チェンジデータキャプチャ( CDC )とは何ですか?
変更データキャプチャ ( CDC ) は、挿入、更新、削除など、ソース システム内のデータに加えられた変更をキャプチャするデータ統合パターンです。 リストとして表されるこれらの変更は、一般的に CDC フィード と呼ばれます。ソース データセット全体を読み取るのではなく、CDC フィードに対して操作すると、データをはるかに高速に処理できます。SQL Server、MySQL、Oracle などのトランザクション データベースは CDC フィードを生成します。Deltaテーブルは、変更データフィード (CDF) と呼ばれる独自のCDCフィードを生成します。
次の図は、従業員データを含むソース テーブルの行が更新されると、変更 のみを 含む CDC フィードに新しい行セットが生成されることを示しています。CDC フィード の各行には通常、 UPDATEなどの操作や、順序どおりでない更新を処理できるように CDC フィード内の各行を確定的に順序付けるために使用できる列などの追加のメタデータが含まれます。たとえば、次の図のsequenceNum列は CDC フィード内の行の順序を決定します。
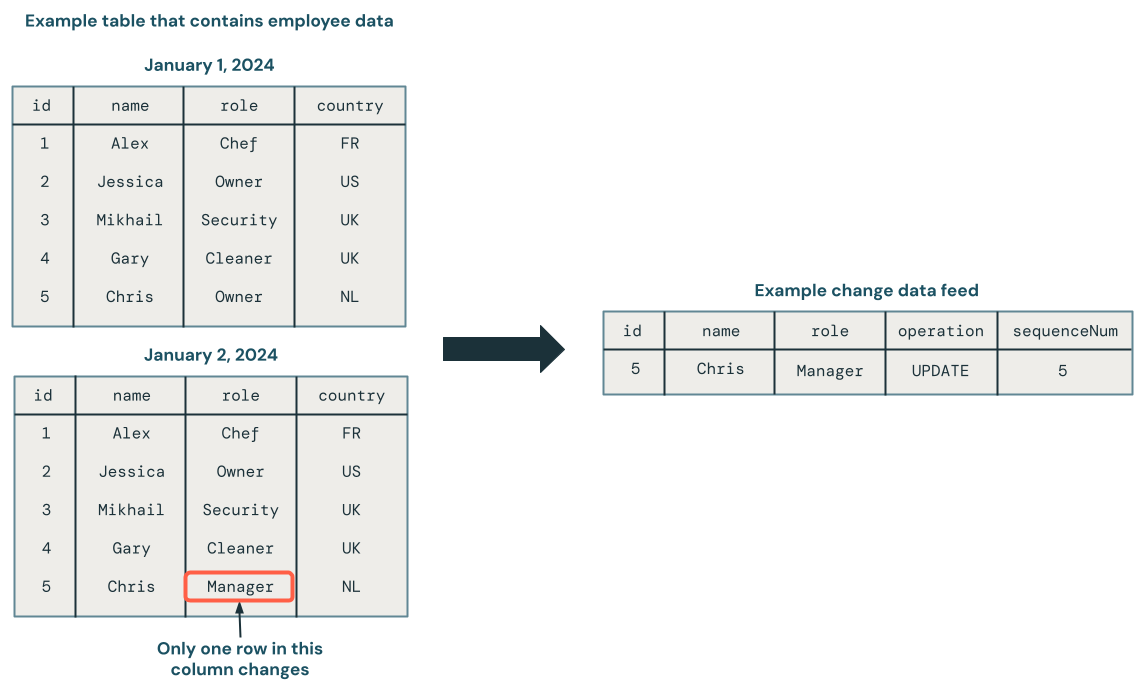
変更データフィードの処理: 最新データのみを保持するか、データの履歴バージョンを保持するか
変更データフィードの処理は 、 slowly changing dimensions ( SCD ) として知られています。 CDC フィードを処理するときは、次の選択肢があります。
- 最新のデータのみを保持しますか (つまり、既存のデータを上書きしますか)?これは SCD タイプ 1 として知られています。
- あるいは、データの変更履歴を保存していますか?これは SCD タイプ 2 として知られています。
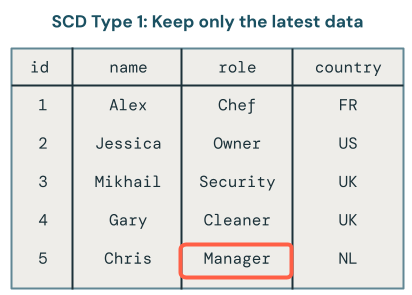
SCD タイプ 1 処理では、変更が発生するたびに古いデータが新しいデータで上書きされます。つまり、変更の履歴は保存されません。最新バージョンのデータのみが利用可能です。これは簡単なアプローチであり、エラーの修正や顧客の E メール アドレスなどの重要でないフィールドの更新など、変更履歴が重要でない場合によく使用されます。
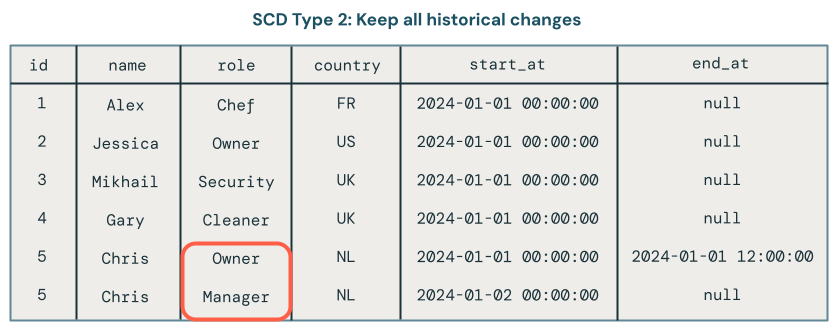
SCD タイプ 2 処理では、時間の経過に伴うデータのさまざまなバージョンをキャプチャするための追加レコードを作成することにより、データ変更の履歴レコードが維持されます。データの各バージョンにはタイムスタンプが付けられるか、メタデータがタグ付けされるため、ユーザーは変更がいつ発生したかを追跡できます。これは、分析の目的で時間の経過に伴う顧客住所の変更を追跡するなど、データの進化を追跡することが重要な場合に役立ちます。
Lakeflow Spark宣言型パイプラインを使用したSCDタイプ 1 およびタイプ 2 の処理の例
このセクションの例では、SCD タイプ 1 とタイプ 2 の使用方法を示します。
ステップ1: サンプルデータを準備する
この例では、サンプル CDC フィードを生成します。まず、ノートブックを作成し、次のコードを貼り付けます。コード ブロックの先頭にある変数を、テーブルとビューを作成する権限があるカタログとスキーマに更新します。
このコードは、複数の変更レコードを含む新しい Delta テーブルを作成します。スキーマは次のとおりです。
id- この従業員の一意の識別子(整数)name- 文字列、従業員名role- 文字列、従業員の役割country- 文字列、国コード、従業員の勤務地operation- タイプを変更する(例:INSERT、UPDATE、DELETE)sequenceNum- 整数。ソース データ内の CDC イベントの論理順序を識別します。Lakeflow Spark宣言型パイプラインは、このシーケンスを使用して、順序どおりに到着しない変更イベントを処理します。
# update these to the catalog and schema where you have permissions
# to create tables and views.
catalog = "mycatalog"
schema = "myschema"
employees_cdf_table = "employees_cdf"
def write_employees_cdf_to_delta():
data = [
(1, "Alex", "chef", "FR", "INSERT", 1),
(2, "Jessica", "owner", "US", "INSERT", 2),
(3, "Mikhail", "security", "UK", "INSERT", 3),
(4, "Gary", "cleaner", "UK", "INSERT", 4),
(5, "Chris", "owner", "NL", "INSERT", 6),
# out of order update, this should be dropped from SCD Type 1
(5, "Chris", "manager", "NL", "UPDATE", 5),
(6, "Pat", "mechanic", "NL", "DELETE", 8),
(6, "Pat", "mechanic", "NL", "INSERT", 7)
]
columns = ["id", "name", "role", "country", "operation", "sequenceNum"]
df = spark.createDataFrame(data, columns)
df.write.format("delta").mode("overwrite").saveAsTable(f"{catalog}.{schema}.{employees_cdf_table}")
write_employees_cdf_to_delta()
次の SQL コマンドを使用してこのデータをプレビューできます。
SELECT *
FROM mycatalog.myschema.employees_cdf
ステップ 2: SCD Type 1 を使用して最新のデータのみを保持する
Lakeflow Spark宣言型パイプラインでAUTO CDC API使用して、変更データフィードをSCDタイプ 1 テーブルに処理することをお勧めします。
- 新しいノートブックを作成します。
- そこに次のコードを貼り付けます。
- パイプラインを作成して接続します。
変更データ キャプチャ処理に使用するcreate_auto_cdc_flow APIは入力として変更のストリームを期待するため、 employees_cdf関数は上で作成したテーブルをストリームとして読み取ります。 このストリームをテーブルに具体化したくないので、デコレータ@dp.temporary_viewでラップします。
次に、 dp.create_target_tableを使用して、この変更データフィードの処理結果を含むストリーミング テーブルを作成します。
最後に、 dp.create_auto_cdc_flowを使用して変更データフィードを処理します。 それぞれの議論を見てみましょう。
target- ターゲットのストリーミング テーブル。以前に定義したものです。source- 以前に定義した変更レコードのストリームのビュー。keys- 変更フィード内の一意の行を識別します。id一意の識別子として使用しているため、識別列としてidのみを指定します。sequence_by- ソース データ内の CDC イベントの論理順序を指定する列名。順序どおりに到着しない変更イベントを処理するには、このシーケンスが必要です。シーケンス列としてsequenceNum指定します。apply_as_deletes- サンプル データには削除操作が含まれているため、apply_as_deletes使用して、CDC イベントを upsert ではなくDELETEとして扱う必要があることを示します。except_column_list- ターゲット テーブルに含めたくない列のリストが含まれます。この例では、この引数を使用してsequenceNumとoperationを除外します。stored_as_scd_type- 使用する SCD タイプを示します。
from pyspark import pipelines as dp
from pyspark.sql.functions import col, expr, lit, when
from pyspark.sql.types import StringType, ArrayType
catalog = "mycatalog"
schema = "myschema"
employees_cdf_table = "employees_cdf"
employees_table_current = "employees_current"
employees_table_historical = "employees_historical"
@dp.temporary_view
def employees_cdf():
return spark.readStream.format("delta").table(f"{catalog}.{schema}.{employees_cdf_table}")
dp.create_target_table(f"{catalog}.{schema}.{employees_table_current}")
dp.create_auto_cdc_flow(
target=f"{catalog}.{schema}.{employees_table_current}",
source=employees_cdf_table,
keys=["id"],
sequence_by=col("sequenceNum"),
apply_as_deletes=expr("operation = 'DELETE'"),
except_column_list = ["operation", "sequenceNum"],
stored_as_scd_type = 1
)
このパイプラインを実行するには、 開始 をクリックします。
次に、SQL エディターで次のクエリを実行して、変更レコードが正しく処理されたことを確認します。
SELECT *
FROM mycatalog.myschema.employees_current
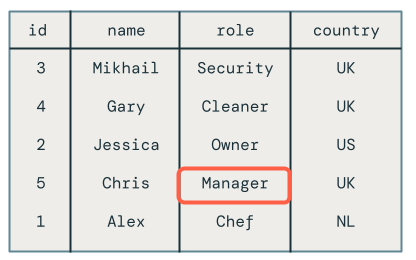
従業員 Chris の役割がまだマネージャーではなくオーナーに設定されているため、従業員 Chris の順序外更新は適切に削除されました。
ステップ 3: SCD Type 2 を使用して履歴データを保存する
この例では、従業員レコードの変更の完全な履歴が含まれる、 employees_historicalという 2 番目のターゲット テーブルを作成します。
このコードをパイプラインに追加します。ここでの唯一の違いは、 stored_as_scd_type 1 ではなく 2 に設定されていることです。
dp.create_target_table(f"{catalog}.{schema}.{employees_table_historical}")
dp.create_auto_cdc_flow(
target=f"{catalog}.{schema}.{employees_table_historical}",
source=employees_cdf_table,
keys=["id"],
sequence_by=col("sequenceNum"),
apply_as_deletes=expr("operation = 'DELETE'"),
except_column_list = ["operation", "sequenceNum"],
stored_as_scd_type = 2
)
このパイプラインを実行するには、 開始 をクリックします。
次に、SQL エディターで次のクエリを実行して、変更レコードが正しく処理されたことを確認します。
SELECT *
FROM mycatalog.myschema.employees_historical
Pat などの削除された従業員も含め、従業員に対するすべての変更が表示されます。
ステップ 4: リソースをクリーンアップする
完了したら、次のステップに従ってリソースをクリーンアップします。
- パイプラインを削除します。
パイプラインを削除すると、 employeesテーブルとemployees_historicalテーブルが自動的に削除されます。
-
[ジョブとパイプライン] をクリックし、削除するパイプラインの名前を見つけます。
-
クリック
 パイプライン名と同じ行で、 [削除] を クリックします。
パイプライン名と同じ行で、 [削除] を クリックします。 -
ノートブックを削除します。
-
変更データフィードを含むテーブルを削除します。
- 新規 > クエリー をクリックします。
- 必要に応じてカタログとスキーマを調整しながら、次の SQL コードを貼り付けて実行します。
DROP TABLE mycatalog.myschema.employees_cdf
チェンジデータ キャプチャにMERGE INTOとforeachBatchを使用する場合の欠点
Databricks には、 foreachBatch API で Delta テーブルに行をアップサートするために使用できるMERGE INTO SQL コマンドが用意されています。このセクションでは、この手法を単純なユースケースで使用する方法を説明しますが、この方法は実際のシナリオに適用するとますます複雑になり、脆弱になります。
この例では、前の例で使用したものと同じサンプル変更データフィードを使用します。
MERGE INTOと foreachBatch
ノートブックを作成し、次のコードをコピーします。必要に応じて、 catalog 、 schema 、およびemployees_table変数を変更します。catalogおよびschema変数は、テーブルを作成できるUnity Catalog内の場所に設定する必要があります。
ノートブックを実行すると、次の処理が行われます。
create_tableにターゲット テーブルを作成します。このステップを自動的に処理するcreate_auto_cdc_flowとは異なり、スキーマを指定する必要があります。- チェンジデータフィードをストリームとして読み込みます。 各マイクロバッチは、
MERGE INTOコマンドを実行するupsertToDeltaメソッドを使用して処理されます。
catalog = "jobs"
schema = "myschema"
employees_cdf_table = "employees_cdf"
employees_table = "employees_merge"
def upsertToDelta(microBatchDF, batchId):
microBatchDF.createOrReplaceTempView("updates")
microBatchDF.sparkSession.sql(f"""
MERGE INTO {catalog}.{schema}.{employees_table} t
USING updates s
ON s.id = t.id
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
def create_table():
spark.sql(f"DROP TABLE IF EXISTS {catalog}.{schema}.{employees_table}")
spark.sql(f"""
CREATE TABLE IF NOT EXISTS {catalog}.{schema}.{employees_table}
(id INT, name STRING, age INT, country STRING)
""")
create_table()
cdcData = spark.readStream.table(f"{catalog}.{schema}.{employees_cdf_table}")
cdcData.writeStream \
.foreachBatch(upsertToDelta) \
.outputMode("append") \
.start()
結果を表示するには、次の SQL クエリを実行します。
SELECT *
FROM mycatalog.myschema.employees_merge
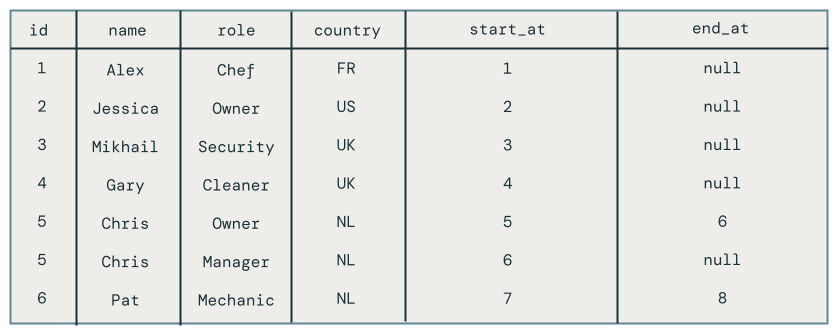
残念ながら、結果は次のように正しくありません。
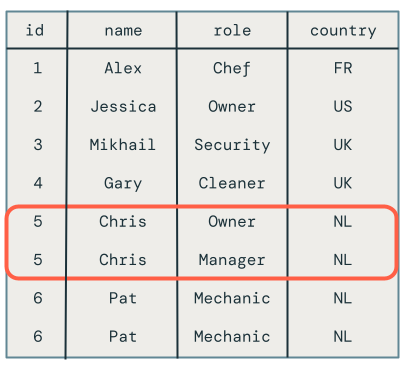
同じマイクロバッチ内で同じキーを複数回更新する
最初の問題は、コードが同じマイクロバッチ内の同じキーへの複数の更新を処理しないことです。たとえば、 INSERTを使用して従業員 Chris を挿入し、その役割をオーナーからマネージャーに更新します。結果として 1 行になるはずですが、代わりに 2 行になります。
マイクロバッチ内の同じキーに複数の更新があった場合、どの変更が優先されますか?
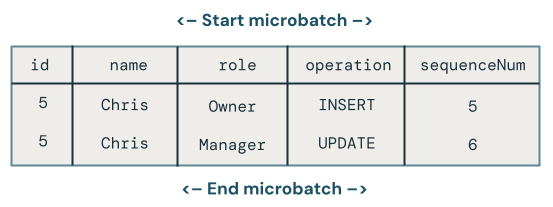
ロジックはより複雑になります。次のコード例では、 sequenceNumの最新の行を取得し、そのデータのみを次のようにターゲット テーブルにマージします。
- 主キー
idでグルーピングします。 - そのキーのバッチ内で最大値
sequenceNumを持つ行のすべての列を取得します。 - 行を爆発的に拡大します。
次に示すようにupsertToDeltaメソッドを更新し、コードを実行します。
def upsertToDelta(microBatchDF, batchId):
microBatchDF = microBatchDF.groupBy("id").agg(
max_by(struct("*"), "sequenceNum").alias("row")
).select("row.*").createOrReplaceTempView("updates")
spark.sql(f"""
MERGE INTO {catalog}.{schema}.{employees_table} t
USING updates s
ON s.id = t.id
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
ターゲット テーブルをクエリすると、Chris という名前の従業員の役割が正しいことがわかりますが、削除されたレコードがターゲット テーブルにまだ表示されているため、解決すべき他の問題がまだ残っています。
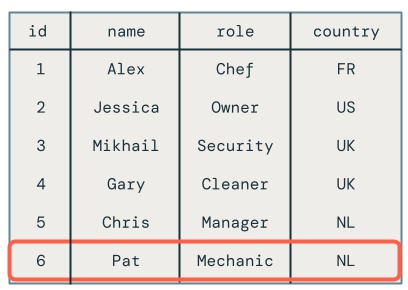
マイクロバッチ間の順序外更新
このセクションでは、マイクロバッチ全体にわたる順序外更新の問題について説明します。次の図は問題を示しています。Chris の行で最初のマイクロバッチで UPDATE 操作が行われ、その後のマイクロバッチで INSERT 操作が行われた場合はどうなるでしょうか。コードはこれを正しく処理しません。
複数のマイクロバッチにわたって同じキーに対して順序どおりでない更新が行われた場合、どの変更が優先されますか?
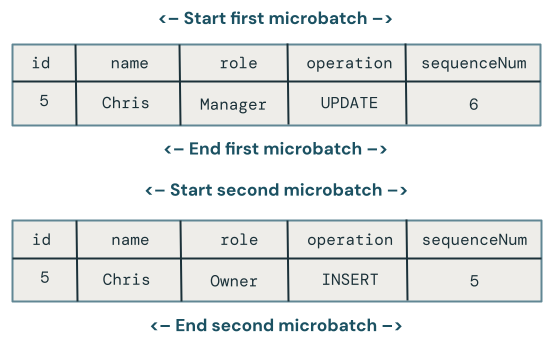
これを修正するには、次のようにコードを拡張して各行にバージョンを保存します。
- 行が最後に更新されたときの
sequenceNumを保存します。 - 新しい行ごとに、タイムスタンプが保存されているものより大きいかどうかを確認し、次のロジックを適用します。
- 大きい場合は、ターゲットからの新しいデータを使用します。
- それ以外の場合は、ソースにデータを保持します。
まず、各行のバージョン管理に使用するため、 sequenceNum格納するようにcreateTableメソッドを更新します。
def create_table():
spark.sql(f"DROP TABLE IF EXISTS {catalog}.{schema}.{employees_table}")
spark.sql(f"""
CREATE TABLE IF NOT EXISTS {catalog}.{schema}.{employees_table}
(id INT, name STRING, age INT, country STRING, sequenceNum INT)
""")
次に、行バージョンを処理するためにupsertToDelta更新します。MERGE INTOのUPDATE SET句では、各列を個別に処理する必要があります。
def upsertToDelta(microBatchDF, batchId):
microBatchDF = microBatchDF.groupBy("id").agg(
max_by(struct("*"), "sequenceNum").alias("row")
).select("row.*").createOrReplaceTempView("updates")
spark.sql(f"""
MERGE INTO {catalog}.{schema}.{employees_table} t
USING updates s
ON s.id = t.id
WHEN MATCHED THEN UPDATE SET
name=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.name ELSE t.name END,
age=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.age ELSE t.age END,
country=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.country ELSE t.country END
WHEN NOT MATCHED THEN INSERT *
""")
削除の処理
残念ながら、コードにはまだ問題があります。従業員 Pat がまだターゲット テーブルに存在することから明らかなように、 DELETE操作は処理されません。
削除が同じマイクロバッチで到着すると仮定しましょう。これらを処理するには、次に示すように、変更データ レコードが削除を示している場合に行を削除するようにupsertToDeltaメソッドを再度更新します。
def upsertToDelta(microBatchDF, batchId):
microBatchDF = microBatchDF.groupBy("id").agg(
max_by(struct("*"), "sequenceNum").alias("row")
).select("row.*").createOrReplaceTempView("updates")
spark.sql(f"""
MERGE INTO {catalog}.{schema}.{employees_table} t
USING updates s
ON s.id = t.id
WHEN MATCHED AND s.operation = 'DELETE' THEN DELETE
WHEN MATCHED THEN UPDATE SET
name=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.name ELSE t.name END,
age=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.age ELSE t.age END,
country=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.country ELSE t.country END
WHEN NOT MATCHED THEN INSERT *
""")
削除後に順序どおりに到着しない更新の処理
残念ながら、上記のコードはまだ完全には正しくありません。マイクロバッチ全体でDELETE後に順序が乱れたUPDATE続くケースを処理していないためです。
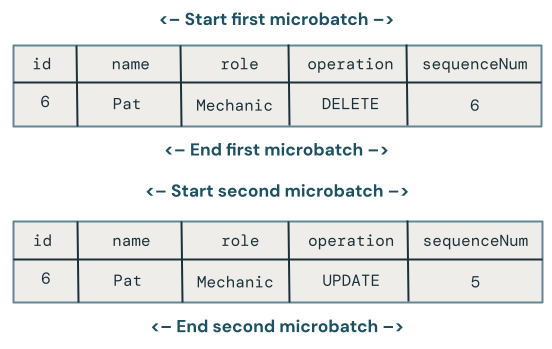
このケースを処理するアルゴリズムでは、後続の順序どおりでない更新を処理できるように、削除を記憶する必要があります。これを実行するには:
- 行をすぐに削除するのではなく、タイムスタンプまたは
sequenceNumを使用して行をソフト削除します。ソフト削除された行は トゥームストーンとして削除され ます。 - すべてのユーザーを、墓石を除外するビューにリダイレクトします。
- 時間の経過とともに墓石を削除するクリーンアップ ジョブを構築します。
次のコードを使用します。
def upsertToDelta(microBatchDF, batchId):
microBatchDF = microBatchDF.groupBy("id").agg(
max_by(struct("*"), "sequenceNum").alias("row")
).select("row.*").createOrReplaceTempView("updates")
spark.sql(f"""
MERGE INTO {catalog}.{schema}.{employees_table} t
USING updates s
ON s.id = t.id
WHEN MATCHED AND s.operation = 'DELETE' THEN UPDATE SET DELETED_AT=now()
WHEN MATCHED THEN UPDATE SET
name=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.name ELSE t.name END,
age=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.age ELSE t.age END,
country=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.country ELSE t.country END
WHEN NOT MATCHED THEN INSERT *
""")
ユーザーはターゲット テーブルを直接使用できないため、クエリを実行できるビューを作成します。
CREATE VIEW employees_v AS
SELECT * FROM employees_merge
WHERE DELETED_AT = NULL
最後に、廃棄された行を定期的に削除するクリーンアップ ジョブを作成します。
DELETE FROM employees_merge
WHERE DELETED_AT < now() - INTERVAL 1 DAY