Databricks Connect
この記事では、Databricks Runtime13.3LTS以降のDatabricks Connectについて説明します。
Databricks Connect Databricks Runtimeのクライアント ライブラリです。これを使用すると、Visual Studio Code、 PyCharm 、 IntelliJ IDEAなどのIDEs 、ノートブック、および任意のカスタム アプリケーションからDatabricksコンピュートに接続し、 Databricksレイクハウスに基づいた新しい対話型のユーザー エクスペリエンスを実現できます。
Databricks Connect は、次の言語で使用できます。
Databricks Connect で何ができますか?
Databricks Connectを使用すると、 を使用してコードを記述し、ローカルのSparkAPI DatabricksSparkセッションではなく コンピュートでリモートで実行できます。
-
あらゆる IDE から対話的に開発およびデバッグできます 。Databricks Connect使用すると、開発者は、IDE のネイティブ実行機能とデバッグ機能を使用して、 Databricksコンピュートでコードを開発およびデバッグできます。 Databricks Visual Studio Code 拡張機能は、 Databricks Connect を使用して、Databricks 上のユーザー コードの組み込みデバッグを提供します。
-
インタラクティブなデータ アプリを構築します 。JDBC ドライバーと同様に、 Databricks Connect ライブラリは任意のアプリケーションに埋め込んで Databricks と対話することができます。Databricks Connect 、 PySparkを通じてPythonの完全な表現力を提供し、 SQLプログラミング言語のインピーダンスの不一致を排除し、 DatabricksのスケーラブルなコンピュートでSparkを使用してすべてのデータ変換を実行できるようにします。
どのように機能しますか?
Databricks Connect はオープンソースのSpark Connect上に構築されており、Apache Spark 用の分離されたクライアント サーバー アーキテクチャを備えており、DataFrame API を使用して Spark クラスターへのリモート接続を可能にします。基礎となるプロトコルは、gRPC 上で Spark の未解決論理プランと Apache Arrow を使用します。クライアントAPI 、アプリケーション サーバー、 IDEs 、グラフィックス、プログラミング言語など、あらゆる場所に埋め込むことができるように、薄く設計されています。
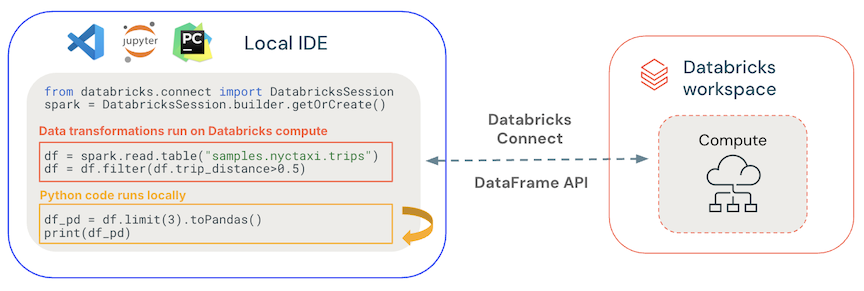
- 一般的なコードはローカルで実行されます 。Python および Scala コードはクライアント側で実行され、対話型のデバッグが可能になります。すべてのコードはローカルで実行されますが、すべての Spark コードはリモート クラスター上で引き続き実行されます。
- DataFrame APIs Databricksコンピュート上で実行されます 。 すべてのデータ変換はSparkプランに変換され、リモートSparkセッションを通じてDatabricksコンピュート上で実行されます。 これらは、
collect()、show()、toPandas()などのコマンドを使用すると、ローカル クライアント上で実現されます。 - DatabricksコンピュートでのUDFコード実行 : ローカルで定義された UDF はシリアル化され、実行先のクラスターに送信されます。 Databricksでユーザー コードを実行するAPIsには、 UDF 、
foreach、foreachBatch、およびtransformWithStateが含まれます。 - 依存関係の管理:
- ローカル マシンにアプリケーションの依存関係をインストールします 。これらはローカルで実行され、Python 仮想環境の一部など、プロジェクトの一部としてインストールする必要があります。
- Databricks に UDF 依存関係をインストールします 。「UDF 依存関係の管理」を参照してください。
Databricks Connect と Spark Connect はどのように関連していますか?
Spark Connect は、Apache Spark 内のオープンソースの gRPC ベースのプロトコルであり、DataFrame API を使用して Spark ワークロードをリモートで実行できます。
Databricks Runtime 13.3 LTS以降では、 Databricks Connect Spark Connect の拡張機能であり、 Databricksコンピュート モードおよびUnity Catalog操作をサポートするための追加および変更が加えられています。
その他のリソース
Databricks Connect ソリューションの開発をすぐに開始するには、次のチュートリアルを参照してください。
- Databricks Connect for Pythonクラシック コンピュートチュートリアル
- Databricks Connect for Pythonサーバレス コンピュート チュートリアル
- Databricks Connect for Scala classic Scalaチュートリアル
- Databricks Connect for Scalaサーバーレスコンピュートチュートリアル
- Databricks Connect for R チュートリアル
Databricks Connect を使用するサンプル アプリケーションを確認するには、次の例が含まれているGitHub サンプル リポジトリを参照してください。