Azure Synapse Analytics 専用プールに接続する
実験段階
従来のクエリ フェデレーションのドキュメントは廃止されており、更新されない可能性があります。このコンテンツに記載されている構成は、Databricks によって公式に承認またはテストされたものではありません。レイクハウスフェデレーションがソースデータベースをサポートしている場合、Databricks代わりにそれを使用することをお勧めします。
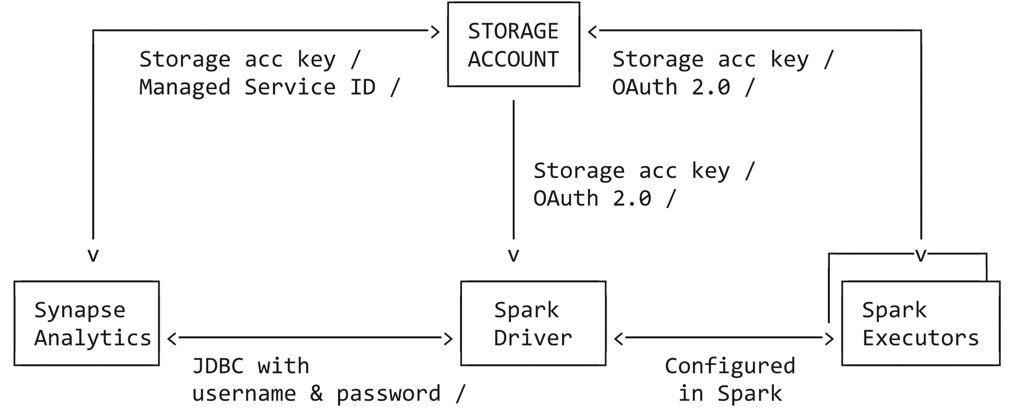
このチュートリアルでは、サービスプリンシパル、Azure マネージドサービス Identity (MSI)、およびSQL 認証を用いて、Azure DatabricksからAzure Synapse Analytics専用プールに接続するために必要なすべてのステップを説明します。 Azure Synapse コネクタでは、次の 3 種類のネットワーク接続が使用されます。
- Spark ドライバーから Azure Synapse への接続
- SparkドライバーとエグゼキューターからAzureストレージアカウントへの接続
- Azure Synapse から Azure ストレージ アカウントへの接続
必要条件
チュートリアルを開始する前に、次のタスクを完了してください。
- Azure Databricks ワークスペースを作成します。クラシックワークスペースの作成を参照してください
- Azure Synapse Analytics ワークスペースを作成します。「クイック スタート: Synapse ワークスペースを作成する」を参照してください
- 専用 SQL プールを作成します。「クイック スタート: Azure portal を使用して専用 SQL プールを作成する」を参照してください
- と の間の接続用にステージングAzure データレイク StorageAzure DatabricksAzure Synapse Analytics を作成します。
サービスプリンシパルを使用して Azure Synapse Analytics に接続する
このチュートリアルの次の手順では、サービスプリンシパルを使用して Azure Synapse Analytics に接続する方法を示します。
ステップ 1:Microsoft Azureデータレイク Storage の Entra ID サービスプリンシパルを作成する
サービスプリンシパルを使用して Azure データレイク Gen2 に接続するには、管理者ユーザーが新しい Microsoft Entra ID (旧称 Azure Active Directory) アプリケーションを作成する必要があります。 すでに Microsoft Entra ID サービスプリンシパル をお持ちの場合は、 ステップ 3 に進んでください。 Microsoft Entra ID サービスプリンシパルを作成するには、次の手順に従います。
- Azure portal にサインインします。
- 複数のテナント、サブスクリプション、またはディレクトリにアクセスできる場合は、トップ メニューの ディレクトリ + サブスクリプション (フィルター付きディレクトリ) アイコンをクリックして、サービスプリンシパルをプロビジョニングするディレクトリに切り替えます。
- Microsoft Entra ID を検索して選択します。
- 管理 で、 アプリの登録 > 新規登録 をクリックします。
- 名前 に、アプリケーションの名前を入力します。
- サポートされているアカウントの種類 セクションで、 この組織ディレクトリ内のアカウントのみ (Single テナント) を選択します。
- 登録 をクリックします。
(オプション)ステップ 2:Microsoft の Entra ID サービスプリンシパルを作成するAzure Synapse Analytics
オプションで、ステップ 1 の手順を繰り返すことで、 Azure Synapse Analytics 専用のサービスプリンシパルを作成できます。 サービスプリンシパル クレデンシャルの個別のセットを作成しない場合、接続は同じサービスプリンシパルを使用して Azure データ レイク Gen2 と Azure Synapse Analyticsに接続します。
手順 3: Azure のデータレイク Gen2 (and Azure Synapse Analytics) サービスプリンシパルのクライアント シークレットを作成する
- 管理 で、 証明書とシークレット をクリックします
- クライアント シークレット タブで、 新しいクライアント シークレット をクリックします。
- クライアントシークレットの追加 ペインの 説明 に、クライアントシークレットの説明を入力します。
- 有効期限 で、クライアントシークレットの有効期限を選択し、 追加 をクリックします。
- クライアント シークレットの Value をコピーして安全な場所に保存します (このクライアント シークレットはアプリケーションのパスワードです)。
- アプリケーション ページの [概要 ] ページの [要点 ] セクションで、次の値をコピーします。
- アプリケーション (クライアント) ID
- ディレクトリ (テナント) ID
Azure Synapse Analyticsのサービスプリンシパル認証情報のセットを作成した場合は、再度手順に従ってクライアントシークレットを作成します。
ステップ 4: サービスプリンシパルに Azure データレイク Storage へのアクセス権を付与する
ストレージリソースへのアクセス権を付与するには、サービスプリンシパルにロールを割り当てます。 このチュートリアルでは、 Storage Blob Data Contributor を Azure データレイク Storage アカウントのサービスプリンシパルに割り当てます。 特定の要件に応じて、他のロールを割り当てる必要がある場合があります。
- Azure portal で、 ストレージ アカウント サービスに移動します。
- 使用する Azure ストレージ アカウントを選択します。
- アクセス制御(IAM) をクリックします。
- + 追加 をクリックし、ドロップダウン メニューから ロールの割り当てを追加 を選択します。
- 選択 フィールドをステップ 1 で作成した Microsoft Entra ID アプリケーション名に設定し、ロールを ストレージ BLOB データ共同作成者 に設定します。
- 保存 をクリックします。
Azure Synapse Analyticsのサービスプリンシパル認証情報のセットを作成した場合は、再度ステップを実行して、Azure データレイク Storage 上のサービスプリンシパルへのアクセスを許可します。
手順 5: Azure Synapse Analytics 専用プールでマスター キーを作成する
Azure Synapse Analytics 専用プールに接続し、 マスター キーを作成します (まだ作成していない場合)。
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<Password>'
手順 6: Azure Synapse Analytics 専用プール内のサービスプリンシパルにアクセス許可を付与する
Azure Synapse Analytics専用プールに接続し、 Azure Synapse Analyticsに接続するサービスプリンシパルの外部ユーザー を作成します。
CREATE USER <serviceprincipal> FROM EXTERNAL PROVIDER
サービスプリンシパルの名前は、ステップ2(または、専用のサービスプリンシパルの作成をスキップした場合はステップ1)で作成した名前と一致する必要があります Azure Synapse Analytics。
サービスプリンシパルに db_owner になる権限を付与するには、次のコマンドを実行します。
sp_addrolemember 'db_owner', '<serviceprincipal>'
既存のテーブルに挿入するために必要な権限を付与します。
GRANT ADMINISTER DATABASE BULK OPERATIONS TO <serviceprincipal>
GRANT INSERT TO <serviceprincipal>
(オプション)新しいテーブルに挿入するために必要な権限を付与します。
GRANT CREATE TABLE TO <serviceprincipal>
GRANT ALTER ON SCHEMA ::dbo TO <serviceprincipal>
手順 7: 構文の例: Azure Synapse Analytics でデータのクエリと書き込みを行う
Synapse のクエリは、Scala、Python、SQL、R で行うことができます。次のコード例では、ストレージ アカウント キーを使用し、ストレージ資格情報を Azure Databricks から Synapse に転送します。
- Scala
- Python
- SQL
- R
次のコード例は、次のことを行う必要があることを示しています。
- ノートブック セッションでストレージ アカウントのアクセス キーを設定する
- Azure storage アカウントのサービスプリンシパル credentials を定義します
- Azure Synapse Analytics に対してサービスプリンシパル資格情報の個別のセットを定義します (定義されていない場合、コネクタは Azure storage アカウント資格情報を使用します)
- Azure Synapse テーブルからデータを取得する
- Azure Synapse クエリからデータを読み込む
- データにいくつかの変換を適用し、データソースAPIを使用してデータをAzure Synapse内の別のテーブルに書き戻します
import org.apache.spark.sql.DataFrame
// Set up the storage account access key in the notebook session
conf.spark.conf.set(
"fs.azure.account.key.<your-storage-account-name>.dfs.core.windows.net",
"<your-storage-account-access-key>")
// Define the service principal credentials for the Azure storage account
spark.conf.set("fs.azure.account.auth.type", "OAuth")
spark.conf.set("fs.azure.account.oauth.provider.type", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
spark.conf.set("fs.azure.account.oauth2.client.id", "<ApplicationId>")
spark.conf.set("fs.azure.account.oauth2.client.secret", "<SecretValue>")
spark.conf.set("fs.azure.account.oauth2.client.endpoint", "https://login.microsoftonline.com/<DirectoryId>/oauth2/token")
// Define a separate set of service principal credentials for Azure Synapse Analytics (If not defined, the connector will use the Azure storage account credentials)
spark.conf.set("spark.databricks.sqldw.jdbc.service.principal.client.id", "<ApplicationId>")
spark.conf.set("spark.databricks.sqldw.jdbc.service.principal.client.secret", "<SecretValue>")
// Get some data from an Azure Synapse table
val df: DataFrame = spark.read
.format("com.databricks.spark.sqldw")
.option("url", "jdbc:sqlserver://<the-rest-of-the-connection-string>")
.option("tempDir", "abfss://<your-container-name>@<your-storage-account-name>.dfs.core.windows.net/<your-directory-name>")
.option("enableServicePrincipalAuth", "true")
.option("dbTable", "dbo.<your-table-name>")
.load()
// Load data from an Azure Synapse query
val df1: DataFrame = spark.read
.format("com.databricks.spark.sqldw")
.option("url", "jdbc:sqlserver://<the-rest-of-the-connection-string>")
.option("tempDir", "abfss://<your-container-name>@<your-storage-account-name>.dfs.core.windows.net/<your-directory-name>")
.option("enableServicePrincipalAuth", "true")
.option("query", "select * from dbo.<your-table-name>")
.load()
// Apply some transformations to the data, then use the
// Data Source API to write the data back to another table in Azure Synapse
df1.write
.format("com.databricks.spark.sqldw")
.option("url", "jdbc:sqlserver://<the-rest-of-the-connection-string>")
.option("tempDir", "abfss://<your-container-name>@<your-storage-account-name>.dfs.core.windows.net/<your-directory-name>")
.option("enableServicePrincipalAuth", "true")
.option("dbTable", "dbo.<new-table-name>")
.save()
次のコード例は、次のことを行う必要があることを示しています。
- ノートブック セッションでストレージ アカウントのアクセス キーを設定する
- Azure storage アカウントのサービスプリンシパル credentials を定義します
- Azure Synapse Analytics に対してサービスプリンシパル クレデンシャルの個別のセットを定義します
- Azure Synapse テーブルからデータを取得する
- Azure Synapse クエリからデータを読み込む
- データにいくつかの変換を適用し、データソースAPIを使用してデータをAzure Synapse内の別のテーブルに書き戻します
次のコード例は、次のことを行う必要があることを示しています。
- Azure storage アカウントのサービスプリンシパル credentials を定義します
- Azure Synapse Analytics に対してサービスプリンシパル クレデンシャルの個別のセットを定義します
- ノートブック セッションでストレージ アカウントのアクセス キーを設定する
- SQLを使用したデータの読み取り
- SQL を使用したデータの書き込み
# Define the Service Principal credentials for the Azure storage account
fs.azure.account.auth.type OAuth
fs.azure.account.oauth.provider.type org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider
fs.azure.account.oauth2.client.id <application-id>
fs.azure.account.oauth2.client.secret <service-credential>
fs.azure.account.oauth2.client.endpoint https://login.microsoftonline.com/<directory-id>/oauth2/token
## Define a separate set of service principal credentials for Azure Synapse Analytics (If not defined, the connector will use the Azure storage account credentials)
spark.databricks.sqldw.jdbc.service.principal.client.id <application-id>
spark.databricks.sqldw.jdbc.service.principal.client.secret <service-credential>
# Set up the storage account access key in the notebook session
conf.SET fs.azure.account.key.<your-storage-account-name>.dfs.core.windows.net=<your-storage-account-access-key>
-- Read data using SQL
CREATE TABLE df
USING com.databricks.spark.sqldw
OPTIONS (
url 'jdbc:sqlserver://<the-rest-of-the-connection-string>',
'enableServicePrincipalAuth' 'true',
dbtable 'dbo.<your-table-name>',
tempDir 'abfss://<your-container-name>@<your-storage-account-name>.dfs.core.windows.net/<your-directory-name>'
);
-- Write data using SQL
-- Create a new table, throwing an error if a table with the same name already exists:
CREATE TABLE df1
USING com.databricks.spark.sqldw
OPTIONS (
url 'jdbc:sqlserver://<the-rest-of-the-connection-string>',
'enableServicePrincipalAuth' 'true',
dbTable 'dbo.<new-table-name>',
tempDir 'abfss://<your-container-name>@<your-storage-account-name>.dfs.core.windows.net/<your-directory-name>'
)
AS SELECT * FROM df1
次のコード例は、次のことを行う必要があることを示しています。
- ノートブック セッションの conf でストレージ アカウントのアクセス キーを設定します
- Azure storage アカウントのサービスプリンシパル credentials を定義します
- Azure Synapse Analytics に対してサービスプリンシパル資格情報の個別のセットを定義します (定義されていない場合、コネクタは Azure storage アカウント資格情報を使用します)
- Azure Synapse テーブルからデータを取得する
- データにいくつかの変換を適用し、データソースAPIを使用してデータをAzure Synapse内の別のテーブルに書き戻します
# Load SparkR
library(SparkR)
# Set up the storage account access key in the notebook session conf
conf <- sparkR.callJMethod(sparkR.session(), "conf")
sparkR.callJMethod(conf, "set", "fs.azure.account.key.<your-storage-account-name>.dfs.core.windows.net", "<your-storage-account-access-key>")
# Load SparkR
library(SparkR)
conf <- sparkR.callJMethod(sparkR.session(), "conf")
# Define the service principal credentials for the Azure storage account
sparkR.callJMethod(conf, "set", "fs.azure.account.auth.type", "OAuth")
sparkR.callJMethod(conf, "set", "fs.azure.account.oauth.provider.type", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
sparkR.callJMethod(conf, "set", "fs.azure.account.oauth2.client.id", "<ApplicationId>")
sparkR.callJMethod(conf, "set", "fs.azure.account.oauth2.client.secret", "<SecretValue>")
sparkR.callJMethod(conf, "set", "fs.azure.account.oauth2.client.endpoint", "https://login.microsoftonline.com/<DirectoryId>/oauth2/token")
# Define a separate set of service principal credentials for Azure Synapse Analytics (If not defined, the connector will use the Azure storage account credentials)
sparkR.callJMethod(conf, "set", "spark.databricks.sqldw.jdbc.service.principal.client.id", "<ApplicationId>")
sparkR.callJMethod(conf, "set", "spark.databricks.sqldw.jdbc.service.principal.client.secret", "SecretValue>")
# Get some data from an Azure Synapse table
df <- read.df(
source = "com.databricks.spark.sqldw",
url = "jdbc:sqlserver://<the-rest-of-the-connection-string>",
tempDir = "abfss://<your-container-name>@<your-storage-account-name>.dfs.core.windows.net/<your-directory-name>",
enableServicePrincipalAuth = "true",
dbTable = "dbo.<your-table-name>")
# Load data from an Azure Synapse query.
df <- read.df(
source = "com.databricks.spark.sqldw",
url = "jdbc:sqlserver://<the-rest-of-the-connection-string>",
tempDir = "abfss://<your-container-name>@<your-storage-account-name>.dfs.core.windows.net/<your-directory-name>",
enableServicePrincipalAuth = "true",
query = "Select * from dbo.<your-table-name>")
# Apply some transformations to the data, then use the
# Data Source API to write the data back to another table in Azure Synapse
write.df(
df,
source = "com.databricks.spark.sqldw",
url = "jdbc:sqlserver://<the-rest-of-the-connection-string>",
tempDir = "abfss://<your-container-name>@<your-storage-account-name>.dfs.core.windows.net/<your-directory-name>",
enableServicePrincipalAuth = "true",
dbTable = "dbo.<new-table-name>")
トラブルシューティング
次のセクションでは、発生する可能性のあるエラーメッセージとその考えられる意味について説明します。
サービスプリンシパル credential がユーザーとして存在しません
com.microsoft.sqlserver.jdbc.SQLServerException: Login failed for user '<token-identified principal>'
上記のエラーは、サービスプリンシパル クレデンシャルが Synapse アナリティクス ワークスペースにユーザーとして存在しないことを意味している可能性があります。
Azure Synapse Analytics 専用プールで次のコマンドを実行して、外部ユーザーを作成します。
CREATE USER <serviceprincipal> FROM EXTERNAL PROVIDER
サービスプリンシパル credential has insufficient SELECT permissions
com.microsoft.sqlserver.jdbc.SQLServerException: The SELECT permission was denied on the object 'TableName', database 'PoolName', schema 'SchemaName'. [ErrorCode = 229] [SQLState = S0005]
上記のエラーは、サービスプリンシパル クレデンシャルに Azure Synapse Analytics 専用プールに十分な SELECT アクセス許可がないことを意味している可能性があります。
Azure Synapse Analytics 専用プールで次のコマンドを実行して、SELECT アクセス許可を付与します。
GRANT SELECT TO <serviceprincipal>
サービスプリンシパル credential には使用権限がありません COPY
com.microsoft.sqlserver.jdbc.SQLServerException: User does not have permission to perform this action. [ErrorCode = 15247] [SQLState = S0001]
上記のエラーは、サービスプリンシパル credential に、 Azure Synapse Analytics 専用プールで COPYを使用するための十分なアクセス許可がないことを意味している可能性があります。 サービスプリンシパルには、操作 (既存のテーブルへの挿入または新しいテーブルへの挿入) に応じて異なるアクセス許可が必要です。 サービスプリンシパルに必要なAzure Synapse権限があることを確認します。
サービスプリンシパルは、Azure Synapse Analytics専用プールの db_owner ではありません。
Azure Synapse Analytics 専用プールで次のコマンドを実行して、 db_owner アクセス許可を付与します。
sp_addrolemember 'db_owner', 'serviceprincipal'
専用プールにマスター キーがありません
com.microsoft.sqlserver.jdbc.SQLServerException: Please create a master key in the database or open the master key in the session before performing this operation. [ErrorCode = 15581] [SQLState = S0006]
上記のエラーは、Azure Synapse Analytics 専用プールにマスター キーが存在しないことを意味している可能性があります。
この問題を解決するには、Azure Synapse Analytics でマスター キーを作成します。
サービスプリンシパル credential に十分な書き込み権限がありません
com.microsoft.sqlserver.jdbc.SQLServerException: CREATE EXTERNAL TABLE AS SELECT statement failed as the path name '' could not be used for export. Please ensure that the specified path is a directory which exists or can be created, and that files can be created in that directory. [ErrorCode = 105005] [SQLState = S0001]
上記のエラーは、おそらく次のことを意味します。
-
サービスプリンシパル クレデンシャルに、PolyBase の書き込み操作に対する十分なアクセス許可がありません
サービスプリンシパルが 、外部データソース オプションを使用した PolyBase に必要な Azure Synapse 権限を持っていることを確認します。
-
ステージング ストレージ アカウントには、 Azure データレイク Storage 機能はありません。
Azure Blob Storage は、Azure データレイク Storage 機能を使用してアップグレードできます。
-
サービスプリンシパル/マネージドサービス ID には、 Azure データレイク Storage に対する "Storage Blob Data Contributor" ロールがありません。
-
その他のトラブルシューティングについては、Azure Blob Storage に対して CETAS 操作を行うときのエラー 105005を参照してください。