O que está por vir?
Saiba mais sobre as mudanças de recurso e comportamento nas próximas versões do site Databricks.
Alteração comportamental da opção de listagem de diretórios incremental do Auto Loader
A opção Auto Loader cloudFiles.useIncrementalListing está obsoleta. Embora esta nota discuta uma alteração no valor da opção default e como continuar a usá-la após essa alteração, o site Databricks não recomenda o uso dessa opção em favor do modo de notificação de arquivo com eventos de arquivo.
Em uma versão futura do Databricks Runtime, o valor da opção Auto Loader cloudFiles.useIncrementalListing obsoleta será, pelo default, definido como false. Definir esse valor como false faz com que o Auto Loader execute uma listagem completa de diretórios sempre que for executado. Atualmente, o valor default da opção cloudFiles.useIncrementalListing é auto, instruindo Auto Loader a fazer uma tentativa de detectar se uma listagem incremental pode ser usada com um diretório.
Para continuar usando o recurso de listagem incremental, defina a opção cloudFiles.useIncrementalListing como auto. Quando o senhor define esse valor como auto, o Auto Loader faz uma tentativa de fazer uma listagem completa a cada sete listagens incrementais, o que corresponde ao comportamento dessa opção antes dessa alteração.
Para saber mais sobre a listagem de diretórios Auto Loader, consulte Auto Loader transmissão com modo de listagem de diretórios.
Mudança de comportamento quando as definições de dataset são removidas do pipeline declarativo de LakeFlow
Uma versão futura do pipeline declarativo LakeFlow mudará o comportamento quando uma tabela materializada view ou de transmissão for removida de um pipeline. Com essa alteração, a tabela materializada view ou de transmissão removida não será excluída automaticamente na próxima execução da atualização pipeline. Em vez disso, o senhor poderá usar o comando DROP MATERIALIZED VIEW para excluir uma tabela materializada view ou o comando DROP TABLE para excluir uma tabela de transmissão. Após a queda de um objeto, a execução de uma atualização do pipeline não recuperará o objeto automaticamente. Um novo objeto é criado se uma tabela materializada view ou de transmissão com a mesma definição for adicionada novamente ao pipeline. O senhor pode, no entanto, recuperar um objeto usando o comando UNDROP.
Cronograma de fim do suporte para painéis antigos
- 7 de abril de 2025 : o suporte oficial para a versão antiga dos painéis será encerrado. Somente problemas críticos de segurança e interrupções de serviço serão abordados.
- 3 de novembro de 2025 : A Databricks começará a arquivar painéis legados que não foram acessados nos últimos seis meses. Os painéis arquivados não estarão mais acessíveis e o processo de arquivamento ocorrerá de forma contínua. O acesso aos painéis usados ativamente permanecerá inalterado.
A Databricks trabalhará com os clientes para desenvolver planos de migração para painéis legados ativos após 3 de novembro de 2025.
Para ajudar na transição para os painéis AI/BI, as ferramentas de atualização estão disponíveis tanto na interface do usuário quanto no API. Para obter instruções sobre como usar a ferramenta de migração integrada na interface do usuário, consulte Clonar um painel legado para um AI/BI dashboard. Para obter um tutorial sobre como criar e gerenciar painéis usando o site REST API em Use Databricks APIs para gerenciar painéis.
O campo sourceIpAddress na auditoria logs não incluirá mais um número de porta
Devido a um bug, algumas auditorias de autorização e autenticação logs incluem um número de porta além do IP no campo sourceIPAddress (por exemplo, "sourceIPAddress":"10.2.91.100:0"). O número da porta, que é registrado como 0, não fornece nenhum valor real e é inconsistente com o restante da auditoria Databricks logs. Para melhorar a consistência da auditoria logs, Databricks planeja alterar o formato do endereço IP para esses eventos de auditoria log. Essa mudança será implementada gradualmente a partir do início de agosto de 2024.
Se a auditoria log contiver um sourceIpAddress de 0.0.0.0, Databricks poderá parar de registrar.
O envio de tíquetes de suporte externo em breve será descontinuado
Databricks Está fazendo a transição da experiência de envio de tíquetes de suporte do site help.databricks.com para o menu de ajuda no site Databricks workspace. O envio de tíquetes de suporte via help.databricks.com em breve será descontinuado. O senhor continuará acessando view e fazendo a triagem de seus tíquetes em help.databricks.com.
A experiência no produto, que está disponível se sua organização tiver um contrato de suporte da Databricks, integra-se ao Databricks Assistant para ajudar a resolver seus problemas rapidamente sem precisar enviar um tíquete.
Para acessar a experiência in-produto, clique no ícone do usuário na barra superior do site workspace e, em seguida, clique em Contact Support ou digite "I need help" (Preciso de ajuda) no assistente.
O modal de suporte de contato é aberto.
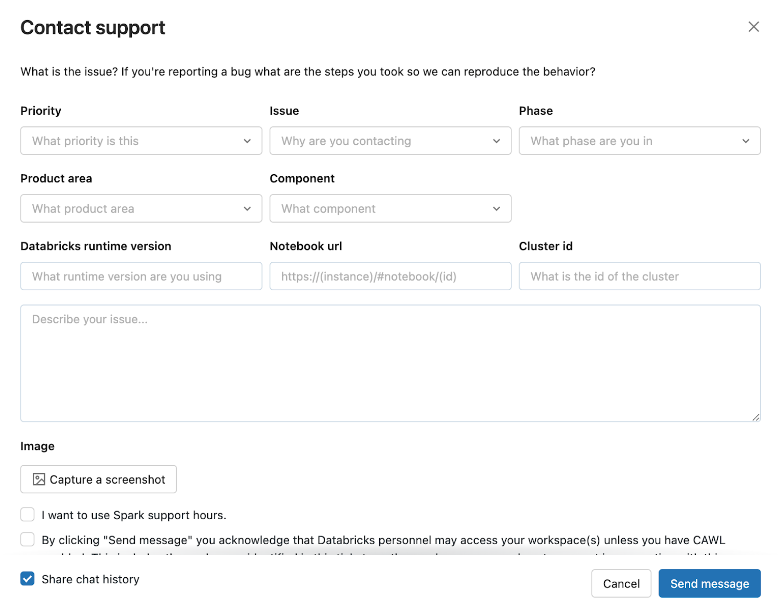
Se a experiência em produção estiver inativa, envie solicitações de suporte com informações detalhadas sobre seu problema para help@databricks.com. Para obter mais informações, consulte Obter ajuda.