RAGアプリケーションの品質向上
この記事では、各コンポーネントを調整して、Retrieval Augmented Generation (RAG) アプリケーションの品質を向上させる方法の概要を説明します。
オフラインのデータパイプラインとオンラインRAGチェーンの両方のあらゆるポイントでチューニングするための無数の「ノブ」があります。 他にも数え切れないほどありますが、この記事では、RAGアプリケーションの品質に最も大きな影響を与える最も重要なノブに焦点を当てています。 Databricks では、これらのノブから始めることをお勧めします。
2種類の品質に関する考慮事項
概念的な観点からは、RAGの品質ノブを、次の2つの主要なタイプの品質問題のレンズを通して見ると便利です。
-
検索品質: 特定の取得クエリに最も関連性の高い情報を取得していますか?
LLMに提供されるコンテキストに重要な情報が欠落していたり、余分な情報が含まれていたりすると、高品質のRAG出力を生成することは困難です。
-
生成品質: 取得した情報と元のユーザー クエリを考えると、LLM は可能な限り最も正確で一貫性があり、役立つ応答を生成していますか?
ここでの問題は、幻覚、一貫性のない出力、またはユーザー クエリに直接対処できないという形で現れる可能性があります。
RAGアプリには、品質の課題に対処するために反復可能な2つのコンポーネント、つまりデータパイプラインとチェーンがあります。取得の問題(単にデータパイプラインを更新する)と生成の問題(RAGチェーンを更新する)を明確に分けていると思いがちです。しかし、現実はもっと微妙なものです。取得の品質は、データパイプライン(解析/チャンク戦略、メタデータ戦略、埋め込みモデルなど)とRAGチェーン(ユーザークエリの変換、取得されたチャンクの数、再ランク付けなど)の両方によって影響を受ける可能性があります。 同様に、生成品質は、取得が不十分な場合 (たとえば、モデル出力に影響を与える無関係な情報や欠落している情報) によって常に影響を受けます。
この重複は、RAGの品質改善に対する包括的なアプローチの必要性を強調しています。 データパイプラインとRAGチェーンの両方でどのコンポーネントを変更するか、また、これらの変更がソリューション全体にどのように影響するかを理解することで、ターゲットを絞った更新を行い、RAGの出力品質を向上させることができます。
データパイプラインの品質に関する考慮事項
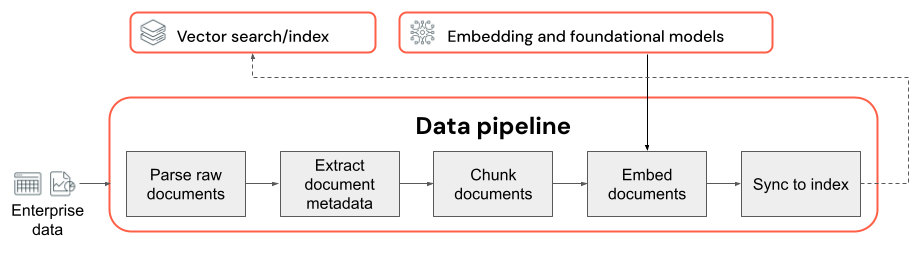
データパイプラインに関する主な考慮事項:
- 入力データコーパスの構成。
- 生データを抽出し、使用可能な形式に変換する方法 (PDF ドキュメントの解析など)。
- ドキュメントを小さなチャンクに分割する方法と、それらのチャンクの書式設定方法 (チャンク戦略やチャンク サイズなど)。
- 各ドキュメントやチャンクについて抽出されたメタデータ(セクションタイトルやドキュメントタイトルなど)。 このメタデータが各チャンクにどのように含まれるか (または含まれないか)。
- 類似性検索のためにテキストをベクトル表現に変換するために使用される埋め込みモデル。
RAGチェーン
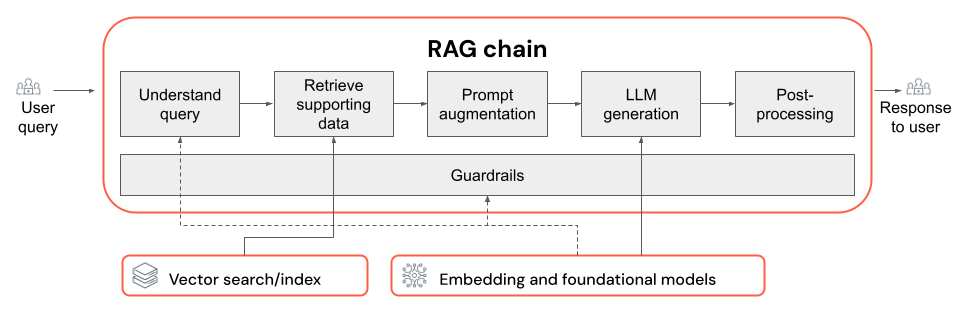
- LLM とそのパラメーター (温度トークンや最大トークンなど) の選択。
- retrieval パラメーター (取得されたチャンクやドキュメントの数など)。
- 取得アプローチ (たとえば、キーワード検索、ハイブリッド検索、セマンティック検索、ユーザーのクエリの書き換え、ユーザーのクエリのフィルターへの変換、再ランク付けなど)。
- 取得したコンテキストでプロンプトを書式設定して、LLM を高品質の出力に導く方法。