Prepare your data for GDPR compliance
The General Data Protection Regulation (GDPR) and California Consumer Privacy Act (CCPA) are privacy and data security regulations that require companies to permanently and completely delete all personally identifiable information (PII) collected about a customer upon their explicit request. Also known as the “right to be forgotten” (RTBF) or “right to data erasure”, deletion requests must be executed during a specified period (for example, within one calendar month).
To implement RTBF on data stored in Databricks, the example in this article models datasets for an e-commerce company and shows how to delete data in source tables and propagate those changes to downstream tables.
Blueprint for implementing the “right to be forgotten”
The following diagram illustrates how to implement the “right to be forgotten.”
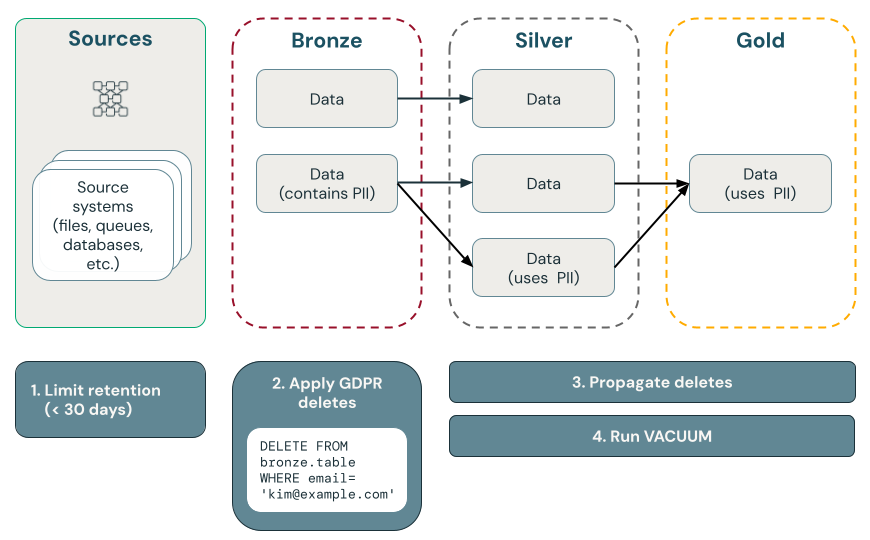
Point deletes with Delta Lake
Delta Lake speeds up point deletes in large data lakes with ACID transactions, allowing you to locate and remove personally identifiable information (PII) in response to consumer GDPR or CCPA requests.
Delta Lake retains table history and makes it available for point-in-time queries and rollbacks. The VACUUM function removes data files that are no longer referenced by a Delta table and are older than a specified retention threshold, permanently deleting the data. To learn more about defaults and recommendations, see Work with table history.
Ensure data is deleted when using deletion vectors
For tables with deletion vectors enabled, after deleting records, you must also run REORG TABLE ... APPLY (PURGE) to permanently delete underlying records. This includes Delta Lake tables, materialized views, and streaming tables. See Apply soft-deletes to data files.
Delete data in upstream sources
GDPR and CCPA apply to all data, including data in sources outside of Delta Lake, such as Kafka, files, and databases. In addition to deleting data in Databricks, you must also remember to delete data in upstream sources, such as queues and cloud storage.
Before implementing data deletion workflows, you might need to export workspace data for compliance or backup purposes. See Export workspace data.
Complete deletion is preferable to obfuscation
You have to choose between deleting data and obfuscating it. Obfuscation can be implemented using pseudonymization, data masking, etc. However, the safest option is complete erasure because, in practice, eliminating the risk of reidentification often requires a complete deletion of PII data.
Delete data in bronze layer, and then propagate deletions to silver and gold layers
We recommend that you start GDPR and CCPA compliance by deleting data in the bronze layer first, driven by a scheduled job that queries a table of deletion requests. After data is deleted from the bronze layer, changes can be propagated to silver and gold layers.
Regularly maintain tables to remove data from historical files
By default, Delta Lake retains table history, including deleted records, for 30 days, and makes it available for time travel and rollbacks. But even if previous versions of the data are removed, the data is still retained in cloud storage. Therefore, you should regularly maintain datasets to remove previous versions of data. The recommended way is Predictive optimization for Unity Catalog managed tables, which intelligently maintains both streaming tables and materialized views.
- For tables managed by predictive optimization, Lakeflow pipelines intelligently maintain both streaming tables and materialized views, based on usage patterns.
- For tables without predictive optimization enabled, Lakeflow pipelines automatically perform maintenance tasks within 24 hours of streaming tables and materialized views being updated.
If you are not using predictive optimization or Lakeflow pipelines, you should run a VACUUM command on Delta tables to permanently remove previous versions of data. By default, this reduces the time travel capabilities to 7 days, which is a configurable setting, and removes historical versions of the data in question from the cloud storage too.
Delete PII data from the bronze layer
Depending on the design of your lakehouse, you might be able to sever the link between PII and non-PII user data. For example, if you are using a non-natural key such as user_id instead of a natural key like email, you can delete PII data, which leaves non-PII data in place.
The rest of this article handles RTBF by completely deleting user records from all bronze tables. You can delete data by executing a DELETE command, as shown in the following code:
spark.sql("DELETE FROM bronze.users WHERE user_id = 5")
When deleting a large number of records together at one time, we recommend using the MERGE command. The code below assumes that you have a control table called gdpr_control_table which contains a user_id column. You insert a record into this table for every user who has requested the “right to be forgotten” into this table.
The MERGE command specifies the condition for matching rows. In this example, it matches records from target_table with records in gdpr_control_table based on the user_id. If there is a match (for example, a user_id in both the target_table and the gdpr_control_table), the row in the target_table is deleted. After this MERGE command is successful, update the control table to confirm that the request has been processed.
spark.sql("""
MERGE INTO target
USING (
SELECT user_id
FROM gdpr_control_table
) AS source
ON target.user_id = source.user_id
WHEN MATCHED THEN DELETE
""")
Propagate changes from bronze to silver and gold layers
After data is deleted in the bronze layer, you must propagate the changes to tables in the silver and gold layers.
Materialized views: Automatically handle deletions
Materialized views automatically handle deletions in sources. Hence, you do not have to do anything special to ensure that a materialized view does not contain data that has been deleted from a source. You must refresh a materialized view and run maintenance to ensure that deletions are completely processed.
A materialized view always returns the correct result because it uses incremental computation if it is cheaper than full recomputation, but never at the cost of correctness. In other words, deleting data from a source could cause a materialized view to fully recompute.
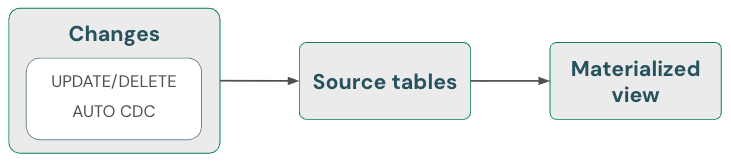
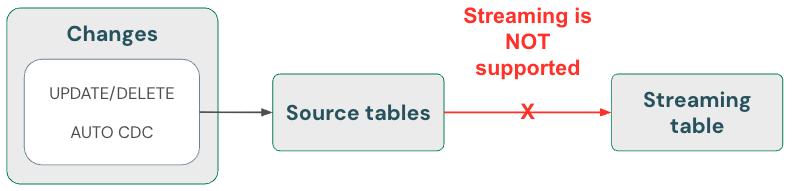
Streaming tables: Delete data and read streaming source using skipChangeCommits
Streaming tables process append-only data when they stream from Delta table sources. Any other operation, such as updating or deleting a record from a streaming source, is not supported and breaks the stream.
For a more robust streaming implementation, stream from the change feeds of Delta tables instead, and handle updates and deletes in your processing code. See Handle changes to source Delta Lake tables.
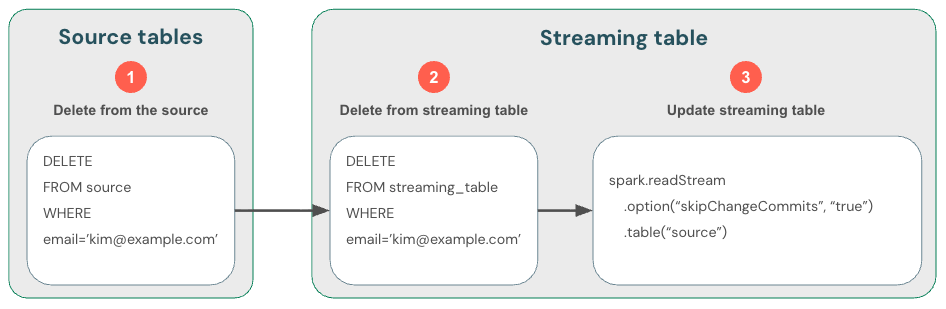
Because streaming from Delta tables handles new data only, you must handle changes to data yourself. The recommended method is to: (1) delete data in the source Delta tables using DML, (2) delete data from the streaming table using DML, and then (3) update the streaming read to use skipChangeCommits. This flag indicates that the streaming table should skip anything other than inserts, such as updates or deletes.
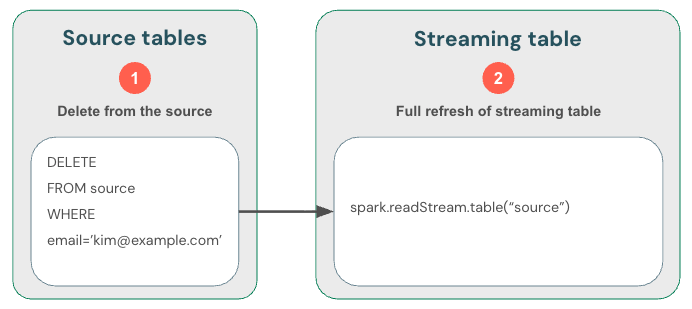
Alternatively, you can (1) delete data from the source, then (2) fully refresh the streaming table. When you fully refresh a streaming table, it clears the table's streaming state and reprocesses all data again. Any upstream data source that is beyond its retention period (for example, a Kafka topic that ages out data after 7 days) won't be processed again, which could cause data loss. We recommend this option for streaming tables only in the scenario where historical data is available and processing it again won't be costly.
Example: GDPR and CCPA compliance for an e-commerce company
The following diagram shows a medallion architecture for an e-commerce company where GDPR & CCPA compliance needs to be implemented. Even though a user's data is deleted, you might want to count their activities in downstream aggregations.
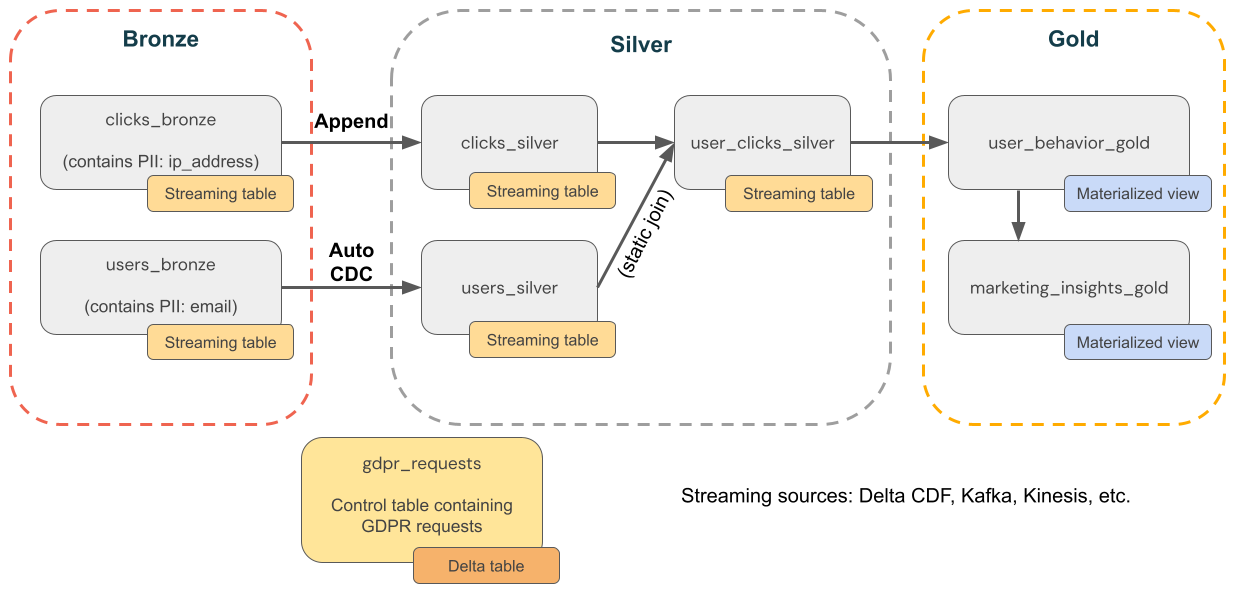
- Source tables
source_users- A streaming source table of users (created here, for the example). Production environments typically use Kafka, Kinesis, or similar streaming platforms.source_clicks- A streaming source table of clicks (created here, for the example). Production environments typically use Kafka, Kinesis, or similar streaming platforms.
- Control table
gdpr_requests- Control table containing user IDs subject to “right to be forgotten.” When a user requests to be removed, add them here.
- Bronze layer
users_bronze- User dimensions. Contains PII (for example, email address).clicks_bronze- Click events. Contains PII (for example, IP address).
- Silver layer
clicks_silver- Cleaned and standardized clicks data.users_silver- Cleaned and standardized user data.user_clicks_silver- Joinsclicks_silver(streaming) with a snapshot ofusers_silver.
- Gold layer
user_behavior_gold- Aggregated user behavior metrics.marketing_insights_gold- User segment for market insights.
Step 1: Populate tables with sample data
The following code creates these two tables for this example and populates them with sample data:
source_userscontains dimensional data about users. This table contains a PII column calledemail.source_clickscontains event data about activities performed by users. It contains a PII column calledip_address.
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, MapType, DateType
catalog = "users"
schema = "name"
# Create table containing sample users
users_schema = StructType([
StructField('user_id', IntegerType(), False),
StructField('username', StringType(), True),
StructField('email', StringType(), True),
StructField('registration_date', StringType(), True),
StructField('user_preferences', MapType(StringType(), StringType()), True)
])
users_data = [
(1, 'alice', 'alice@example.com', '2021-01-01', {'theme': 'dark', 'language': 'en'}),
(2, 'bob', 'bob@example.com', '2021-02-15', {'theme': 'light', 'language': 'fr'}),
(3, 'charlie', 'charlie@example.com', '2021-03-10', {'theme': 'dark', 'language': 'es'}),
(4, 'david', 'david@example.com', '2021-04-20', {'theme': 'light', 'language': 'de'}),
(5, 'eve', 'eve@example.com', '2021-05-25', {'theme': 'dark', 'language': 'it'})
]
users_df = spark.createDataFrame(users_data, schema=users_schema)
users_df.write.mode("overwrite").saveAsTable(f"{catalog}.{schema}.source_users")
# Create table containing clickstream (i.e. user activities)
from pyspark.sql.types import TimestampType
clicks_schema = StructType([
StructField('click_id', IntegerType(), False),
StructField('user_id', IntegerType(), True),
StructField('url_clicked', StringType(), True),
StructField('click_timestamp', StringType(), True),
StructField('device_type', StringType(), True),
StructField('ip_address', StringType(), True)
])
clicks_data = [
(1001, 1, 'https://example.com/home', '2021-06-01T12:00:00', 'mobile', '192.168.1.1'),
(1002, 1, 'https://example.com/about', '2021-06-01T12:05:00', 'desktop', '192.168.1.1'),
(1003, 2, 'https://example.com/contact', '2021-06-02T14:00:00', 'tablet', '192.168.1.2'),
(1004, 3, 'https://example.com/products', '2021-06-03T16:30:00', 'mobile', '192.168.1.3'),
(1005, 4, 'https://example.com/services', '2021-06-04T10:15:00', 'desktop', '192.168.1.4'),
(1006, 5, 'https://example.com/blog', '2021-06-05T09:45:00', 'tablet', '192.168.1.5')
]
clicks_df = spark.createDataFrame(clicks_data, schema=clicks_schema)
clicks_df.write.format("delta").mode("overwrite").saveAsTable(f"{catalog}.{schema}.source_clicks")
Step 2: Create a pipeline that processes PII data
The following code creates bronze, silver, and gold layers of the medallion architecture shown above.
from pyspark import pipelines as dp
from pyspark.sql.functions import col, concat_ws, count, countDistinct, avg, when, expr
catalog = "users"
schema = "name"
# ----------------------------
# Bronze Layer - Raw Data Ingestion
# ----------------------------
@dp.table(
name=f"{catalog}.{schema}.users_bronze",
comment='Raw users data loaded from source'
)
def users_bronze():
return (
spark.readStream.table(f"{catalog}.{schema}.source_users")
)
@dp.table(
name=f"{catalog}.{schema}.clicks_bronze",
comment='Raw clicks data loaded from source'
)
def clicks_bronze():
return (
spark.readStream.table(f"{catalog}.{schema}.source_clicks")
)
# ----------------------------
# Silver Layer - Data Cleaning and Enrichment
# ----------------------------
@dp.create_streaming_table(
name=f"{catalog}.{schema}.users_silver",
comment='Cleaned and standardized users data'
)
@dp.view
@dp.expect_or_drop('valid_email', "email IS NOT NULL")
def users_bronze_view():
return (
spark.readStream
.table(f"{catalog}.{schema}.users_bronze")
.withColumn('registration_date', col('registration_date').cast('timestamp'))
.dropDuplicates(['user_id', 'registration_date'])
.select('user_id', 'username', 'email', 'registration_date', 'user_preferences')
)
@dp.create_auto_cdc_flow(
target=f"{catalog}.{schema}.users_silver",
source="users_bronze_view",
keys=["user_id"],
sequence_by="registration_date",
)
@dp.table(
name=f"{catalog}.{schema}.clicks_silver",
comment='Cleaned and standardized clicks data'
)
@dp.expect_or_drop('valid_click_timestamp', "click_timestamp IS NOT NULL")
def clicks_silver():
return (
spark.readStream
.table(f"{catalog}.{schema}.clicks_bronze")
.withColumn('click_timestamp', col('click_timestamp').cast('timestamp'))
.withWatermark('click_timestamp', '10 minutes')
.dropDuplicates(['click_id'])
.select('click_id', 'user_id', 'url_clicked', 'click_timestamp', 'device_type', 'ip_address')
)
@dp.table(
name=f"{catalog}.{schema}.user_clicks_silver",
comment='Joined users and clicks data on user_id'
)
def user_clicks_silver():
# Read users_silver as a static DataFrame - each refresh
# will use a snapshot of the users_silver table.
users = spark.read.table(f"{catalog}.{schema}.users_silver")
# Read clicks_silver as a streaming DataFrame.
clicks = spark.readStream \
.table('clicks_silver')
# Perform the join - join of a static dataset with a
# streaming dataset creates a streaming table.
joined_df = clicks.join(users, on='user_id', how='inner')
return joined_df
# ----------------------------
# Gold Layer - Aggregated and Business-Level Data
# ----------------------------
@dp.materialized_view(
name=f"{catalog}.{schema}.user_behavior_gold",
comment='Aggregated user behavior metrics'
)
def user_behavior_gold():
df = spark.read.table(f"{catalog}.{schema}.user_clicks_silver")
return (
df.groupBy('user_id')
.agg(
count('click_id').alias('total_clicks'),
countDistinct('url_clicked').alias('unique_urls')
)
)
@dp.materialized_view(
name=f"{catalog}.{schema}.marketing_insights_gold",
comment='User segments for marketing insights'
)
def marketing_insights_gold():
df = spark.read.table(f"{catalog}.{schema}.user_behavior_gold")
return (
df.withColumn(
'engagement_segment',
when(col('total_clicks') >= 100, 'High Engagement')
.when((col('total_clicks') >= 50) & (col('total_clicks') < 100), 'Medium Engagement')
.otherwise('Low Engagement')
)
)
Step 3: Delete data in source tables
In this step, you delete data in all tables where PII is found. The following function removes all instances of a user's PII from tables with PII.
catalog = "users"
schema = "name"
def apply_gdpr_delete(user_id):
tables_with_pii = ["clicks_bronze", "users_bronze", "clicks_silver", "users_silver", "user_clicks_silver"]
for table in tables_with_pii:
print(f"Deleting user_id {user_id} from table {table}")
spark.sql(f"""
DELETE FROM {catalog}.{schema}.{table}
WHERE user_id = {user_id}
""")
Step 4: Add skipChangeCommits to definitions of affected streaming tables
In this step, you must tell the pipeline to skip non-append rows. Add the skipChangeCommits option to the following methods. You don't have to update the definitions of materialized views because they automatically handle updates and deletes.
users_bronzeusers_silverclicks_bronzeclicks_silveruser_clicks_silver
The following code shows how to update the users_bronze method:
def users_bronze():
return (
spark.readStream.option('skipChangeCommits', 'true').table(f"{catalog}.{schema}.source_users")
)
When you run the pipeline again, the update succeeds.