MLflow 3 deep learning workflow
Example notebook
The example notebook runs a single deep learning model training job with PyTorch, which is tracked as an MLflow run. It logs a checkpoint model after every 10 epochs. Each checkpoint is tracked as an MLflow LoggedModel. Using MLflow's UI or search API, you can inspect the checkpoint models and rank them by accuracy.
The notebook installs the scikit-learn and torch libraries.
MLflow 3 deep learning model with checkpoints notebook
Use the UI to explore model performance and register a model
After running the notebook, you can view the saved checkpoint models in the MLflow experiments UI. A link to the experiment appears in the notebook cell output, or follow these steps:
-
Click Experiments in the workspace sidebar.
-
Find your experiment in the experiments list. You can select the Only my experiments checkbox or use the Filter experiments search box to filter the list of experiments.
-
Click the name of your experiment. The Runs page opens. The experiment contains one MLflow run.

-
Click the Models tab. The individual checkpoint models are tracked on this screen. For each checkpoint, you can see the model's accuracy, along with all of its parameters and metadata.
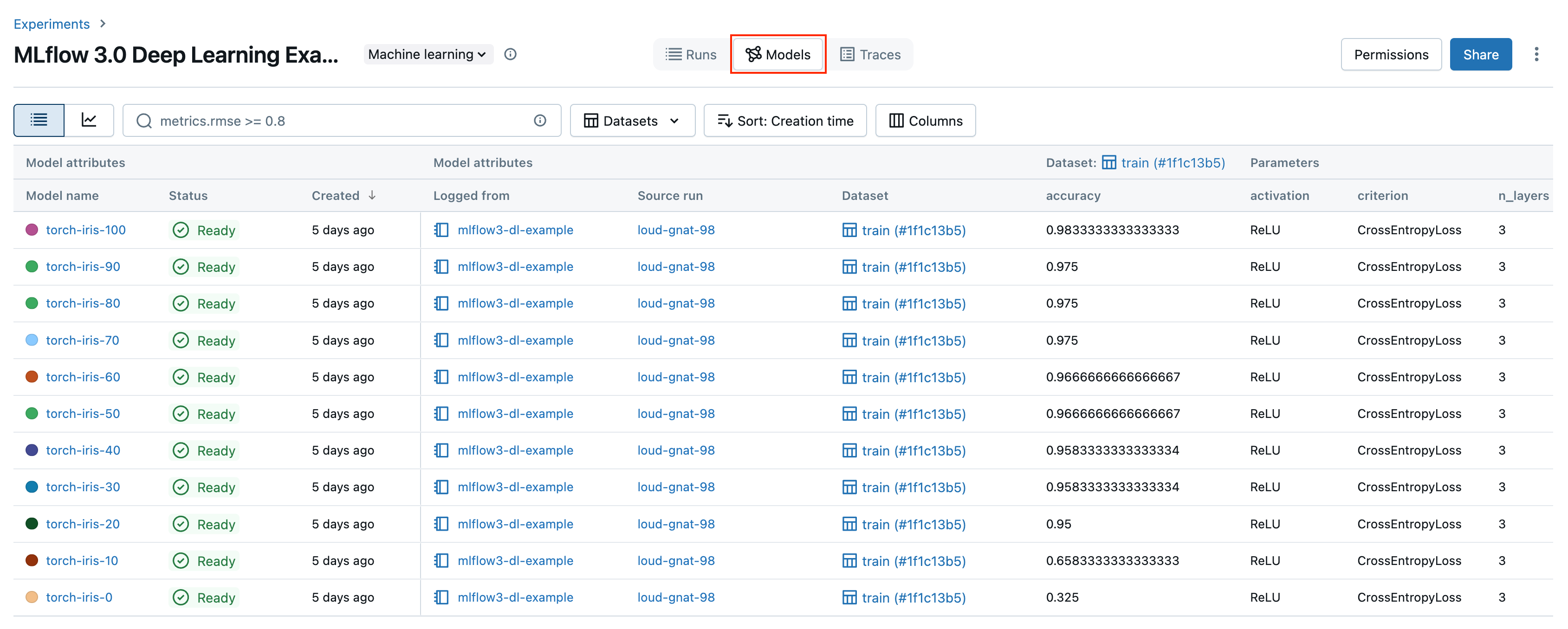
In the example notebook, you registered the best performing model to Unity Catalog. You can also register a model from the UI. To do so, follow these steps:
-
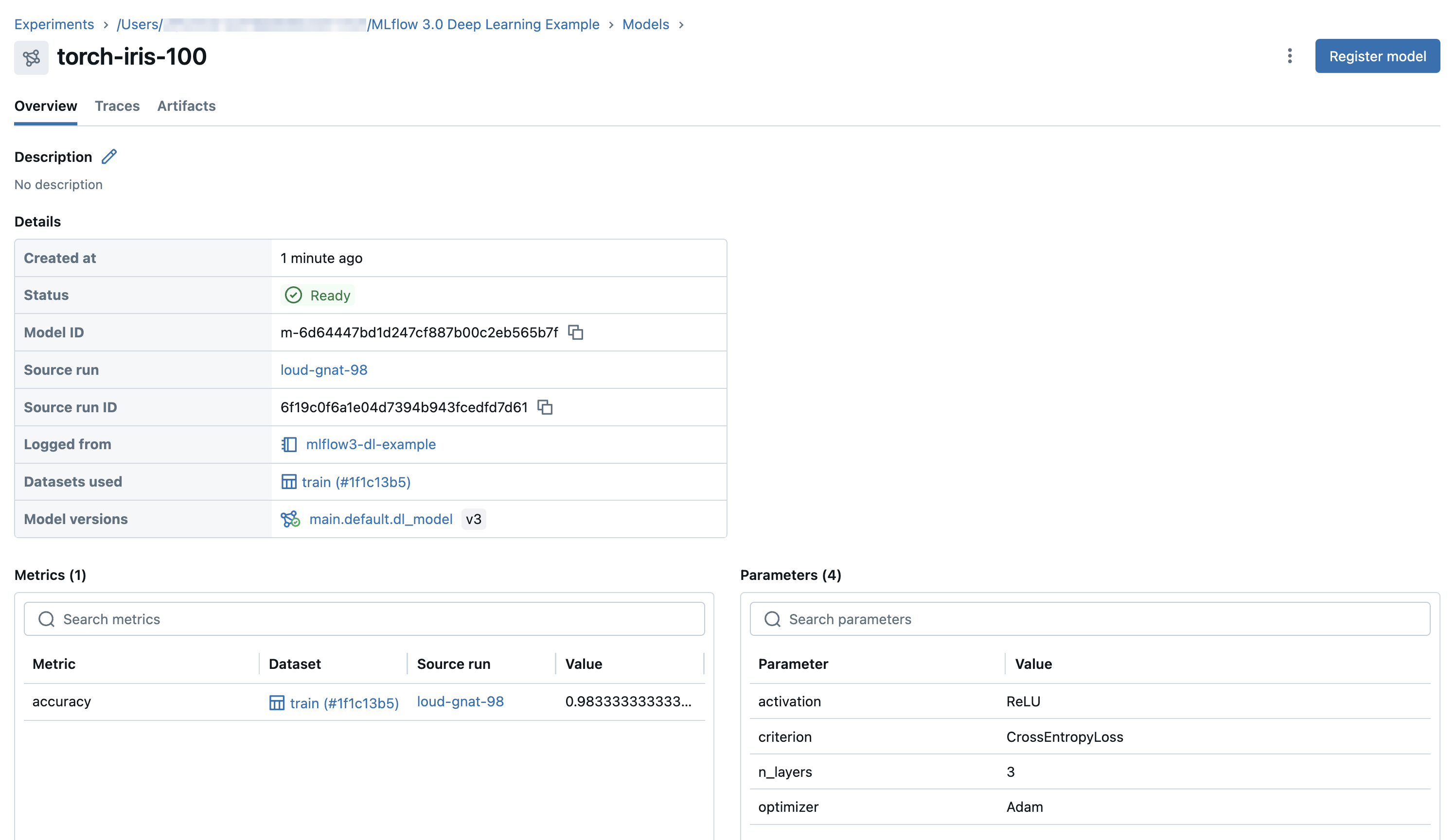
From the Models tab, click the name of the model to register.
-
From the model details page, in the upper-right corner, click Register model.
tipIt can take a few minutes for a model to appear in the UI after registering it. Do not press the Register model more than once, otherwise you will register duplicate models.
-
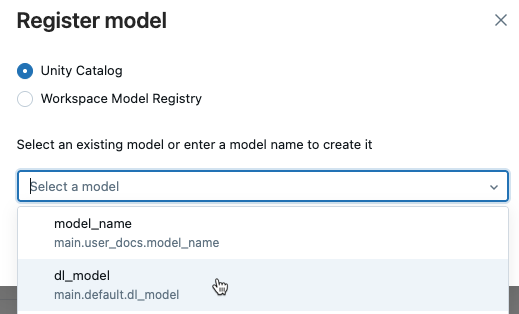
Select Unity Catalog and either select an existing model name from the drop-down menu or type in a new name.
-
Click Register.
Use the API to rank checkpoint models
The following code shows how to rank the checkpoint models by accuracy. For more details on searching logged models using the API, see Search and filter Logged Models.
ranked_checkpoints = mlflow.search_logged_models(
output_format="list",
order_by=[{"field_name": "metrics.accuracy", "ascending": False}]
)
best_checkpoint: mlflow.entities.LoggedModel = ranked_checkpoints[0]
print(best_checkpoint.metrics[0])
<Metric:
dataset_digest='9951783d',
dataset_name='train',
key='accuracy',
model_id='m-bba8fa52b6a6499281c43ef17fcdac84',
run_id='394928abe6fc4787aaf4e666ac89dc8a',
step=90,
timestamp=1730828771880,
value=0.9553571428571429
>
worst_checkpoint: mlflow.entities.LoggedModel = ranked_checkpoints[-1]
print(worst_checkpoint.metrics[0])
<Metric:
dataset_digest='9951783d',
dataset_name='train',
key='accuracy',
model_id='m-88885bc26de7492f908069cfe15a1499',
run_id='394928abe6fc4787aaf4e666ac89dc8a',
step=0,
timestamp=1730828730040,
value=0.35714285714285715
What's the difference between the Models tab on the MLflow experiment page and the model version page in Catalog Explorer?
The Models tab of the experiment page and the model version page in Catalog Explorer show similar information about the model. The two views have different roles in the model development and deployment lifecycle.
- The Models tab of the experiment page presents the results of logged models from an experiment on a single page. The Charts tab on this page provides visualizations to help you compare models and select the model versions to register to Unity Catalog for possible deployment.
- In Catalog Explorer, the model version page provides an overview of all model performance and evaluation results. This page shows model parameters, metrics, and traces across all linked environments including different workspaces, endpoints, and experiments. This is useful for monitoring and deployment, and works especially well with deployment jobs. The evaluation task in a deployment job creates additional metrics that appear on this page. The approver for the job can then review this page to assess whether to approve the model version for deployment.
Additional resources
To learn more about LoggedModel tracking introduced in MLflow 3, see the following article:
To learn more about using MLflow 3 with traditional ML workflows, see the following article: