Failing jobs or executors removed
So you're seeing failed jobs or removed executors:
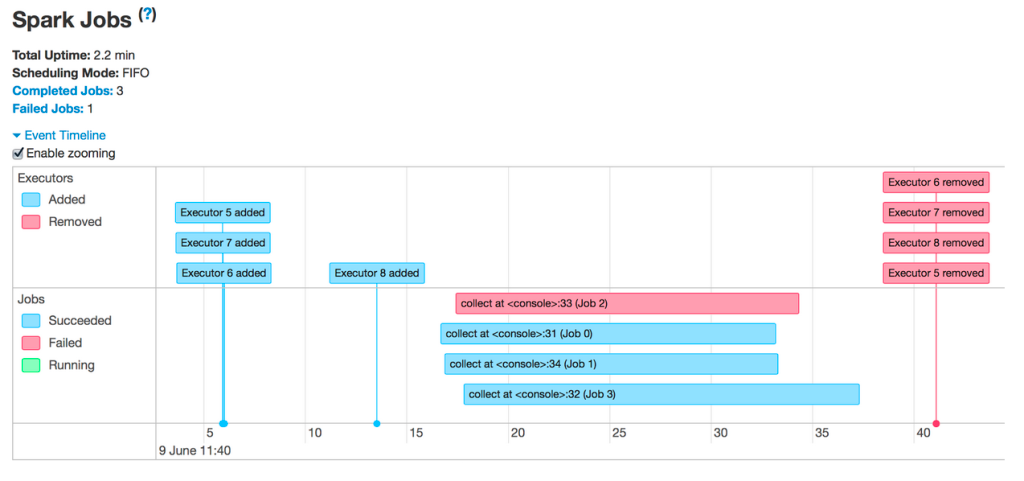
The most common reasons for executors being removed are:
- Autoscaling: In this case it's expected and not an error. See Enable autoscaling.
- Spot instance losses: The cloud provider is reclaiming your VMs. You can learn more about Spot instances here.
- Executors running out of memory
Failing jobs
If you see any failing jobs, click on them to get to their pages. Then scroll down to see the failed stage and a failure reason:
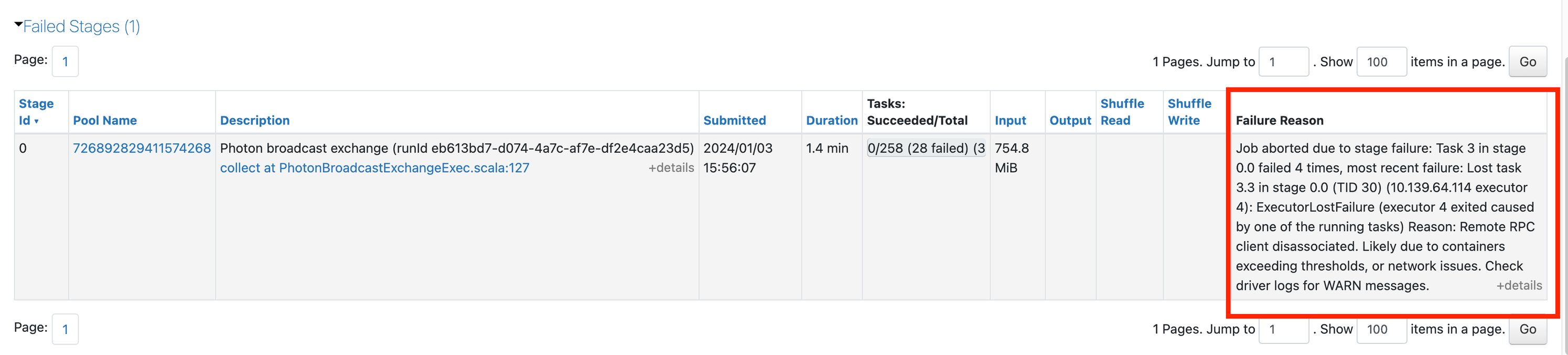
You may get a generic error. Click on the link in the description to see if you can get more info:
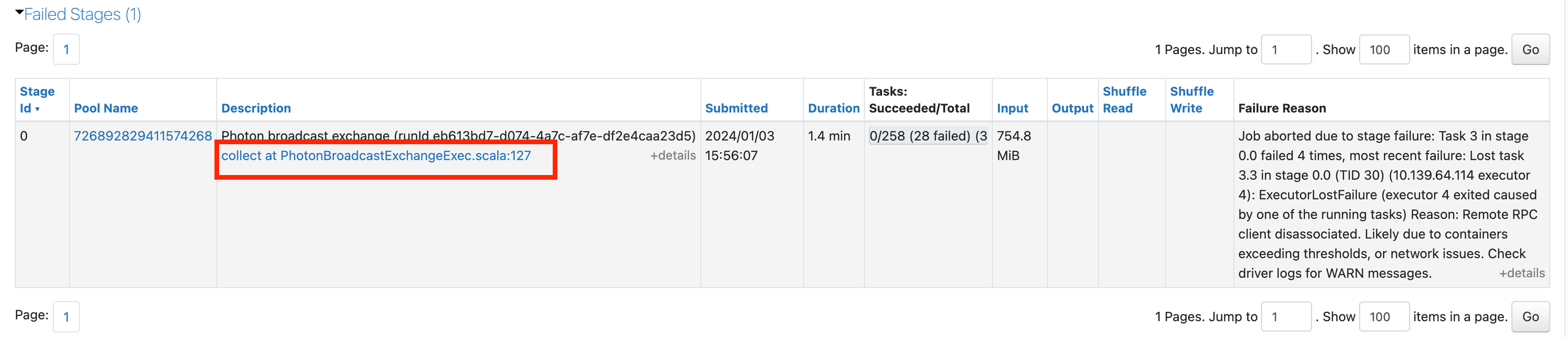
If you scroll down in this page, you will be able to see why each task failed. In this case it's becoming clear there's a memory issue:

Failing executors
To find out why your executors are failing, you'll first want to check the compute's Event log to see if there's any explanation for why the executors failed. For example, it's possible you're using spot instances and the cloud provider is taking them back.

See if there are any events explaining the loss of executors. For example you may see messages indicating that the cluster is resizing or spot instances are being lost.
- If you are using spot instances, see Losing spot instances.
- If your compute was resized with autoscaling, it's expected and not an error. See Learn more about cluster resizing.
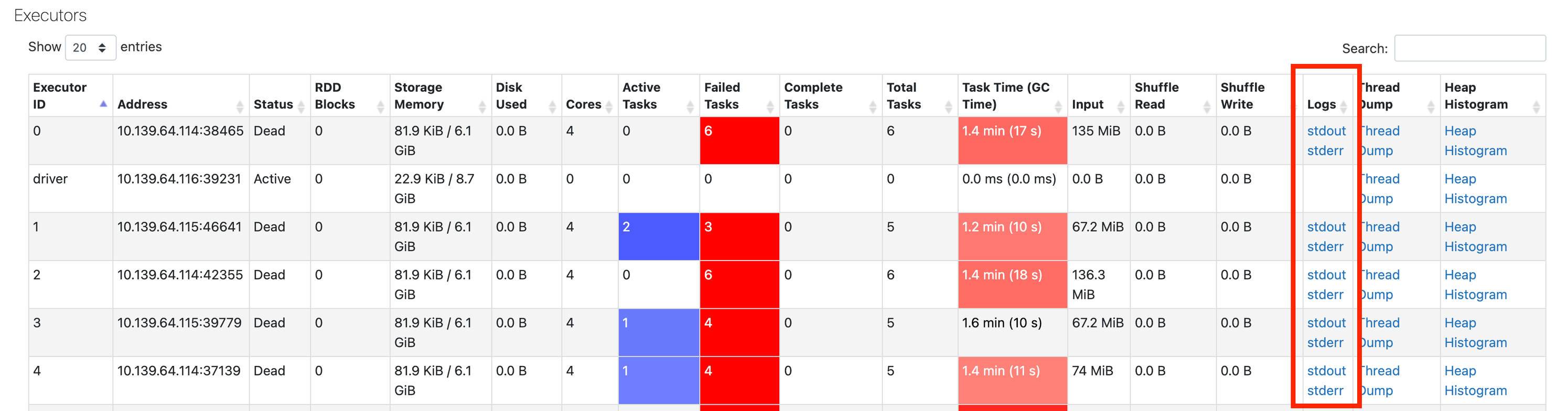
If you don't see any information in the event log, navigate back to the Spark UI then click the Executors tab:

Here you can get the logs from the failed executors:
Next step
If you've gotten this far, the likeliest explanation is a memory issue. The next step is to dig into memory issues. See Spark memory issues.