ベアラートークンで共有されたデータを読み取る
このページでは、ベアラー トークンを用いたOpenSharingオープンシェアリングプロトコルを使用して、共有されたデータを読み取る方法について説明します。以下のツールを使用して共有データを読み取る手順が含まれています。
この共有モデルでは、データプロバイダーによってチームのメンバーと共有される資格情報ファイルを使用して、共有データへの安全な読み取りアクセスを取得します。アクセスは、資格情報が有効であり、プロバイダーがデータの共有を継続している限り継続されます。プロバイダーは資格情報の期限切れとローテーションを管理します。データの更新は、ほぼリアルタイムで利用可能です。共有データを読み取ったり、コピーを作成したりできますが、ソースデータは変更できません。
Databricks-to-Databricks OpenSharing を使用してデータが共有されている場合、データにアクセスするために資格情報ファイルは必要なく、このページは適用されません。代わりに、「Databricks-to-Databricks OpenSharing を使用して共有されたデータを読み取る (受信者向け)」を参照してください。
以下のセクションでは、資格情報ファイルを使用して共有データにアクセスし、読み取るために、Apache Spark、pandas、Power BI、およびIcebergクライアントを使用する方法について説明します。OpenSharing コネクタの全リストと使用方法に関する情報については、OpenSharing オープンソースドキュメントを参照してください。共有データへのアクセスで問題が発生した場合は、データプロバイダーに連絡してください。
始める前に
チームのメンバーは、データプロバイダーが共有した認証情報ファイルをダウンロードし、安全なチャンネルを介して、そのファイルまたはファイルの場所を共有する必要があります。「Databricks間オープン共有モデルでアクセスする」を参照してください。
コネクタ固有のドキュメントについては、資格情報ダウンロードページを参照してください。
Iceberg クライアント: 共有データを読み取る
Snowflake、Trino、Flink、Spark などの外部 Iceberg クライアントを使用して、Apache Iceberg REST Catalog API を利用したゼロコピーアクセスで共有データ資産を読み取ります。
接続認証情報を取得する
外部の Iceberg クライアントを使用して共有データアセットにアクセスする前に、以下の認証情報を収集してください:
- Iceberg RESTカタログエンドポイント
- 有効なベアラートークン
- 共有名
- (オプション) 名前空間またはスキーマ名
- (任意)テーブル名
Iceberg RESTカタログのエンドポイント(icebergEndpoint)およびベアラートークンは、データプロバイダーから共有された資格情報ファイルにあります。詳細については、始める前にを参照してください。共有名、ネームスペース、およびテーブル名は、OpenSharing APIs を使用してプログラムで取得できます。
icebergEndpoint は資格情報ファイル内にあり、形式は <workspace-url>/api/2.0/delta-sharing/metastores/<metastore-id>/iceberg です。
以下の例は、追加の認証情報を取得する方法を示しています。必要に応じて、エンドポイント、Icebergエンドポイント、および認証情報ファイルからBearerトークンを入力してください:
// List shares
curl -X GET "<endpoint>/shares" \
-H "Authorization: Bearer <bearerToken>"
// List namespaces
curl -X GET "<icebergEndpoint>/v1/shares/<share>/namespaces" \
-H "Authorization: Bearer <bearerToken>"
// List tables
curl -X GET "<icebergEndpoint>/v1/shares/<share>/namespaces/<namespace>/tables" \
-H "Authorization: Bearer <bearerToken>"
この方法は、常に最新のアセットのリストを取得します。ただし、インターネットアクセスが必要であり、ノーコード環境での統合はより困難になる場合があります。
Iceberg カタログを構成する
必要な接続資格情報を取得したら、クライアントを設定して、Iceberg REST Catalog エンドポイントを使用し、テーブルを作成およびクエリできるようにします。
-
各共有について、カタログ統合を作成します。
SQLUSE ROLE ACCOUNTADMIN;
CREATE OR REPLACE CATALOG INTEGRATION <CATALOG_PLACEHOLDER>
CATALOG_SOURCE = ICEBERG_REST
TABLE_FORMAT = ICEBERG
REST_CONFIG = (
CATALOG_URI = '<icebergEndpoint>',
WAREHOUSE = '<share_name>',
ACCESS_DELEGATION_MODE = VENDED_CREDENTIALS
)
REST_AUTHENTICATION = (
TYPE = BEARER,
BEARER_TOKEN = '<bearerToken>'
)
ENABLED = TRUE; -
必要に応じて、メタデータを最新の状態に保つために
REFRESH_INTERVAL_SECONDSを追加します。カタログの更新頻度に基づいて値を設定します。SQLREFRESH_INTERVAL_SECONDS = 30 -
カタログの構成後、そのカタログからデータベースを作成します。これにより、そのカタログ内のすべてのスキーマとテーブルが自動的に作成されます。
SQLCREATE DATABASE <DATABASE_PLACEHOLDER>
LINKED_CATALOG = (
CATALOG = <CATALOG_PLACEHOLDER>
); -
共有が成功したことを確認するには、データベース内のテーブルからクエリを実行します。Databricksからの共有データが表示されます。
結果が空であるかエラーが発生した場合は、次の一般的なトラブルシューティングステップに従ってください:
- 権限、スナップショット生成ステータス、およびREST認証情報を再確認してください。
- データプロバイダーに連絡してください。
- お使いのIcebergクライアント固有のドキュメントを参照してください。
例: 異なるIcebergクライアントを使用して共有テーブルにアクセスする
以下の例では、接続資格情報を取得した後、Snowflake、Apache Spark、PyIceberg、REST API などの外部Icebergクライアントを使用してオープン共有テーブルにアクセスする方法を示します。接続資格情報の詳細については、開始する前にを参照してください。
- Snowflake
- Apache Spark
- PyIceberg
- REST API
Snowflakeで共有データ資産を読み取るには、ダウンロードした認証情報ファイルをアップロードし、必要なSQLコマンドを生成します。
-
オープン共有アクティベーションリンクから、Snowflakeアイコンをクリックしてください。
-
Snowflakeの統合ページで、データプロバイダーから受け取った認証情報ファイルをアップロードします。
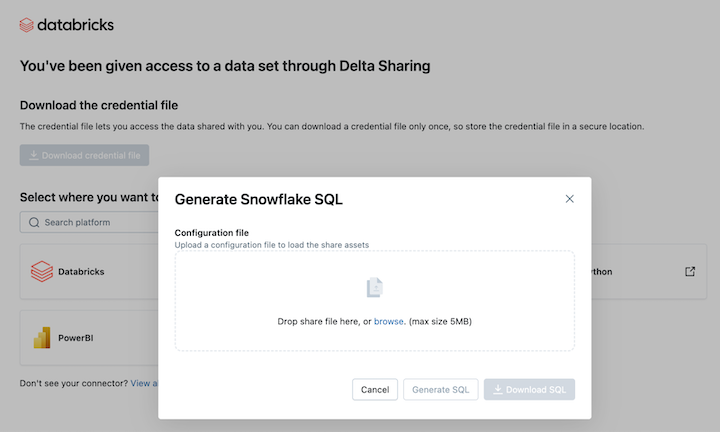
-
認証情報を読み込んだら、Snowflakeでアクセスしたい共有を選択してください。
-
目的のアセットを選択した後で、 Generate SQL をクリックします。
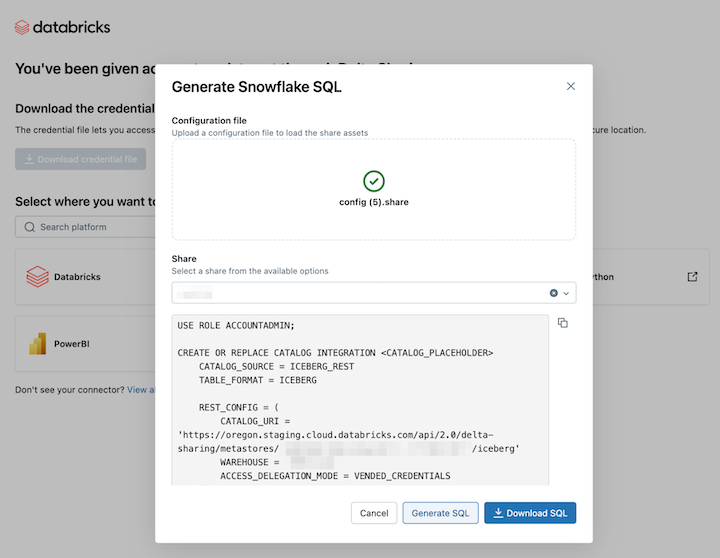
-
生成された SQL を Snowflake ワークシートにコピーして貼り付けます。
CATALOG_PLACEHOLDERを使用するカタログの名前に、DATABASE_PLACEHOLDERを使用するデータベースの名前に置き換えます。
制限事項
Snowflake の Iceberg REST カタログに接続する場合、次の制限があります:
- メタデータファイルは最新のスナップショットで自動的に更新されません。自動更新または手動更新に依存する必要があります。
- R2 はサポートされていません。
- Iceberg クライアントの制限事項がすべて適用されます。
Apache Spark を使用して共有テーブルにアクセスするには、次の設定で Iceberg REST Catalog API を構成します。<spark-catalog-name>をカタログ名に置き換え、接続資格情報を指定してください:
"spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions",
# Configuration for accessing tables shared using Delta Sharing
"spark.sql.catalog.<spark-catalog-name>":"org.apache.iceberg.spark.SparkCatalog",
"spark.sql.catalog.<spark-catalog-name>.type": "rest",
"spark.sql.catalog.<spark-catalog-name>.uri": "<icebergEndpoint>",
"spark.sql.catalog.<spark-catalog-name>.token": "<bearerToken>",
"spark.sql.catalog.<spark-catalog-name>.warehouse":"<share_name>",
"spark.sql.catalog.<spark-catalog-name>.scope":"all-apis"
PyIceberg は、JVM を使用せずに Iceberg テーブルにアクセスするための Python 実装です。PyIceberg には、データの読み取りやテーブル メタデータの検査などのテーブル操作には pyarrow が必要です。pyarrow エクストラを使用して PyIceberg をインストールします:
pip install "pyiceberg[pyarrow]"
共有テーブルにアクセスするには、次のカタログ構成をPyIceberg構成ファイルに追加します。
catalog:
delta_sharing:
type: rest
uri: <icebergEndpoint>
warehouse: <share_name>
token: <bearerToken>
データファイルにアクセスするための一時的な認証情報とともに、テーブルをロードしてそのメタデータを取得するには、以下のcurl例のようなREST API呼び出しを使用します:
curl -X GET -H "Authorization: Bearer <bearerToken>" -H "Accept: application/json" \
<icebergEndpoint>/v1/shares/<share_name>/namespaces/<schema_name>/tables/<table_name>
応答には、Iceberg テーブルのメタデータ、S3 ロケーション、およびクライアントがデータファイルを読み取ることを許可する一時的な AWS 資格情報が含まれます。
{
"metadata-location": "s3://bucket/path/to/iceberg/table/metadata/file",
"metadata": <iceberg-table-metadata-json>,
"config": {
"expires-at-ms": "<epoch-ts-in-millis>",
"s3.access-key-id": "<temporary-s3-access-key-id>",
"s3.session-token": "<temporary-s3-session-token>",
"s3.secret-access-key": "<temporary-secret-access-key>",
"client.region": "<aws-bucket-region-for-metadata-location>"
}
}
Icebergクライアントの制限
IcebergクライアントからOpenSharingデータをクエリする際に、次の制限が適用されます。
- 名前空間でテーブルをリストする際に、名前空間に100を超える共有ビューが含まれている場合、応答は最初の100個のビューに制限されます。
Apache Spark: 共有データの読み取り
Spark 3.x以降を使用して共有データにアクセスするには、次のステップに従ってください。
これらの手順は、データプロバイダーによって共有された認証情報ファイルにアクセスできることを前提としています。「Databricks間オープン共有モデルでアクセスする」を参照してください。
Apache Spark から資格情報ファイルにアクセスできるように、絶対パスを使用してください。パスは、クラウドオブジェクトまたは Unity Catalog ボリュームを参照できます。
Unity Catalog が有効な Databricks ワークスペースで Spark を使用しており、インポートプロバイダー UI を使用してプロバイダーと共有をインポートした場合、このセクションの指示は適用されません。Unity Catalog に登録されている他のテーブルと同様に、共有テーブルにアクセスできます。delta-sharing Python コネクタをインストールしたり、資格情報ファイルへのパスを指定したりする必要はありません。「Databricks でプロバイダーをインポートし、共有データを読み取る」を参照してください。
OpenSharing Python および Spark コネクタをインストールする
共有データに関連するメタデータ、たとえば共有されているテーブルの一覧にアクセスするには、次の手順を実行します。この例では Python を使用しています。
-
delta-sharing Python コネクタをインストールします。Python コネクタの制限事項に関する情報については、OpenSharing Python コネクタの制限事項を参照してください。
Bashpip install delta-sharing -
Apache Spark コネクタをインストールします。
Spark を使用した共有テーブルの一覧表示
共有内のテーブルを一覧表示します。次の例では、<profile-path> を資格情報ファイルの場所に置き換えます。
import delta_sharing
client = delta_sharing.SharingClient(f"<profile-path>/config.share")
client.list_all_tables()
結果は、各テーブルのメタデータとともにテーブルの配列になります。次の出力には2つのテーブルが表示されます。
Out[10]: [Table(name='example_table', share='example_share_0', schema='default'), Table(name='other_example_table', share='example_share_0', schema='default')]
出力が空であるか、予期したテーブルが含まれていない場合は、データプロバイダーにお問い合わせください。
Spark を使用した共有データへのアクセス
以下を実行し、これらの変数を置き換えてください:
<profile-path>:認証情報ファイルの場所。<share-name>テーブルのshare=の値。<schema-name>テーブルのschema=の値。<table-name>テーブルのname=の値。<version-as-of>:オプション。 データを読み込むテーブルのバージョン。 データ プロバイダーがテーブルの履歴を共有している場合にのみ機能します。delta-sharing-spark0.5.0 以上が必要です。<timestamp-as-of>:オプション。 指定されたタイムスタンプより前または指定されたタイムスタンプのバージョンでデータをロードします。 データ プロバイダーがテーブルの履歴を共有している場合にのみ機能します。 0.6.0 以上のdelta-sharing-sparkが必要です。
- Python
- Scala
delta_sharing.load_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>", version=<version-as-of>)
spark.read.format("deltaSharing")\
.option("versionAsOf", <version-as-of>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")\
.limit(10)
delta_sharing.load_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>", timestamp=<timestamp-as-of>)
spark.read.format("deltaSharing")\
.option("timestampAsOf", <timestamp-as-of>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")\
.limit(10)
spark.read.format("deltaSharing")
.option("versionAsOf", <version-as-of>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.limit(10)
spark.read.format("deltaSharing")
.option("timestampAsOf", <version-as-of>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.limit(10)
Sparkを使用した共有チェンジデータフィードへのアクセス
テーブル履歴が共有されており、ソーステーブルでチェンジデータフィード (CDF) が有効になっている場合は、以下の変数に置き換えて実行することでチェンジデータフィードにアクセスします。delta-sharing-spark 0.5.0 以降が必要です。
1つの開始パラメーターを指定する必要があります。
<profile-path>:認証情報ファイルの場所。<share-name>テーブルのshare=の値。<schema-name>テーブルのschema=の値。<table-name>テーブルのname=の値。<starting-version>:オプション。 クエリーの開始バージョン。 長整数型として指定します。<ending-version>:オプション。 クエリの終了バージョン。 終了バージョンが指定されていない場合、API は最新のテーブル バージョンを使用します。<starting-timestamp>:オプション。 クエリーの開始タイムスタンプは、このタイムスタンプ以上で作成されたバージョンに変換されます。yyyy-mm-dd hh:mm:ss[.fffffffff]の形式の文字列として指定します。<ending-timestamp>:オプション。 クエリーの終了タイムスタンプは、このタイムスタンプ以前に作成されたバージョンに変換されます。 次の形式の文字列として指定します。yyyy-mm-dd hh:mm:ss[.fffffffff]
- Python
- Scala
delta_sharing.load_table_changes_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_version=<starting-version>,
ending_version=<ending-version>)
delta_sharing.load_table_changes_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_timestamp=<starting-timestamp>,
ending_timestamp=<ending-timestamp>)
spark.read.format("deltaSharing").option("readChangeFeed", "true")\
.option("startingVersion", <starting-version>)\
.option("endingVersion", <ending-version>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.read.format("deltaSharing").option("readChangeFeed", "true")\
.option("startingTimestamp", <starting-timestamp>)\
.option("endingTimestamp", <ending-timestamp>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.read.format("deltaSharing").option("readChangeFeed", "true")
.option("startingVersion", <starting-version>)
.option("endingVersion", <ending-version>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.read.format("deltaSharing").option("readChangeFeed", "true")
.option("startingTimestamp", <starting-timestamp>)
.option("endingTimestamp", <ending-timestamp>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
出力が空であるか、予期するデータが含まれていない場合は、データプロバイダーにお問い合わせください。
Spark構造化ストリーミングを使用して共有テーブルにアクセスします。
テーブルの履歴が共有されている場合、共有データをストリームで読み取ることができます。0.6.0 以上の delta-sharing-spark が必要です。
サポート対象オプション:
ignoreDeletes: データを削除するトランザクションを無視します。ignoreChangesデータ変更操作(UPDATE、MERGE INTO、DELETE(パーティション内)、またはOVERWRITEなど)によってソーステーブル内のファイルが書き換えられた場合は、更新を再処理します。変更されていない行が引き続き出力されることがあります。したがって、ダウンストリームコンシューマは重複を処理できる必要があります。削除はダウンストリームに反映されません。ignoreChangesはignoreDeletesを包含します。したがって、ignoreChangesを使用する場合、ストリームはソーステーブルへの削除または更新によって中断されません。startingVersion:開始する共有テーブルのバージョン。このバージョン (このバージョンを含む) 以降のすべてのテーブル変更は、ストリーミングソースによって読み取られます。startingTimestamp: 開始するタイムスタンプです。タイムスタンプ以降にコミットされたすべてのテーブル変更(タイムスタンプを含む)は、ストリーミングソースによって読み取られます。例:"2023-01-01 00:00:00.0"。maxFilesPerTrigger:各マイクロバッチで考慮される新しいファイルの数。maxBytesPerTrigger:各マイクロバッチで処理されるデータの量。このオプションは「ソフトマックス」を設定します。つまり、バッチはおおよそこの量のデータを処理し、最小の入力単位がこの制限よりも大きい場合にストリーミングクエリーを進めるために、制限を超えるデータを処理する可能性があります。readChangeFeed:共有テーブルのチェンジデータフィードをストリーム読み込みします。
サポートされているトリガー:
Trigger.ProcessingTime:明示的なTriggerが指定されていない場合に使用されるdefault Trigger。データは連続的なマイクロバッチで処理されます。Trigger.AvailableNowクエリーは共有テーブルのサーバーサイドバージョンを開始時にキャプチャし、maxFilesPerTriggerとmaxVersionsPerRpcに準拠する複数のマイクロバッチとしてバックログを処理し、キャプチャされたバージョンが使い果たされると終了します。delta-sharing-spark1.4.0 以降が必要です。以前のバージョンは、maxVersionsPerRpcを考慮しないTrigger.AvailableNowラッパーにフォールバックします。Trigger.Once:非推奨;代わりにTrigger.AvailableNowを使用してください。1.4.0未満のdelta-sharing-sparkのバージョンでは、Trigger.AvailableNowは、maxVersionsPerRpcを考慮しないラッパーに戻ります。
構造化ストリーミングクエリのサンプル
- Python
- Scala
spark.readStream.format("deltaSharing")\
.option("startingVersion", 0)\
.option("ignoreDeletes", true)\
.option("maxBytesPerTrigger", 10000)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.readStream.format("deltaSharing")
.option("startingVersion", 0)
.option("ignoreChanges", true)
.option("maxFilesPerTrigger", 10)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
構造化ストリーミングの概念も参照してください。
削除ベクトルまたはカラムマッピングが有効なテーブルの読み取り
プレビュー
この機能は パブリック プレビュー段階です。
削除ベクトルは、プロバイダーが共有Deltaテーブルで有効にできるストレージ最適化機能です。「Databricks の削除ベクトル」を参照してください。
Databricks では、Delta テーブルの列マッピングもサポートされています。 Delta Lake 列マッピングを使用した列の名前変更と削除を参照してください。
プロバイダーが削除ベクトルまたは列マッピングが有効になっているテーブルを共有している場合は、 delta-sharing-spark 3.1 以降で実行されているコンピュートを使用してテーブルを読み取ることができます。 Databricks クラスターを使用している場合は、Databricks Runtime 14.1 以降を実行しているクラスターを使用してバッチ読み取りを実行できます。CDF クエリとストリーミング クエリには、Databricks Runtime 14.2 以降が必要です。
共有テーブルのテーブル機能に基づいてresponseFormatを自動的に解決できるため、バッチクエリをそのまま実行できます。
チェンジデータフィード(CDF)を読み取るか、削除ベクトルまたは列マッピングが有効になっている共有テーブルでストリーミングクエリを実行するには、追加オプションresponseFormat=deltaを設定する必要があります。
以下にバッチ、CDF、およびストリーミング クエリの例を示します。
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("...")
.master("...")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
.getOrCreate()
val tablePath = "<profile-file-path>#<share-name>.<schema-name>.<table-name>"
// Batch query
spark.read.format("deltaSharing").load(tablePath)
// CDF query
spark.read.format("deltaSharing")
.option("readChangeFeed", "true")
.option("responseFormat", "delta")
.option("startingVersion", 1)
.load(tablePath)
// Streaming query
spark.readStream.format("deltaSharing").option("responseFormat", "delta").load(tablePath)
共有テーブルの行追跡列を読み取る
データプロバイダーが共有テーブルで行追跡を有効にしている場合、Scala Spark を使用して行追跡メタデータ列をクエリできます。利用可能な列のリストについては、Databricks の行追跡をご覧ください。
responseFormat オプションを delta に設定する必要があります。
spark.read.format("deltaSharing")
.option("responseFormat", "delta")
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.select("_metadata.row_id")
.show()
Spark クライアントで行トラッキング列をクエリする場合、デルタレスポンス形式のみがサポートされています。ダンプコネクタはサポートされていません。
Pandas: 共有データの読み取り
pandas 0.25.3 以降で共有データにアクセスするには、次のステップに従ってください。
これらの手順は、データプロバイダーによって共有された認証情報ファイルにアクセスできることを前提としています。「Databricks間オープン共有モデルでアクセスする」を参照してください。
Unity Catalog が有効になっている Databricks ワークスペースで pandas を使用しており、プロバイダーと共有をインポートするためにインポートプロバイダー UI を使用した場合は、このセクションの手順は適用されません。Unity Catalog に登録されている他のテーブルと同様に、共有テーブルにアクセスできます。delta-sharing Python コネクタをインストールしたり、資格情報ファイルへのパスを提供したりする必要はありません。Databricksでプロバイダーをインポートし、共有データを読み取るを参照してください。
OpenSharing Python コネクタをインストールします
共有されているテーブルの一覧など、共有データに関連するメタデータにアクセスするには、delta-sharing Python コネクタをインストールする必要があります。Python コネクタの制限事項に関する情報については、OpenSharing Python コネクタの制限事項を参照してください。
pip install delta-sharing
共有テーブルの一覧表示: pandas
共有内のテーブルを一覧表示するには、次を実行し、<profile-path>/config.shareを資格情報ファイルの場所に置き換えます。
import delta_sharing
client = delta_sharing.SharingClient(f"<profile-path>/config.share")
client.list_all_tables()
出力が空であるか、予期したテーブルが含まれていない場合は、データプロバイダーにお問い合わせください。
を使用して共有データにアクセスする pandas
Pythonを使用してpandasで共有データにアクセスするには、変数を次のように置き換えて、以下を実行してください。
<profile-path>:認証情報ファイルの場所。<share-name>テーブルのshare=の値。<schema-name>テーブルのschema=の値。<table-name>テーブルのname=の値。
import delta_sharing
delta_sharing.load_as_pandas(f"<profile-path>#<share-name>.<schema-name>.<table-name>")
共有チェンジデータフィードへのアクセス pandas
Python を使用して pandas の共有テーブルのチェンジデータフィードにアクセスするには、次を実行します。その際、変数を次のように置き換えてください。チェンジデータフィードが利用できない場合があります。これは、データプロバイダーがそのテーブルのチェンジデータフィードを共有したかどうかに依存します。
<starting-version>:オプション。 クエリーの開始バージョン。<ending-version>:オプション。 クエリの終了バージョン。<starting-timestamp>:オプション。 クエリーの開始タイムスタンプ。 これは、このタイムスタンプ以降に作成されたバージョンに変換されます。<ending-timestamp>:オプション。 クエリーの終了タイムスタンプ。 これは、このタイムスタンプ以前に作成されたバージョンに変換されます。
import delta_sharing
delta_sharing.load_table_changes_as_pandas(
f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_version=<starting-version>,
ending_version=<ending-version>)
delta_sharing.load_table_changes_as_pandas(
f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_timestamp=<starting-timestamp>,
ending_timestamp=<ending-timestamp>)
出力が空であるか、予期するデータが含まれていない場合は、データプロバイダーにお問い合わせください。
Power BI: 共有データの読み取り
Power BI OpenSharingコネクタにより、ユーザーはOpenSharingオープンプロトコルを通じて共有されたデータセットを探索、分析、視覚化することができます。
要件
- Power BI Desktop 2.99.621.0以降。
- データプロバイダーから共有された認証情報ファイルへのアクセス「Databricks間オープン共有モデルでアクセスする」を参照してください。
Databricks に接続する
OpenSharingコネクタを使用してDatabricksに接続するには、次を実行します:
- 共有資格情報ファイルをテキストエディターで開き、エンドポイント URL とトークンを取得します。
- Power BI Desktopを開きます。
- 「 データの取得 」メニューで、 OpenSharing を検索します。
- コネクタを選択し、 接続 をクリックします。
- 資格情報ファイルからコピーしたエンドポイント URL を、 OpenSharing Server URL フィールドに入力してください。
- 必要に応じて、[ 詳細オプション ] タブで、ダウンロードできる行の最大数の [行制限 ] を設定します。 これは、デフォルトで 100 万行に設定されます。
- OK をクリックします。
- 認証 の場合、資格情報ファイルから取得したトークンを ベアラー トークン に貼り付けます。
- 接続 をクリックします。
Power BI オープン共有コネクタの制限事項
Power BI オープン共有コネクタには次の制限事項があります:
- コネクタが読み込むデータは、マシンのメモリに収まる必要があります。この要件を管理するために、コネクタは、Power BI Desktop の [詳細オプション] タブで設定した 行制限 までインポートされる行数を制限します。
Tableau:共有データの読み取り
Tableau OpenSharingコネクタにより、ユーザーはOpenSharingオープンプロトコルを通じて共有されているデータセットを探索、分析、視覚化することができます。
要件
- Tableau Desktop および Tableau Server 2024.1 以降
- データプロバイダーから共有された認証情報ファイルへのアクセス「Databricks間オープン共有モデルでアクセスする」を参照してください。
Databricks に接続する
OpenSharingコネクタを使用してDatabricksに接続するには、次を実行します:
- Tableau Exchange にアクセスし、OpenSharing Connector をダウンロードする手順に従い、適切なデスクトップフォルダーに配置してください。
- Tableau Desktop を開きます。
- コネクタ ページで、「OpenSharing by Databricks」を検索します。
- 「共有ファイルをアップロード」を選択し、プロバイダーから共有された認証情報ファイルを選択します。
- 「 Get Data 」をクリックします。
- Data Explorer でテーブルを選択します。
- オプションで SQL フィルターまたは行制限を追加します。
- [Get Table Data] をクリックします。
制限事項
Tableau OpenSharing コネクタには次の制限事項があります:
- コネクタが読み込むデータは、マシンのメモリに収まる必要があります。この要件に対応するため、コネクタはTableauで設定した行制限までインポートされる行数を制限します。
- すべての列は
String型として返されます。 - SQL フィルターは、OpenSharing サーバーが predicateHint をサポートしている場合にのみ機能します。
- 削除ベクトルはサポートされていません。
- 列マッピングはサポートされていません。
OpenSharing Python コネクターの制限事項
これらの制限事項は、OpenSharing Python コネクターに固有のものです。
- OpenSharing Pythonコネクター 1.1.0 以降列マッピングが有効なテーブルではスナップショットクエリをサポートしていますが、列マッピングが有効なテーブルでの CDF クエリはサポートされていません。
- クエリ対象のバージョン範囲でスキーマが変更された場合、OpenSharing PythonコネクタのCDFクエリは
use_delta_format=Trueによって失敗します。
ストリーミングテーブルの制限
共有ストリーミングテーブルの現在のスナップショットのみを読み取ることができます。Databricks-to-Open Sharing では、ストリーミングテーブルに以下の機能はサポートされていません。
- テーブルの履歴データをクエリーする
- テーブルのチェンジデータフィード (CDF) のクエリ
- Spark 構造化ストリーミングのソースとしてテーブルを使用する
マテリアライズドビューの制限事項
共有マテリアライズドビューの現在のスナップショットのみ読み取ることができます。Databricks-to-Open共有では、Spark 構造化ストリーミングのソースとしてマテリアライズドビューを使用することはサポートされていません。
新しい資格情報の要求
認証情報の有効化URLまたはダウンロードした認証情報が失われたり、破損したり、不正使用された場合、あるいはプロバイダーから新しい認証情報が送られてこずに有効期限が切れた場合は、プロバイダーに連絡して新しい認証情報を要求してください。
Unity Catalog でプロバイダーオブジェクトとして認証情報をインポートした Databricks 受信者の場合は、Databricks REST API を使用して新しい認証情報を適用します。オープン受信者の認証情報をローテーションするを参照してください。