異常検出
プレビュー
この機能は パブリック プレビュー段階です。
このページでは、異常検出とは何か、何を監視するのか、そしてどのように使用するのかについて説明します。
異常検出では、デフォルトストレージを使用してスキャン結果をsystem.data_quality_monitoring.table_resultsシステムテーブルに保存します。 このストレージに対しては料金は発生しません。
異常検出とは何ですか?
異常検知機能を使用すると、スキーマ内のすべてのテーブルにわたるデータ品質を監視できます。Databricksは、過去のパターンを分析することで、各テーブルの完全性と最新性を自動的に評価します。結果はカタログエクスプローラーで確認できます。
要件
- Unity Catalog対応ワークスペースであること。
- サーバーレス コンピュートはワークスペースで利用できる必要があります ( Unity Catalogを使用してワークスペースで確実に有効になります)。
- スキーマで異常検出を有効にするには、カタログ スキーマに対する MANAGE SCHEMA または MANAGE CATALOG 権限が必要です。
- テーブルの健全性インジケーターの状態を表示するには、SELECT または BROWSE 権限が必要です。
異常検出はどのように機能しますか?
Databricksは、テーブルの 鮮度 と 完全性 を監視するバックグラウンドジョブを作成します。
鮮度 とは、テーブルがどれくらい最近更新されたかを指します。データ品質モニタリングは、テーブルへのコミットの履歴を分析し、テーブルごとのモデルを構築して、次のコミットの時間を予測します。 コミットが異常に遅い場合、テーブルは古いものとしてマークされます。
完全性 とは、過去 24 時間にテーブルに書き込まれると予想される行数を指します。データ品質モニタリングは、過去の行数を分析し、このデータに基づいて、予想される行数の範囲を予測します。 過去 24 時間にコミットされたローの数がこの範囲の下限より小さい場合、テーブルは未完了としてマークされます。
Databricksは、インテリジェントスキャンを使用してテーブルのスキャン頻度を自動化します。インテリジェントスキャンは、人気度や下流での使用状況に基づいて影響度の高いテーブルを優先的にスキャンし、重要度の低いテーブルのスキャン頻度を低減します。テーブルを手動で除外するには、モニターの作成またはモニターの更新APIを使用し、 excluded_table_full_namesパラメーターで除外するテーブルを指定します。詳細については、 APIドキュメントを参照してください。
異常検出では、監視するテーブルは 変更されず 、これらのテーブルにデータを入力するジョブにオーバーヘッドが追加されることもありません。
イベントの鮮度は、イベント時間の列と取り込みの待ち時間に基づいており、データ品質モニタリング ベータ版のユーザーのみが利用できました。 現在のバージョンでは、イベントの鮮度はサポートされていません。
完全性のためのパーセントヌル
ベータ版
この機能はベータ版です。ワークスペース管理者は、 プレビュー ページからこの機能へのアクセスを制御できます。「Databricks プレビューの管理」を参照してください。
パーセント null は、 完全性の ために追加の品質詳細を追加します。パーセント NULL は、過去 24 時間にテーブルに書き込まれた行のうち、特定の列に NULL 値があると予想される行の割合です。データ品質モニタリングでは、各列の履歴傾向を分析し、このデータに基づいて範囲を予測します。 過去 24 時間の列の NULL の割合がこの範囲の上限よりも高い場合、テーブルは不完全としてマークされます。
スキーマで異常検出を有効にする
スキーマで異常検出を有効にするには、 Unity Catalog内のスキーマに移動します。
-
スキーマ ページで、 [詳細] タブをクリックします。

-
[有効にする] をクリックします。 [データ品質モニタリング] ダイアログで、 異常検出が オンになっていることを確認し、 [保存] をクリックします。
-
スキャンが開始されます。Databricks 、各テーブルを更新の頻度と同じ頻度で自動的にスキャンし、各テーブルを手動で構成しなくても最新の情報を提供します。 2025 年 9 月 24 日より前に有効になっていたスキーマの場合、 Databricks最初のスキャンでヒストリカルデータのモニター (「バックテスト」) を実行し、2 週間前にスキーマでデータ品質モニタリングが有効になっていたかのようにテーブルの品質をチェックしました。
-
スキャンが完了したら、テーブルの異常検出結果を以下の方法で確認できます。
- スキーマ内の各テーブルについて、カタログエクスプローラーに健全性指標が表示されます。健康指標を参照してください。
- データ品質モニタリング が有効になっているスキーマの [詳細] タブで、 [結果の表示] をクリックし、 データ品質モニタリング で結果を表示します。 「UI でのデータ品質モニタリング結果の表示」を参照してください。
- 検出された品質問題は、出力システムテーブルに記録されます。異常検知ログ結果の確認を参照してください。
異常検出を無効にする
異常検出を無効にするには:
-
鉛筆アイコンをクリックします。
![詳細タブの [詳細] フィールドにある鉛筆アイコン。](/aws/ja/assets/images/pencil-icon-1653e5c65900cda8121473a353380e01.png)
-
「データ品質モニタリング」 ダイアログで、トグルをクリックします。
異常検出を無効にすると、異常検出ジョブとすべての異常検出テーブルおよび情報が削除されます。この操作は元に戻せません。
 3. 保存 をクリックします。
3. 保存 をクリックします。
健康指標
スキーマで異常検出を有効にすると、カタログエクスプローラーのスキーマおよびテーブルの概要ページに健全性インジケーターが表示されます。ヘルスインジケーターは、データコンシューマーとビジネスユーザーがデータ品質のUIに移動することなく、テーブルのヘルスの概要を表示します。 ユーザーが健康状態指標のステータスを表示するには、SELECTまたはBROWSE権限が必要です。
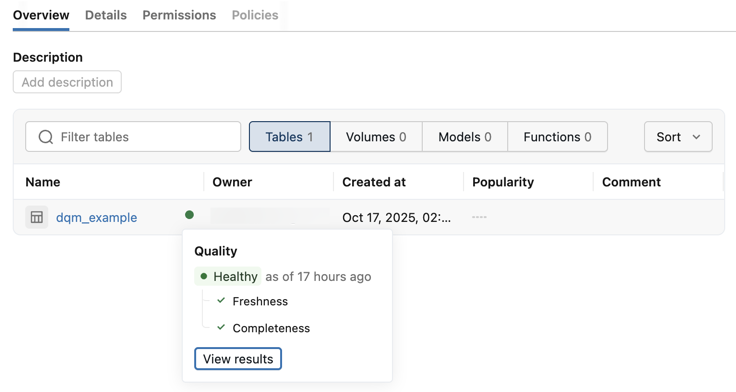
以下の表は、各健康指標の状態を示しています。
ステータス | 説明 |
|---|---|
良好 | 最新のスキャンでは、すべての異常検知チェックに合格しました。 |
異常あり | 1つ以上のチェックで、鮮度や完全性の問題など、異常が検出されました。 |
トレーニング | 異常検出では、履歴データからベースライン モデルを構築します。 新たに監視対象となったテーブルは、モデルが品質を評価するのに十分なデータを取得するまで、このステータスを表示します。 |
エラー | このテーブルの監視中に異常検出でエラーが発生しました。 |
除外 | このテーブルは異常検知の対象から明示的に除外されています。 |
有効になっていません | このテーブルを含むスキーマでは、異常検知が有効になっていません。 |
スマートスキャンでは、最初のスキャン時にテーブルがスキップされた場合、一部のテーブルの健康指標のデータ入力が最大2週間遅れる可能性があります。健康状態を示す指標は、次回の定期スキャン時に表示されます。
データ品質モニタリング結果を UI で表示する
2025 年 10 月 7 日、 Databricksデータ品質モニタリング UI の新しいバージョンをリリースしました。 その日以降にデータ品質モニタリングが有効になったスキーマは、この新しい UI を自動的に使用します。 このセクションでは、UIの最新バージョンについて説明します。
レガシー UI の詳細については、 「データ品質ダッシュボード (レガシー)」を参照してください。
Databricksは、既存のすべてのスキーマで新しいバージョンを有効にすることを推奨します。
新しいバージョンを有効にするには、 [データ品質] トグルをクリックして機能をオフにし、もう一度クリックしてオンに戻します。
スキーマでデータ品質モニタリングを有効にすると、 [結果の表示] をクリックして結果ページを開くことができます。 カタログ エクスプローラーでモニタリングが有効になっているすべてのスキーマの結果にアクセスすることもできます。
結果 UI には、カタログとスキーマのドロップダウンが含まれています。カタログを選択すると、スキーマのドロップダウンに、データ品質モニタリングが有効になっているそのカタログ内のスキーマが表示されます。
-
カタログに対する MANAGE または SELECT 権限を持っている場合は、カタログ レベルでインシデントを表示できます。カタログ内のすべてのインシデントを表示するには、 「スキーマ」 ドロップダウン メニューから 「すべてのスキーマ」 を選択します。

-
特定のスキーマのインシデントを表示するには、そのスキーマに対する MANAGE または SELECT 権限も必要です。スキーマを選択すると、そのスキーマのインシデントのみが表示されます。
結果ページの上部には概要セクションが表示され、正常なテーブルの割合や現在監視されているスキーマ/テーブルの割合など、選択したスコープの全体的なデータ品質が表示されます。このセクションの下には、選択したスコープ内のすべての監視対象テーブルのインシデントをリストする表があります。ボタンを使用して、 異常 、 正常 、または エラー テーブルを表示します。
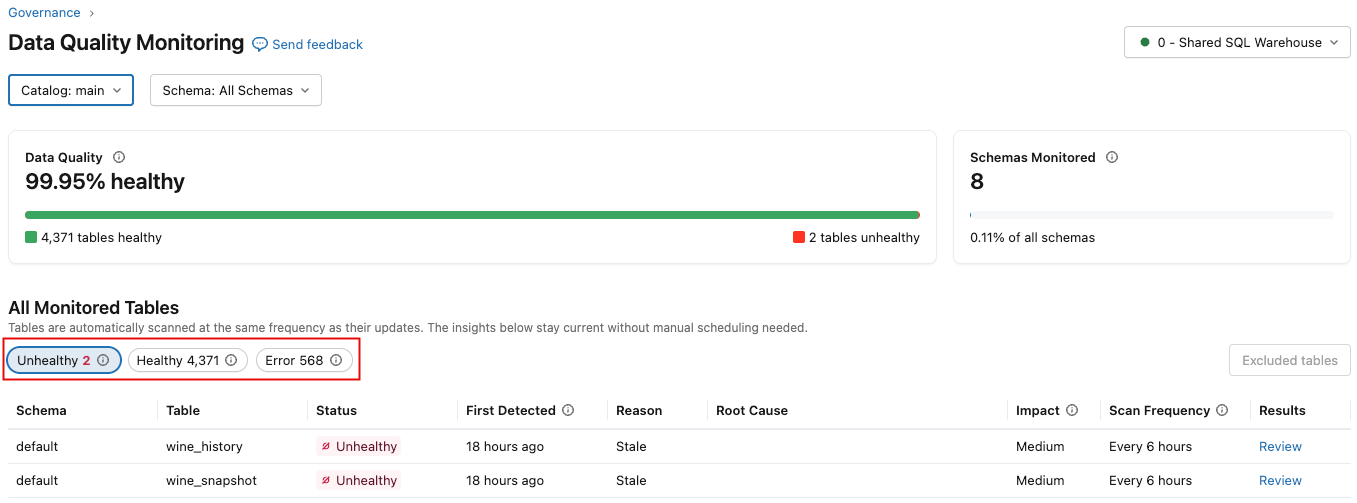
次の表では、列について説明します。列は、 [Unhealthy] 、 [Healthy] 、または [Error] のいずれを選択するかによって若干異なります。
列 | 説明 |
|---|---|
ステータス |
|
最初の検出 | 最初のインシデントが検出された時。 「不健康」 タブにのみ表示されます。 |
最終スキャン | テーブルが最後にスキャンされた日時。 [健康] タブにのみ表示されます。 |
理由: | テーブルが新鮮さや完全性のために不健康であるかどうか。 「不健康」 タブにのみ表示されます。 |
根本原因 | 問題の原因となっている上流ジョブに関する情報 (詳細については、「異常検出のログに記録された結果を確認する」を参照してください)。 「不健康」 タブにのみ表示されます。 |
インパクト | 影響を受けるダウンストリーム テーブルとクエリの数に基づいた、ダウンストリームの影響の質的尺度 ( 高 、 中 、または 低 )。 |
スキャン頻度 | 過去 1 週間にテーブルがスキャンされた頻度。 |
結果 | 異常が検出された理由を説明する履歴傾向と視覚化を表示できるテーブル品質ページへのリンク。 |
エラー状態 | エラーメッセージ。 エラー タブにのみ表示されます。 |
詳細 | エラー メッセージの詳細。 エラー タブにのみ表示されます。 |
最近解決された事件を表示する
ベータ版
この機能はベータ版です。ワークスペース管理者は、 プレビュー ページからこの機能へのアクセスを制御できます。「Databricks プレビューの管理」を参照してください。
データ品質ダッシュボードの「 最近解決されたインシデント」 セクションには、以前は異常だったものの、その後自然に回復したテーブルが表示されます。 このセクションには、状態が 「不健康」 から 「健康」 に自動的に変更された際に、手動操作なしで表が表示されます。

最近自動解決されたインシデントをモニタリングすると、自己修復するデータ品質の問題を特定するのに役立ちます。 通常、これらの問題は、上流側の遅延やデータの陳腐化期間など、一時的な問題であり、新しいデータが到着すれば解消されます。自動解決されたインシデントをレビューすることで、一時的な問題と継続的な問題を区別することができ、テーブルの健全性を長期にわたって維持することができます。
以下の表は、このセクションの列について説明しています。
列 | 説明 |
|---|---|
スキーマ | テーブルを含むスキーマ。 |
テーブル | テーブルの名前。 |
ステータス | テーブルの現在の状態。このセクションの表は常に 「健康」 を示しています。 |
解決方法 | その事件はどのように解決されたのか。 自動解決された 結果を表示します。 |
解決済み | テーブルの状態が最後に 「正常」 に変更された時刻。 |
インパクト | 下流への影響を定性的に評価する指標( 高 、 中 、 低 )。影響を受ける下流のテーブルとクエリの数に基づいて算出されます。 |
結果 | テーブルの品質ページへのリンクです。このページでは、テーブルの過去の傾向や視覚化データを確認できます。 |
メタストアレベルの結果を表示する
このセクションでは、ワークスペースにインポートできるテンプレートを提供します。このテンプレートは、メタストア全体のすべての品質結果を表示できるダッシュボードを作成します。
このテンプレートを使用するには、 system.data_quality_monitoring.table_resultsテーブルへのアクセス権が必要です。デフォルトでは、アカウント管理者のみがこのテーブルにアクセスできます。必要に応じて他のユーザーにアクセス権を付与できます。
テンプレートの使い方
以下の手順に従います。
- テンプレート ファイルをダウンロードします: metastore-quality-dashboard.lvdash. JSON 。
- ワークスペースサイドバーで、
 ダッシュボード 。
ダッシュボード 。 - 右上隅の 「ダッシュボードの作成」 ドロップダウン メニューから 「ファイルからダッシュボードをインポート」 を選択します。
- ダイアログで、 「ファイルの選択」 をクリックし、テンプレート ファイルに移動して、 「ダッシュボードのインポート」 をクリックします。
ファイルがインポートされ、ダッシュボードが表示されます。
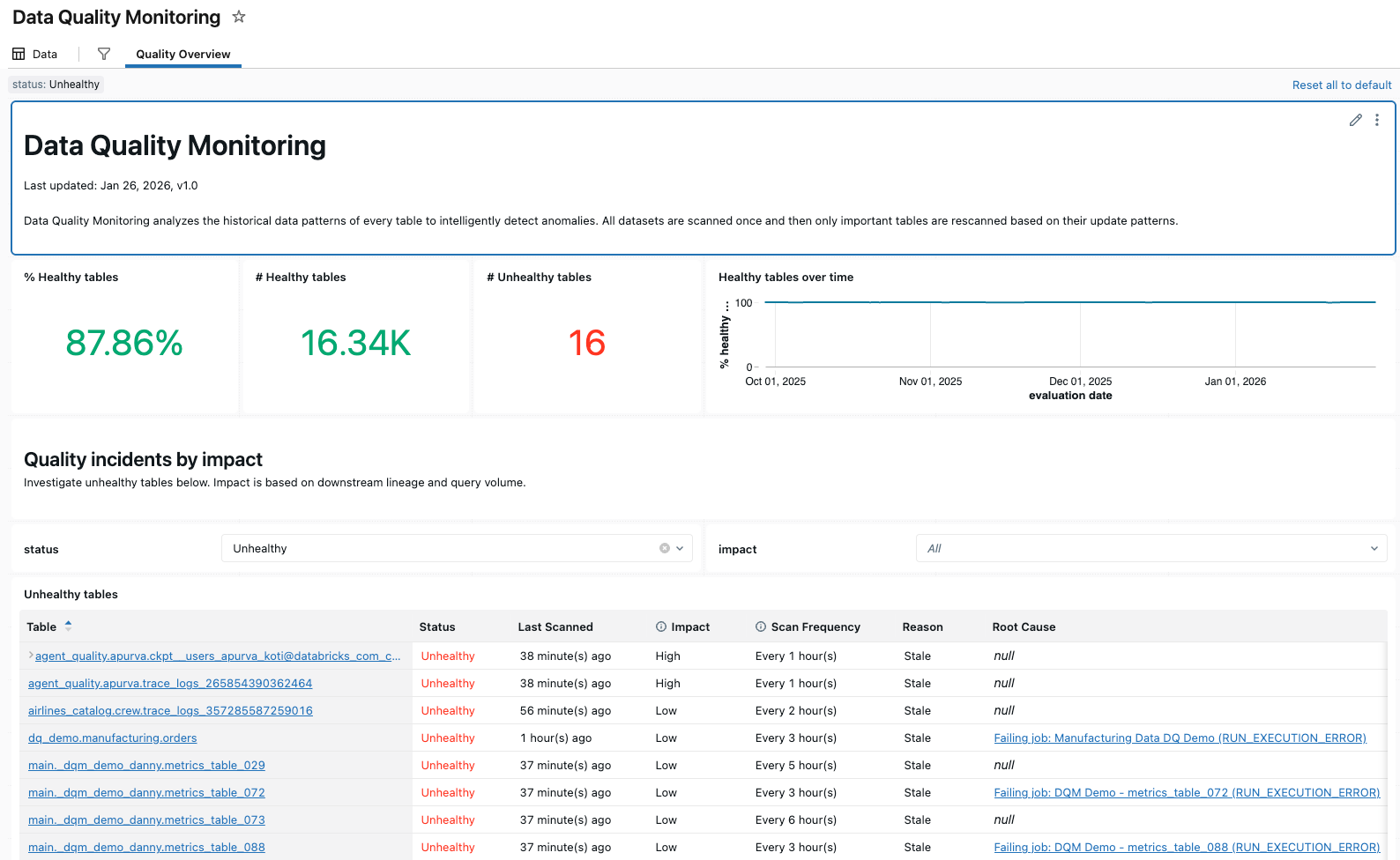
テーブル品質の詳細
テーブル品質の詳細 UI を使用すると、傾向を詳しく分析し、スキーマ内の特定のテーブルで異常が検出された理由を把握できます。このビューにはいくつかの方法でアクセスできます。
- 結果 UI (新しいエクスペリエンス) から、インシデント リストのレビュー リンクをクリックします。
- モニタリング ダッシュボード (従来のLakeviewダッシュボード) から、[品質概要] タブのテーブル名をクリックします。
- UC テーブル ビューアー から、テーブル ページの [品質] タブにアクセスします。
どのオプションを選択しても、選択したテーブルの同じ テーブル品質詳細 ビューが表示されます。
テーブルが指定されると、UI にはテーブルの各品質チェックの概要と、各評価タイムスタンプでの予測値と観測値のグラフが表示されます。グラフには過去 1 週間のデータの結果がプロットされます。

テーブルが品質チェックに合格しなかった場合、UI には根本原因として特定された上流のジョブも表示されます。
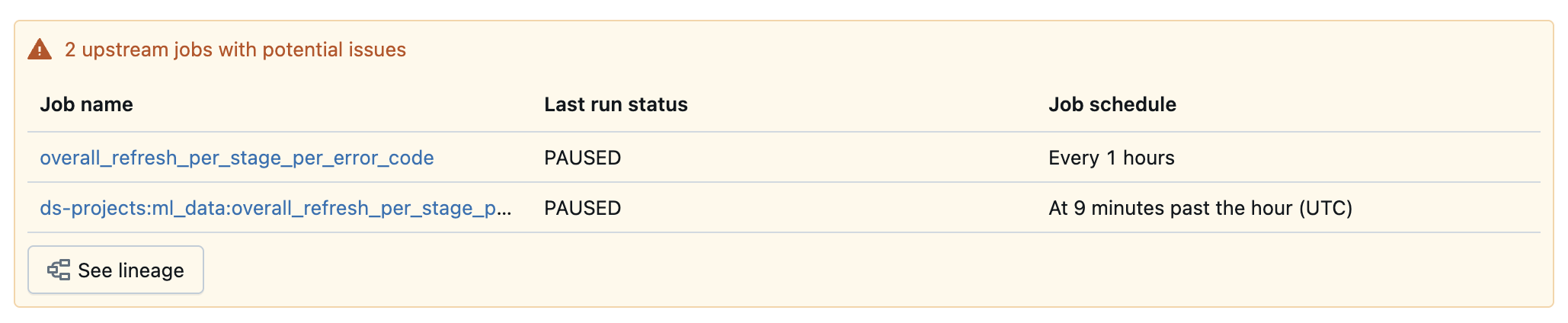
アラートを設定する
出力結果テーブルでDatabricks SQLアラートを構成するには、 「異常検出のアラート」を参照してください。
制限事項
- 異常検出はビューやフォーリンテーブルをサポートしていません。
- 完全性の判定には、null、ゼロ値、NaN の割合などのアカウント メトリクスは考慮されません。
レガシー異常検出
次のセクションでは、データ品質ダッシュボードと異常検出ジョブ構成という 2 つのレガシー機能について説明します。異常検出の現在のバージョンにはこれらの機能は含まれていません。ダッシュボードは、データ品質モニタリング結果 UIに置き換えられました。
データ品質ダッシュボード(レガシー)
データ品質ダッシュボード(レガシー)
The data quality monitoring dashboard was available only to legacy users. In the current version, use View data quality monitoring results in the UI.
最初のデータ品質モニターの実行により、ログ テーブルから得られた結果と傾向をまとめたダッシュボードが作成されます。ダッシュボードには、スキャンされたスキーマの知見が自動的に入力されます。 このパス: /Shared/Databricks Quality Monitoring/Data Quality Monitoringワークスペースごとに 1 つのダッシュボードが作成されます。
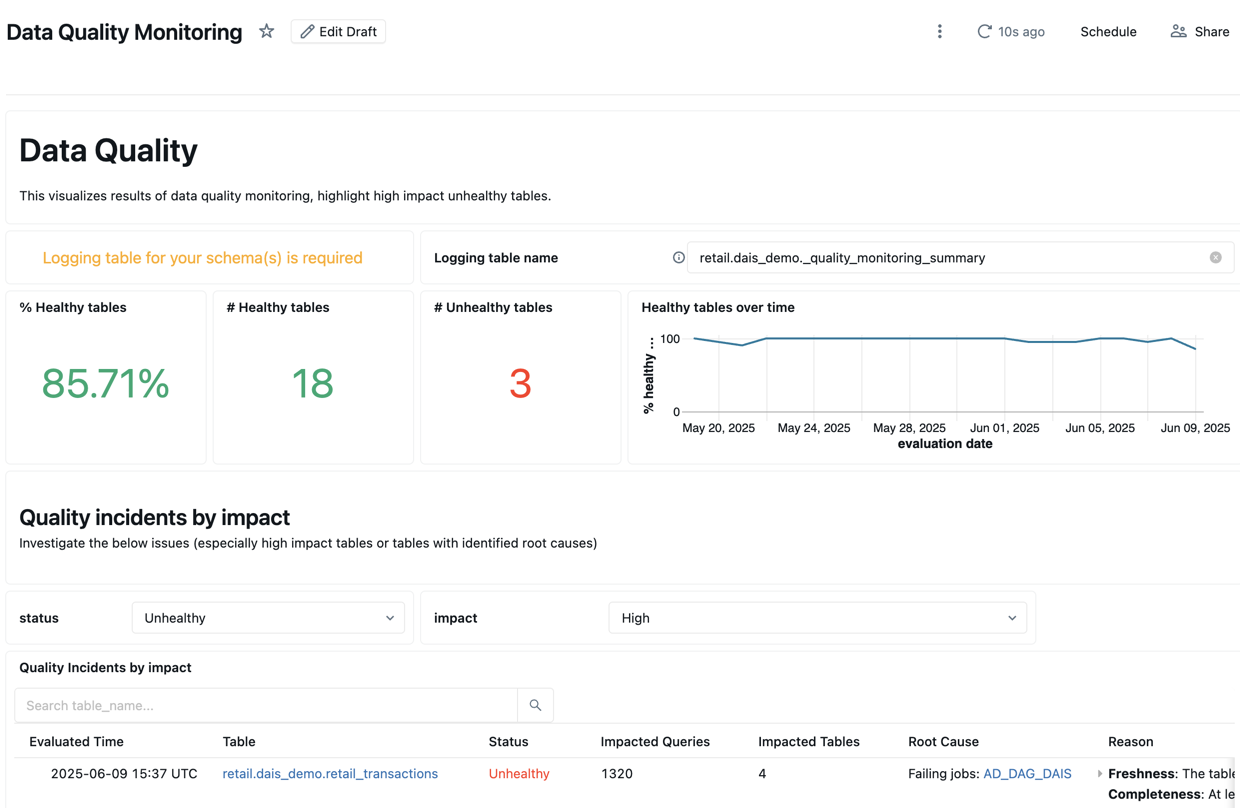
品質の概要
「 品質概要」 タブには、最新の評価に基づいて、スキーマ内のテーブルの最新の品質状態の概要が表示されます。
開始するには、ダッシュボードにデータを入力するには、分析するスキーマのログ テーブルを入力する必要があります。
ダッシュボードの上部には、スキャンの結果の概要が表示されます。
概要の下には、品質インシデントを影響別にリストした表があります。特定された根本原因はroot_cause_analysis列に表示されます。
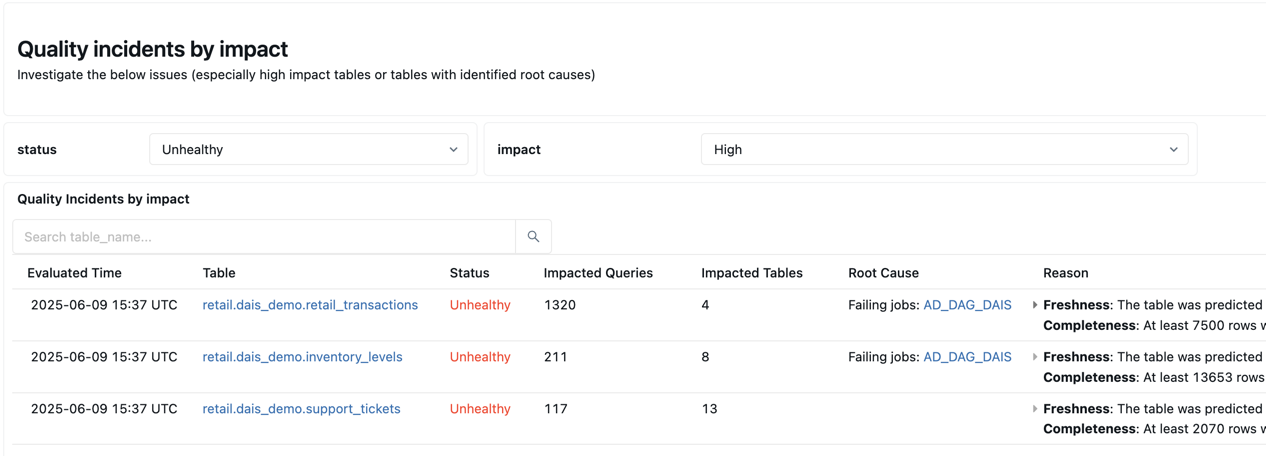
品質インシデント テーブルの下には、長期間更新されていない、識別された静的テーブルのテーブルがあります。
新鮮さと完全性の評価のための設定 (レガシー)
新鮮さと完全性の評価のための設定 (レガシー)
Starting from July 21, 2025, configuration of the job parameters is not supported for new customers. If you need to configure the job settings, contact Databricks.
ジョブの実行頻度やログに記録された結果テーブルの名前など、ジョブを制御する課題を編集するには、ジョブ ページの タスクタブ でジョブ課題を編集する必要があります。
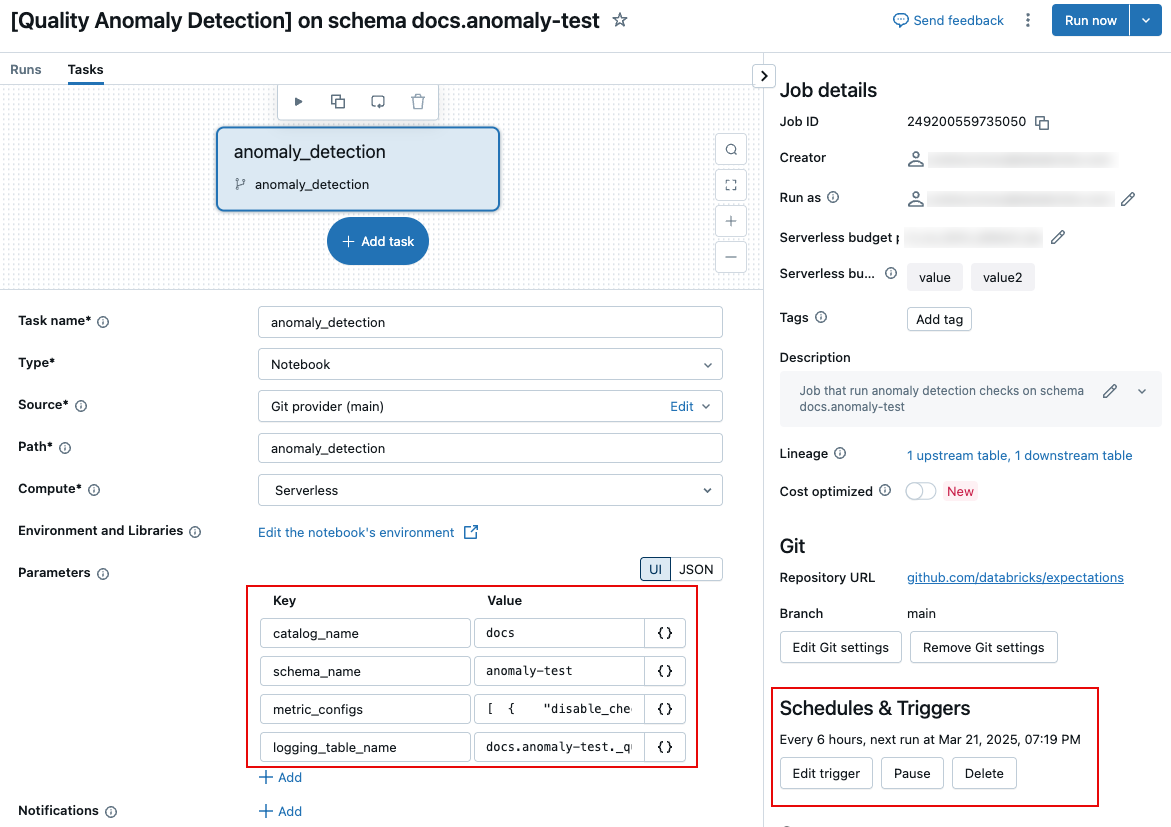
次のセクションでは、具体的な設定について説明します。タスク確保の設定方法については、 「タスク確保の構成」を参照してください。
スケジュールと通知(レガシー)
ジョブのスケジュールをカスタマイズしたり、通知を設定したりするには、[ジョブ] ページの [スケジュールとトリガー] 設定を使用します。 「スケジュールとトリガーを使用したジョブの自動化」を参照してください。
ログテーブルの名前(レガシー)
ログ テーブルの名前を変更するか、テーブルを別のスキーマに保存するには、ジョブ タスクパラメーターlogging_table_nameを編集し、目的の名前を指定します。 ログ テーブルを別のスキーマに保存するには、完全な 3 レベルの名前を指定します。
freshnessとcompleteness評価をカスタマイズする(レガシー)
このセクションの懸念はすべてオプションです。 デフォルトでは、異常検出はテーブルの履歴の分析に基づいてしきい値を決定します。
これらは課題metric_configs内のフィールドです。 metric_configsの形式は、次のデフォルト値を持つ JSON 文字列です。
[
{
"disable_check": false,
"tables_to_skip": null,
"tables_to_scan": null,
"table_threshold_overrides": null,
"table_latency_threshold_overrides": null,
"static_table_threshold_override": null,
"event_timestamp_col_names": null,
"metric_type": "FreshnessConfig"
},
{
"disable_check": true,
"tables_to_skip": null,
"tables_to_scan": null,
"table_threshold_overrides": null,
"metric_type": "CompletenessConfig"
}
]
次の懸念は、 freshnessとcompleteness両方の評価に使用できます。
フィールド名 | 説明 | 例 |
|---|---|---|
| 指定されたテーブルのみがスキャンされます。 |
|
| 指定されたテーブルはスキャン中にスキップされます。 |
|
| スキャンは実行されません。 |
|
次の懸念は、 freshness評価にのみ適用されます。
フィールド名 | 説明 | 例 |
|---|---|---|
| スキーマ内のテーブルに含まれる可能性のあるタイムスタンプ列のリスト。テーブルにこれらの列のいずれかがある場合、この列の最大値を超えると |
|
| テーブル名としきい値 (秒単位) で構成される辞書。テーブルを |
|
| テーブル名とレイテンシしきい値 (秒単位) で構成される辞書。テーブルを |
|
| テーブルが静的テーブル (つまり、更新されなくなったテーブル) と見なされるまでの時間 (秒単位)。 |
|
次の懸念は、 completeness評価にのみ適用されます。
フィールド名 | 説明 | 例 |
|---|---|---|
| テーブル名と行ボリュームしきい値 (整数として指定) で構成される辞書。過去 24 時間にテーブルに追加された行数が指定されたしきい値より少ない場合、テーブルは |
|