Building MLflow evaluation datasets
To systematically test and improve a GenAI application, you use an evaluation dataset. An evaluation dataset is a selected set of example inputs — either labeled (with known expected outputs) or unlabeled (without ground-truth answers). Evaluation datasets help you improve your app's performance in the following ways:
- Improve quality by testing fixes against known problematic examples from production.
- Prevent regressions. Create a "golden set" of examples that must always work correctly.
- Compare app versions. Test different prompts, models, or app logic against the same data.
- Target specific features. Build specialized datasets for safety, domain knowledge, or edge cases.
- Validate the app across different environments as part of LLMOps.
MLflow evaluation datasets are stored in Unity Catalog, which provides built-in versioning, lineage, sharing, and governance.
Requirements
- To create an evaluation dataset, you must have
CREATE TABLEpermissions on a Unity Catalog schema. - An evaluation dataset is attached to an MLflow experiment. If you do not already have an experiment, see Create an MLflow Experiment to create one.
Data sources for evaluation datasets
You can use any of the following to create an evaluation dataset:
- Existing traces. If you have already captured traces from a GenAI application, you can use them to create an evaluation dataset based on real-world scenarios.
- An existing dataset, or directly entered examples. This option is useful for quick prototyping or for targeted testing of specific features.
- Synthetic data. Databricks can automatically generate a representative evaluation set from your documents, allowing you to quickly evaluate your agent with good coverage of test cases.
This page describes how to create an MLflow evaluation dataset. You can also use other types of datasets, such as Pandas DataFrames or a list of dictionaries. See MLflow evaluation examples for GenAI for examples.
Create a dataset using the UI
Follow these steps to use the UI to create a dataset from existing traces. For reference information, see MLflow evaluation dataset UI.
-
Click Experiments in the sidebar to display the Experiments page.
-
Click on the name of your experiment to open it.
-
In the left sidebar, click Traces.
-
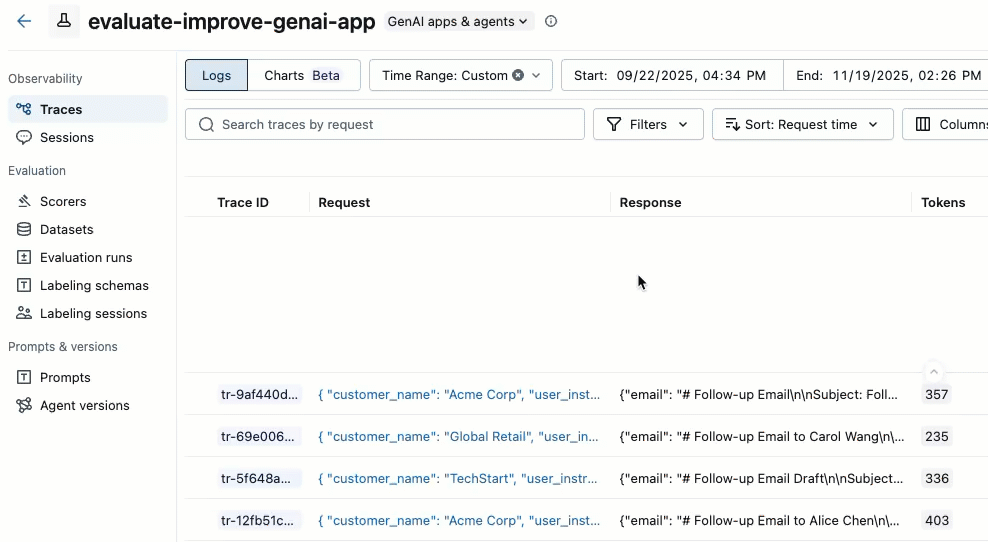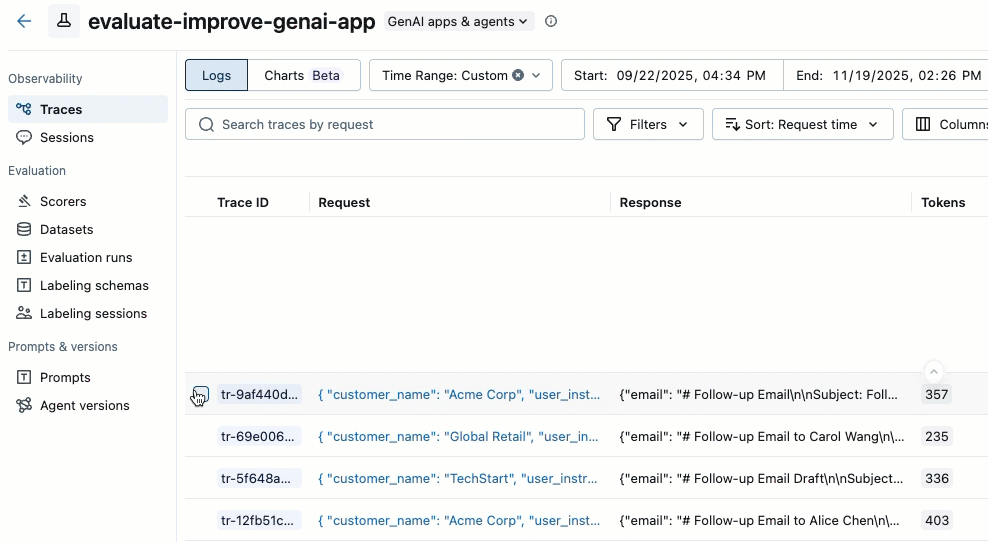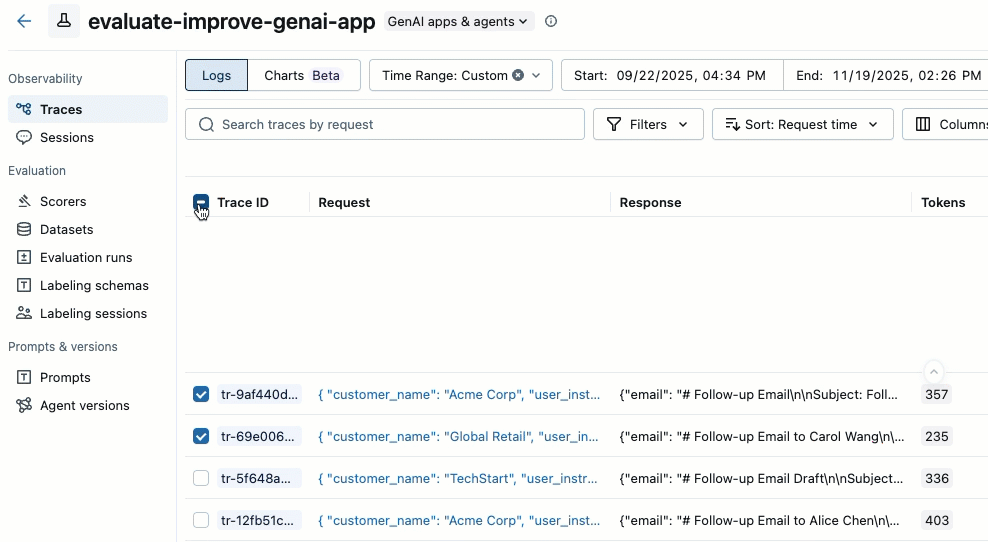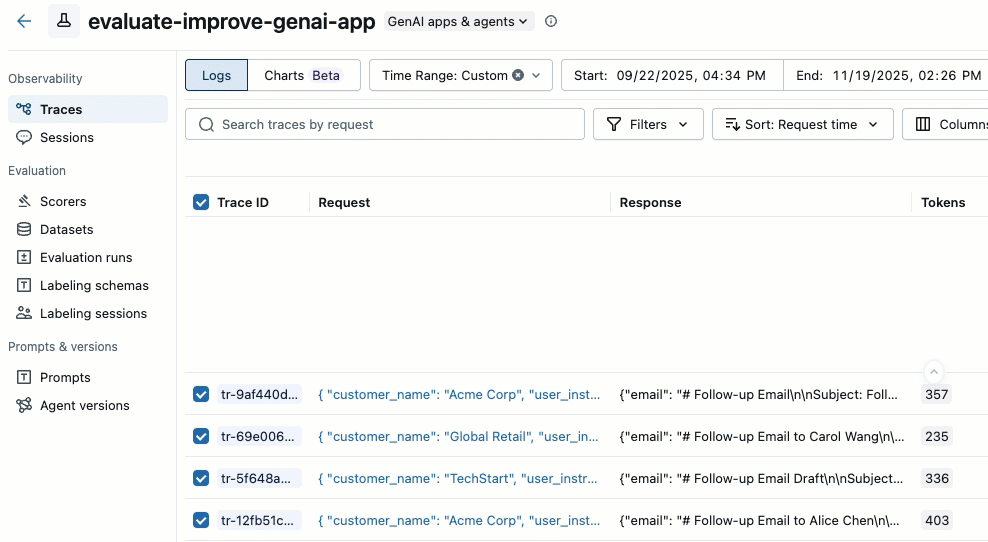
Use the checkboxes on the left side of the trace list to select the traces you want to add. To select all traces on the current page, click the checkbox next to Trace ID in the column header.
-
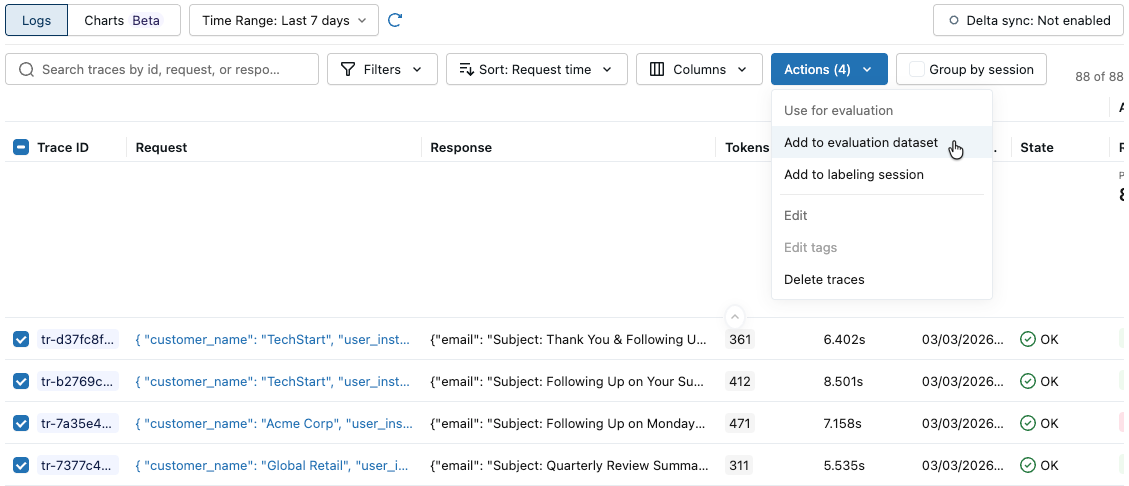
Click Actions. The button label shows the number of selected traces, for example Actions (3).
-
Under Use for evaluation, select Add to evaluation dataset. The Add traces to evaluation dataset dialog opens.
-
If no evaluation datasets exist for this experiment, or if you want to add traces to a new dataset, follow these steps to create a new evaluation dataset:
- Click Create new dataset.
- Select the Unity Catalog schema to hold the new dataset.
- Enter a name for the dataset and click Create Dataset.
- Click Export and then click Done.
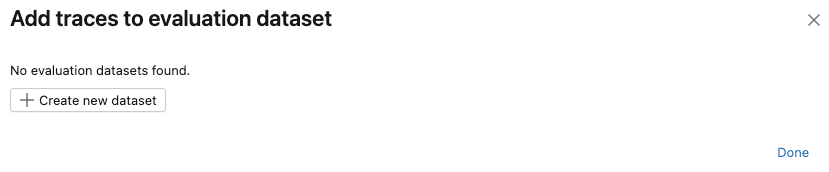
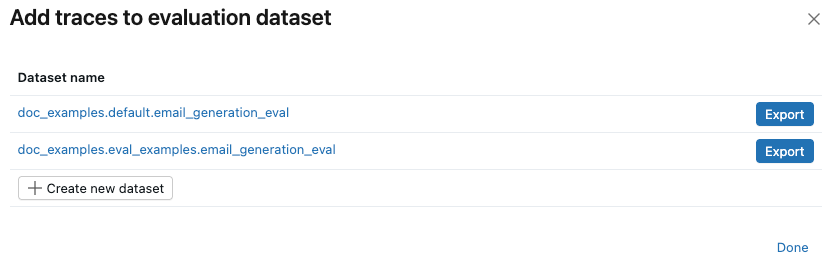
If evaluation datasets already exist for the experiment, click Export to the right of the dataset you want to add the traces to. You can export to more than one dataset. When you've finished exporting, click Done.
Create a dataset using the SDK
Follow these steps to use the SDK to create a dataset. For reference information, see Evaluation dataset reference.
Step 1. Create the dataset
import mlflow
import mlflow.genai.datasets
import time
from databricks.connect import DatabricksSession
# 0. If you are using a local development environment, connect to Serverless Spark which powers MLflow's evaluation dataset service
spark = DatabricksSession.builder.remote(serverless=True).getOrCreate()
# 1. Create an evaluation dataset
# Replace with a Unity Catalog schema where you have CREATE TABLE permission
uc_schema = "workspace.default"
# This table will be created in the above UC schema
evaluation_dataset_table_name = "email_generation_eval"
eval_dataset = mlflow.genai.datasets.create_dataset(
name=f"{uc_schema}.{evaluation_dataset_table_name}",
)
print(f"Created evaluation dataset: {uc_schema}.{evaluation_dataset_table_name}")
Step 2: Add records to your dataset
This section describes several options for adding records to the evaluation dataset.
- From existing traces
- From domain expert labels
- Build from scratch or import existing
- Seed using synthetic data
- For conversation simulation
One of the most effective ways to build a relevant evaluation dataset is by curating examples directly from your application's historical interactions captured by MLflow Tracing. You can create datasets from traces using either the MLflow Monitoring UI or the SDK.
Programmatically search for traces and then add them to the dataset using search_traces(). Use filters to identify traces by success, failure, use in production, or other properties. See Search traces programmatically.
import mlflow
# 2. Search for traces
traces = mlflow.search_traces(
filter_string="attributes.status = 'OK'",
order_by=["attributes.timestamp_ms DESC"],
tags.environment = 'production',
max_results=10
)
print(f"Found {len(traces)} successful traces")
# 3. Add the traces to the evaluation dataset
eval_dataset = eval_dataset.merge_records(traces)
print(f"Added {len(traces)} records to evaluation dataset")
# Preview the dataset
df = eval_dataset.to_df()
print(f"\nDataset preview:")
print(f"Total records: {len(df)}")
print("\nSample record:")
sample = df.iloc[0]
print(f"Inputs: {sample['inputs']}")
Select traces for evaluation datasets
Before adding traces to your dataset, identify which traces represent important test cases for your evaluation needs. You can use both quantitative and qualitative analysis to select representative traces.
Quantitative trace selection
Use the MLflow UI or SDK to filter and analyze traces based on measurable characteristics:
- In the MLflow UI: Filter by tags (e.g.,
tag.quality_score < 0.7), search for specific inputs/outputs, sort by latency or token usage - Programmatically: Query traces to perform advanced analysis
import mlflow
import pandas as pd
# Search for traces with potential quality issues
traces_df = mlflow.search_traces(
filter_string="tag.quality_score < 0.7",
max_results=100
)
# Analyze patterns
# For example, check if quality issues correlate with token usage
correlation = traces_df["span.attributes.usage.total_tokens"].corr(traces_df["tag.quality_score"])
print(f"Correlation between token usage and quality: {correlation}")
For complete trace query syntax and examples, see Search traces programmatically.
Qualitative trace selection
Review individual traces to identify patterns requiring human judgment:
- Examine inputs that led to low-quality outputs
- Look for patterns in how your application handled edge cases
- Identify missing context or faulty reasoning
- Compare high-quality vs. low-quality traces to understand differentiating factors
Once you've identified representative traces, add them to your dataset using the search and merge methods described above.
Enrich your traces with expected outputs or quality indicators to enable ground truth comparison. See collect domain expert feedback to add human labels.
Leverage feedback from domain experts captured in MLflow labeling sessions to enrich your evaluation datasets with ground truth labels. Before doing these steps, follow the collect domain expert feedback guide to create a labeling session.
import mlflow.genai.labeling as labeling
# Get a labeling sessions
all_sessions = labeling.get_labeling_sessions()
print(f"Found {len(all_sessions)} sessions")
for session in all_sessions:
print(f"- {session.name} (ID: {session.labeling_session_id})")
print(f" Assigned users: {session.assigned_users}")
# Sync from the labeling session to the dataset
all_sessions[0].sync(dataset_name=f"{uc_schema}.{evaluation_dataset_table_name}")
After collecting expert feedback, you can align judges to match the human feedback. See Align judges with humans.
You can import an existing dataset or curate examples from scratch. Your data must match (or be transformed to match) the evaluation dataset schema.
# Define comprehensive test cases
evaluation_examples = [
{
"inputs": {"question": "What is MLflow?"},
"expected": {
"expected_response": "MLflow is the largest open source AI engineering platform for agents, LLMs, and ML models.",
"expected_facts": [
"open source AI engineering platform",
"agents, LLMs, and ML models",
"experiment tracking",
"model deployment"
]
},
},
]
eval_dataset = eval_dataset.merge_records(evaluation_examples)
Generating synthetic data can expand your testing efforts by quickly creating diverse inputs and covering edge cases. See Synthesize evaluation sets.
To enable reproducible multi-turn testing, use code similar to the following to store test cases for conversation simulation. For complete documentation on simulating multi-turn conversations, see Conversation simulation.
from mlflow.genai.datasets import create_dataset, get_dataset
from mlflow.genai.simulators import ConversationSimulator
# Create a dataset for simulation test cases
dataset = create_dataset(
name="conversation_scenarios",
tags={"type": "simulation", "agent": "support-bot"},
)
# Define test cases with goals and personas
simulation_test_cases = [
{
"inputs": {
"goal": "Get help setting up experiment tracking",
"persona": "You are a data scientist new to MLflow",
},
},
{
"inputs": {
"goal": "Debug a model deployment error",
"persona": "You are a senior engineer who expects precise answers",
},
},
{
"inputs": {
"goal": "Understand model versioning best practices",
"persona": "You are building an ML platform for your team",
"context": {"team_size": "large", "compliance": "strict"},
},
},
]
dataset.merge_records(simulation_test_cases)
# Later, use the dataset with ConversationSimulator
dataset = get_dataset(name="conversation_scenarios")
simulator = ConversationSimulator(test_cases=dataset)
Update existing datasets
You can use the UI or the SDK to update an evaluation dataset.
- Databricks UI
- MLflow SDK
Use the UI to add records to an existing evaluation dataset.
-
Open the dataset page in the Databricks workspace:
- In the Databricks workspace, navigate to your experiment.
- In the sidebar at left, click Datasets.
- Click on the name of the dataset in the list.
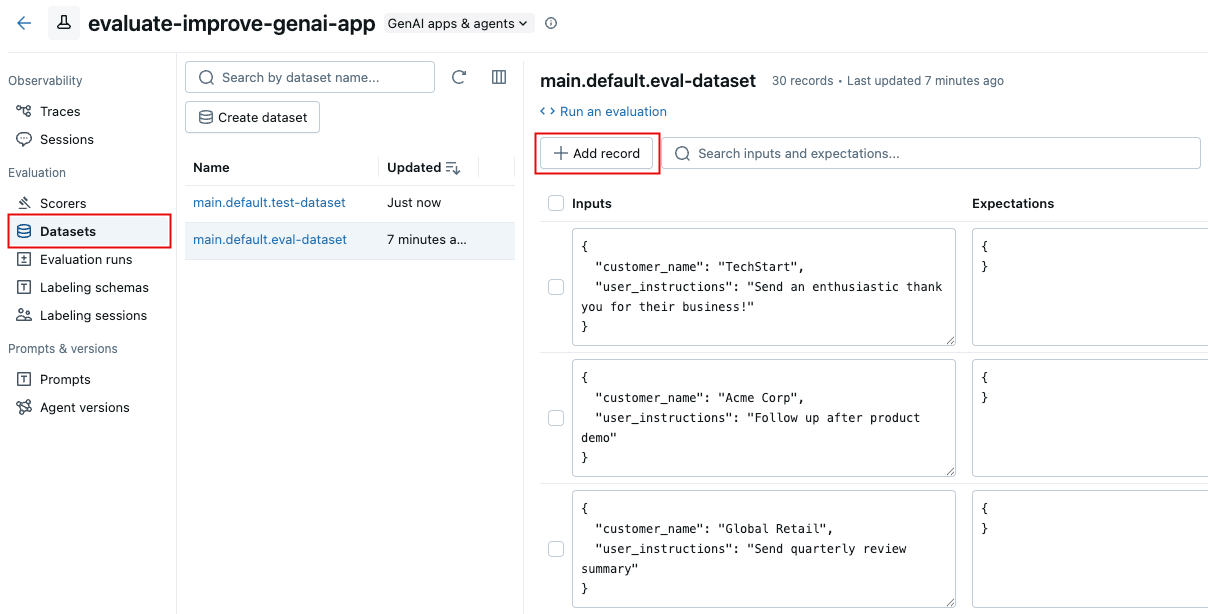
-
Click Add record. A new row appears with generic content.
-
Edit the new row directly to enter the input and expectations for the new record. Optionally, set any tags for the new record.
-
Click Save changes.
Use the MLflow SDK to update and existing evaluation dataset:
import mlflow.genai.datasets
import pandas as pd
# Load existing dataset
dataset = mlflow.genai.datasets.get_dataset(name="catalog.schema.eval_dataset")
# Add new test cases
new_cases = [
{
"inputs": {"question": "What are MLflow models?"},
"expectations": {
"expected_facts": ["model packaging", "deployment", "registry"],
"min_response_length": 100
}
}
]
# Merge new cases
dataset = dataset.merge_records(new_cases)
Limitations
- Customer Managed Keys (CMK) are not supported.
- Maximum of 2000 rows per evaluation dataset.
- Maximum of 20 expectations per dataset record.
If you need any of these limitations relaxed for your use case, contact your Databricks representative.
Next steps
- Evaluate your app - Use your newly created dataset for evaluation
- Create custom judges - Build custom LLM judges to evaluate your application outputs
- Align judges with feedback - Continuously improve your evaluations by aligning judges with expert feedback
- Query traces via SDK - Advanced programmatic trace analysis for dataset selection