Visual Studio Code の Databricks 拡張機能の Databricks Connect を使用してコードをデバッグする
この記事では、Visual Studio Code の Databricks 拡張機能で Databricks Connect 統合を使用して、個々の Python (.py) ファイルを実行およびデバッグする方法について説明します。 拡張機能に関する情報については、「 Visual Studio Code の Databricks 拡張機能とは」を参照してください。
Databricks Connect の統合により、ノートブックのセルを実行およびデバッグすることもできます。 「Visual Studio Code の Databricks 拡張機能を使用して Databricks Connect でノートブック セルを実行およびデバッグする」を参照してください。
必要条件
Visual Studio Code の Databricks 拡張機能内から Databricks Connect を使用するには、まず Databricks Connect の要件を満たす必要があります。 これらの要件には、Unity Catalog 対応ワークスペース、コンピュート要件、 Pythonのローカルインストールのバージョン要件などが含まれます。
Python 仮想環境をアクティブ化する
Python プロジェクトの Python 仮想環境 をアクティブ化します。 Python 仮想環境は、プロジェクトが互換性のあるバージョンの Python と Python パッケージ (この場合は Databricks Connect パッケージ) を使用していることを確認するのに役立ちます。
[Configuration ] ペインで、次の操作を行います。
- 「Python Environment 」の下にある赤い 「Activate Virtual Environment 」項目をクリックします。
- コマンド パレット で、[Venv] または [Conda] を選択します。
- インストールする依存関係を選択します (存在する場合)。
Databricks Connect のインストール
「Python環境 」の下の 「構成 」ビューで、次のようにします。
-
赤い [Databricks のインストール] 再生ボタンをクリックします。
-
クラスターをアタッチします。
- 拡張機能で クラスター セクションがまだ設定されていない場合は、「 Databricks Connectを使用するにはクラスターをアタッチしてください」というメッセージが表示されます。 [クラスターのアタッチ ] をクリックし、Databricks Connect要件を満たすクラスターを選択します。
- クラスター セクションが構成されているが、クラスターが Databricks Connectと互換性がない場合は、赤い Databricks Connect 無効 ボタンをクリックし、[ クラスターのアタッチ ] をクリックして、互換性のあるクラスターを選択します。
-
Databricks Connect パッケージ (およびその依存関係) がまだインストールされていない場合は、"対話型デバッグとオートコンプリートには Databricks Connect が必要です。
<environment-name>環境に設置してみませんか。 「インストール」 をクリックします。 -
Visual Studio Code のステータス バーで、赤い Databricks Connect の無効化 ボタンが表示されている場合は、それをクリックし、画面の指示を完了して有効にします。
-
[Databricks Connect が有効] ボタンが表示されたら、Databricks Connect を使用する準備が整いました。
Poetry を使用する場合は、次のコマンドを実行して、 pyproject.toml ファイルと poetry.lock ファイルをインストールされている Databricks Connect パッケージ (およびその依存関係) と同期できます。 必ず、プロジェクトの Visual Studio Code の Databricks 拡張機能によってインストールされたものと一致するバージョンの 16.4.1 Databricks Connect パッケージに置き換えてください。
poetry add databricks-connect==16.4.1
Python コードを実行またはデバッグする
Databricks Connect を有効にした後、Python ファイル (.pyを実行またはデバッグします。
-
プロジェクトで、実行またはデバッグする Python ファイルを開きます。
-
Python ファイル内のデバッグ ブレークポイントを設定します。
-
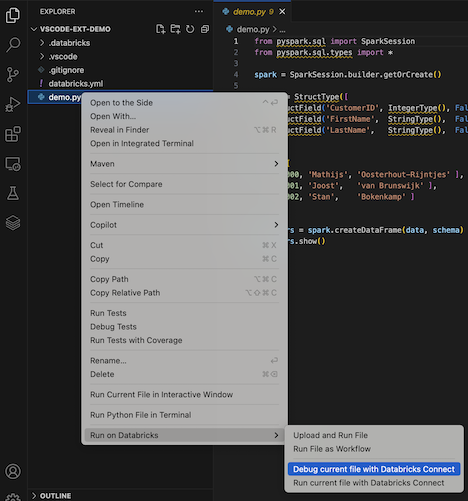
エディター タブの一覧の横にある [Databricks で実行 ] アイコンをクリックし、[ Databricks Connect を使用して現在のファイルをデバッグ ] をクリックします。
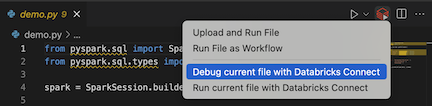
出力は「 デバッグコンソール 」ペインに表示されます。
.pyファイルを右クリックし、[ Databricks で実行 ] > [Databricks Connect を使用して現在のファイルをデバッグ ] をクリックすることもできます。