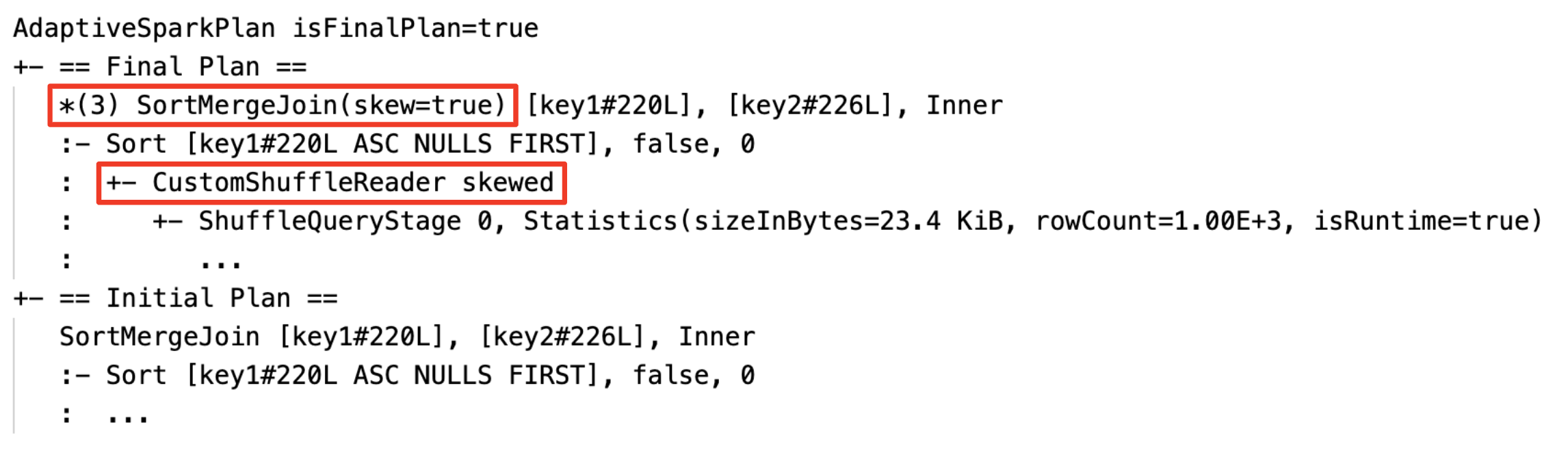
Manipular dinamicamente a inclinação join: nó
SortMergeJoincom campoisSkewcomo verdadeiro.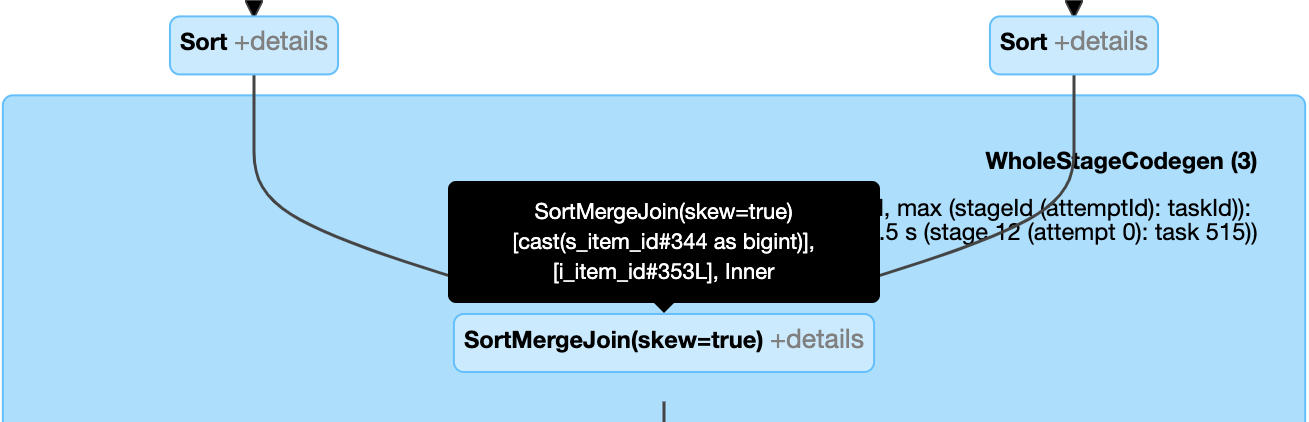
-
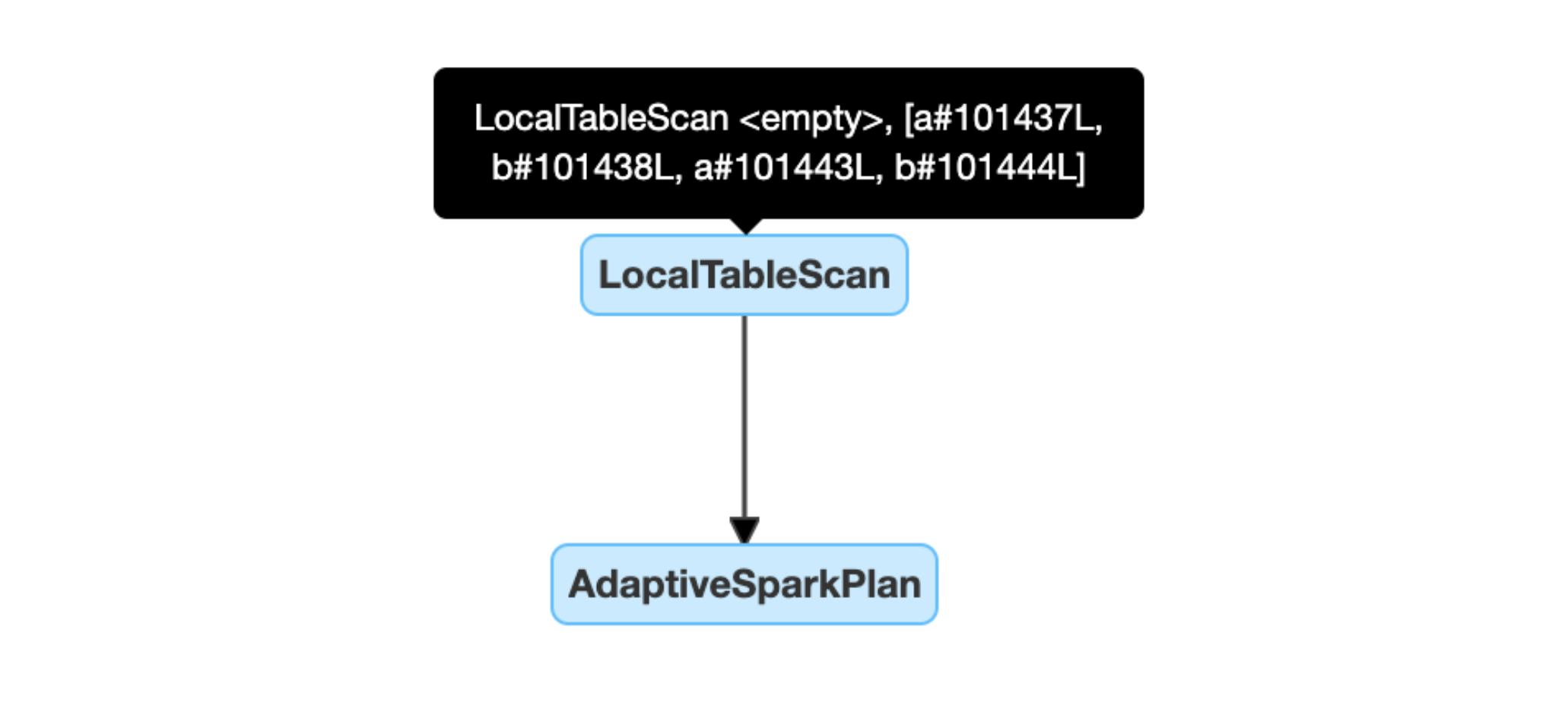
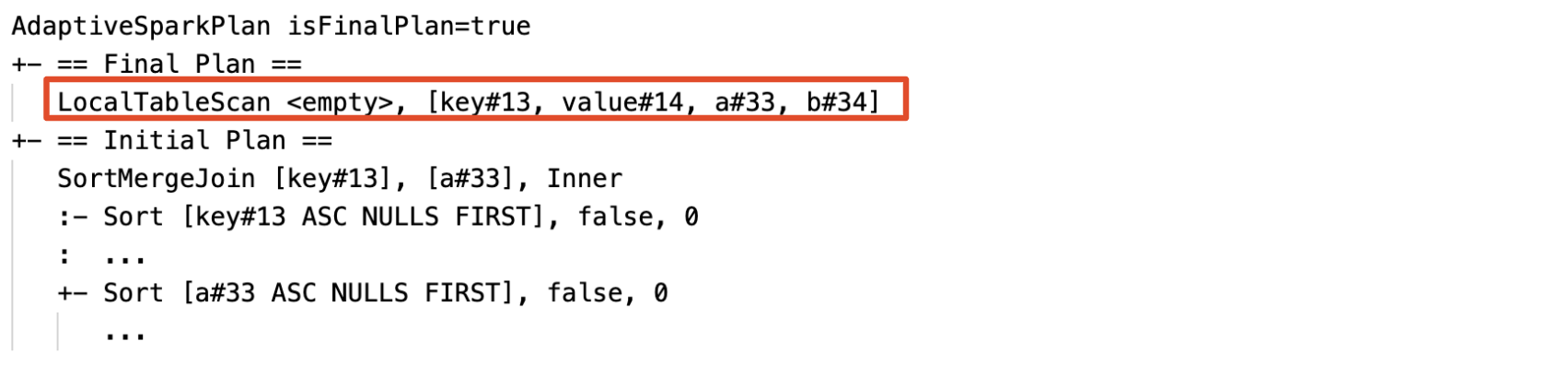
Detecte e propague dinamicamente relações vazias: parte (ou todo) do plano é substituída pelo nó LocalTableScan com o campo de relação vazio.
Configuração
Nesta secção:
- Habilitar e desabilitar a execução adaptativa de consultas
- Habilitar o shuffle otimizado automaticamente
- Alterar dinamicamente a classificação merge join em hash de transmissão join
- Coalesça partições dinamicamente
- Manipular dinamicamente a distorção join
- Detecte e propague dinamicamente relações vazias
Habilitar e desabilitar a execução adaptativa de consultas
Propriedade |
|---|
spark.databricks.optimizer.adaptive.enabled Tipo: |
Habilitar o shuffle otimizado automaticamente
Propriedade |
|---|
spark.sql.shuffle.partitions Tipo: |
Alterar dinamicamente a classificação merge join em hash de transmissão join
Propriedade |
|---|
spark.databricks.adaptive.autobroadcastJoinThreshold Tipo: |
Coalesça partições dinamicamente
Propriedade |
|---|
spark.sql.adaptive.coalescePartitions.Enabled Tipo: |
spark.sql.adaptive.advisoryTamanho da partição em bytes Tipo: |
spark.sql.adaptive.coalescepartitions.minPartitionSize Tipo: |
spark.sql.adaptive.coalescepartitions.minPartitionNum Tipo: |
Manipular dinamicamente a distorção join
Propriedade |
|---|
spark.sql.adaptive.skewJoin.Enabled Tipo: |
Spark.sql.adaptive.skewjoin.skewedPartitionFactor Tipo: |
spark.sql.adaptive.skewjoin.skewed Limite de partição em bytes Tipo: |
Uma partição é considerada distorcida quando (partition size > skewedPartitionFactor * median partition size) e (partition size > skewedPartitionThresholdInBytes) são true.
Detecte e propague dinamicamente relações vazias
Propriedade |
|---|
spark.databricks.adaptive.emptyRelationPropagation.Enabled Tipo: |
Perguntas frequentes (FAQ)
Nesta secção:
- Por que a AQE não transmitiu uma pequena tabela join?
- Ainda assim, devo usar uma dica de estratégia de transmissão join com o AQE ativado?
- Qual é a diferença entre skew join hint e AQE skew join optimization? Qual deles devo usar?
- Por que o AQE não ajustou meu pedido de join automaticamente?
- Por que o AQE não detectou minha distorção de dados?
Por que a AQE não transmitiu uma pequena tabela join?
Se o tamanho da relação que se espera que seja transmitida estiver abaixo desse limite, mas ainda assim não for transmitida:
- Verifique o tipo de join. A transmissão não é compatível com determinados tipos de join. Por exemplo, a relação esquerda de um
LEFT OUTER JOINnão pode ser transmitida. - Também pode ser que a relação contenha muitas partições vazias e, nesse caso, a maior parte da tarefa pode ser concluída rapidamente com o sort merge join ou pode ser potencialmente otimizada com o manuseio do skew join. O AQE evita alterar esse tipo merge join para broadcast hash join se a porcentagem de partições não vazias for menor que
spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoin.
Ainda assim, devo usar uma dica de estratégia de transmissão join com o AQE ativado?
Sim Um broadcast join planejado estaticamente costuma ter mais desempenho do que um planejado dinamicamente pelo AQE, pois o AQE pode não mudar para o broadcast join até depois de executar o shuffle para ambos os lados do join (momento em que os tamanhos reais das relações são obtidos). Portanto, usar uma dica de transmissão ainda pode ser uma boa escolha se você conhece bem sua consulta. O AQE respeitará as dicas de consulta da mesma forma que a otimização estática, mas ainda poderá aplicar otimizações dinâmicas que não são afetadas pelas dicas.
Qual é a diferença entre skew join hint e AQE skew join optimization? Qual deles devo usar?
Recomenda-se confiar no manuseio do AQE skew join em vez de usar a dica skew join, porque o AQE skew join é totalmente automático e, em geral, tem um desempenho melhor do que a dica correspondente.
Por que o AQE não ajustou meu pedido de join automaticamente?
A reordenação dinâmica do join não faz parte do AQE.
Por que o AQE não detectou minha distorção de dados?
Há duas condições de tamanho que devem ser satisfeitas para que o AQE detecte uma partição como uma partição distorcida:
- O tamanho da partição é maior do que
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes(default 256MB) - O tamanho da partição é maior do que o tamanho médio de todas as partições vezes o fator de partição distorcido
spark.sql.adaptive.skewJoin.skewedPartitionFactor(default 5)
Além disso, o suporte ao tratamento de inclinação é limitado para determinados tipos de join. Por exemplo, em LEFT OUTER JOIN, somente a inclinação no lado esquerdo pode ser otimizada.
Legado
O termo "Adaptive Execution" existe desde o Spark 1.6, mas o novo AQE no Spark 3.0 é fundamentalmente diferente. Em termos de funcionalidade, o Spark 1.6 faz apenas a parte de "combinar partições dinamicamente". Em termos de arquitetura técnica, o novo AQE é uma estrutura de planejamento dinâmico e replanejamento de consultas com base em estatísticas de tempo de execução, que oferece suporte a uma variedade de otimizações, como as que descrevemos neste artigo, e pode ser estendido para permitir mais otimizações em potencial.