推論のためのRAGチェーン
この記事では、ユーザーがオンライン設定でRAGアプリケーションにリクエストを送信するときに発生するプロセスについて説明します。 データがデータパイプラインによって処理されると、RAGアプリケーションでの使用に適しています。 推論時に呼び出される一連のステップ、または一連のステップは、一般に RAGチェーン と呼ばれます。
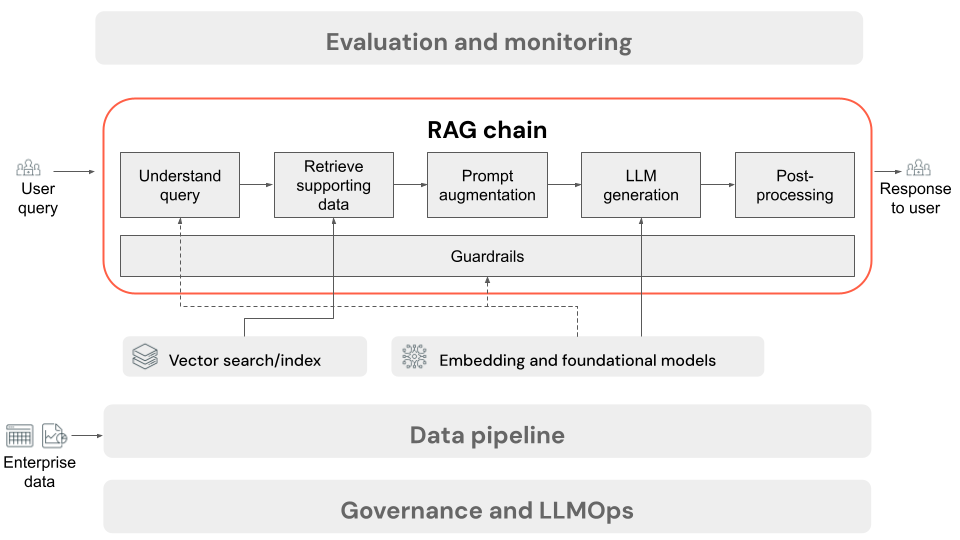
- (オプション) ユーザー クエリの前処理: 場合によっては、ユーザーのクエリは、ベクトル データベースのクエリにより適したものになるように前処理されます。これには、テンプレート内のクエリの書式設定、別のモデルを使用したリクエストの書き換え、取得を支援するためのキーワードの抽出などが含まれます。このステップの出力は、後続の取得ステップで使用される取得クエリです。
- 検索: ベクターデータベースからサポート情報を取得するために、データ準備中にドキュメントチャンクを埋め込むために使用されたのと同じ埋め込みモデルを使用して、検索クエリが埋め込みに変換されます。 これらの埋め込みにより、コサイン類似度などの手段を使用して、検索クエリと非構造化テキスト チャンクの間のセマンティック類似性を比較できます。 次に、チャンクがベクターデータベースから取得され、埋め込まれたリクエストとの類似性に基づいてランク付けされます。 上位 (最も類似した) 結果が返されます。
- プロンプト増強: LLM に送信されるプロンプトは、取得したコンテキストでユーザーのクエリを拡張することによって形成され、各コンポーネントの使用方法をモデルに指示するテンプレートで、多くの場合、応答形式を制御するための追加の指示が含まれます。使用する適切なプロンプト・テンプレートで反復処理するプロセスは、 プロンプト・エンジニアリングと呼ばれます。
- LLM の生成: LLM は、ユーザーのクエリと取得されたサポート データを含む拡張プロンプトを入力として受け取ります。次に、追加のコンテキストに基づく応答を生成します。
- (オプション)後処理: LLM の応答は、追加のビジネス ロジックを適用したり、引用を追加したり、事前定義されたルールや制約に基づいて生成されたテキストを絞り込んだりするために、さらに処理される場合があります。
RAGアプリケーションデータパイプラインと同様に、RAGチェーンの品質に影響を与える可能性のある多くの重要なエンジニアリング上の決定があります。たとえば、ステップ 2 で取得するチャンクの数や、ステップ 3 でそれらをユーザーのクエリとどのように組み合わせるかを決定することは、モデルが高品質の応答を生成する能力に大きな影響を与える可能性があります。
チェーン全体で、エンタープライズポリシーとのコンプライアンスを確保するために、さまざまなガードレールを適用できます。 これには、適切なリクエストのフィルタリング、データソースにアクセスする前のユーザー権限の確認、生成されたレスポンスへのコンテンツモデレーション手法の適用が含まれる場合があります。