Lakeflow Jobsで初めてのワークフローを作成する
Lakeflow ジョブを使用して、サンプル データセットの読み取りと処理を行うタスクを調整します。このクイックスタートでは、次のことを行います。
- 新しいノートブックを作成し、年ごとの人気の赤ちゃんの名前を含むサンプルデータセットを取得するコードを追加する。
- サンプル データセットを Unity Catalog に保存します。
- 新しいノートブックを作成し、Unity Catalog からデータセットを読み取り、年でフィルター処理して結果を表示するコードを追加します。
- 新しいジョブを作成し、ノートブックを使って2つのタスクを設定する。
- ジョブを実行し、結果を表示する。
必要条件
ワークスペースが Unity Catalog に対応しており、 サーバレス ジョブ が有効になっている場合、デフォルトによって、サーバレス コンピュートでジョブが実行されます。 サーバレス コンピュートでジョブを実行するために、クラスター作成権限は必要ありません。
それ以外の場合は、ジョブ コンピュートを作成するための クラスター作成アクセス許可 、または汎用コンピュート リソースに対する アクセス許可 が必要です。
に Unity Catalogボリューム が必要です。この記事では、カタログ内の default という名前のスキーマで my-volume という名前のボリュームの例を使用します main。Unity Catalog には、次のアクセス許可が必要です。
READ VOLUMEmy-volumeボリュームの場合はWRITE VOLUMEUSE SCHEMAdefaultスキーマのUSE CATALOGmainカタログ
これらの権限を設定するには、 Databricks管理者またはUnity Catalog権限リファレンスを参照してください。
ノートブックを作成する
次の手順は、このワークフローで実行するノートブックを2つ作成します。
データの取得と保存
サンプル データセットを取得して Unity Catalog に保存するノートブックを作成するには、次のようにします。
-
サイドバー
 「 新規」 をクリックしてから、「 ノートブック 」をクリックします。Databricks は、新しい空白のノートブックを作成して、デフォルト フォルダーに開きます。 デフォルト言語は、最後に使用した言語であり、ノートブックは、最後に使用したコンピュートリソースに自動的に添付されます。
「 新規」 をクリックしてから、「 ノートブック 」をクリックします。Databricks は、新しい空白のノートブックを作成して、デフォルト フォルダーに開きます。 デフォルト言語は、最後に使用した言語であり、ノートブックは、最後に使用したコンピュートリソースに自動的に添付されます。 -
(オプション)ノートブックの名前を「 名前データの取得」に変更 します。
-
必要に応じて、 デフォルトの言語を Python に変更します。
-
次のPythonコードをコピーして、ノートブックの最初のセルに貼り付けます。
Pythonimport requests
response = requests.get('https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv')
csvfile = response.content.decode('utf-8')
dbutils.fs.put("/Volumes/main/default/my-volume/babynames.csv", csvfile, True)
フィルタリングされたデータの読み取りと表示
データをフィルター処理して表示するノートブックを作成するには:
-
サイドバー
「 新規」 をクリックしてから、「 ノートブック 」をクリックします。 -
(オプション)ノートブックの名前を フィルター名データ に変更します。
-
以下のPythonコードは、前のステップで保存したデータを読み取り、一時ビューを作成します。また、ビュー内のデータをフィルタリングするために使用できるウィジェットも作成します。
Pythonbabynames = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/Volumes/main/default/my-volume/babynames.csv")
babynames.createOrReplaceTempView("babynames_table")
years = spark.sql("select distinct(Year) from babynames_table").toPandas()['Year'].tolist()
years.sort()
dbutils.widgets.dropdown("year", "2014", [str(x) for x in years])
display(babynames.filter(babynames.Year == dbutils.widgets.get("year")))
ジョブを作成する
作成するジョブは、2 つのタスクで構成されます。
最初のタスクを作成するには:
- ワークスペースで、サイドバーの
 Jobs & パイプライン をクリックします。
Jobs & パイプライン をクリックします。 - 「作成 」をクリックし、「 ジョブ」 をクリックします。
- 最初のタスクを構成するには、 ノートブック タイルをクリックします。 ノートブック タイルが利用できない場合は、 [別のタスク タイプを追加] をクリックし、 ノートブック を検索します。
- (オプション)ジョブの名前 (デフォルトは
New Job <date-time>) をジョブ名に置き換えます。 - タスク名 フィールドにタスクの名前を入力します。(例: retrieve-baby-names (赤ちゃんの名前を取得))
- 必要に応じて、[ タイプ ] ドロップダウン メニューから [ノートブック ] を選択します。
- [ ソース ] ドロップダウン メニューで [ ワークスペース] を選択すると、以前に保存したノートブックを使用できます。
- [パス] で、ファイル ブラウザーを使用して最初に作成したノートブックを検索し、ノートブック名をクリックして [確認] をクリックします。
- タスクの保存 をクリックします。画面の右上隅に通知が表示されます。
2 番目のタスクを作成するには:
 タスクの追加 > ノートブック をクリックします。
タスクの追加 > ノートブック をクリックします。- タスク名 フィールドにタスクの名前を入力します。(例: filter-baby-names (赤ちゃんの名前をフィルタリング))
- [パス] で、ファイル ブラウザーを使用して作成した 2 番目のノートブックを見つけ、ノートブック名をクリックして [確認] をクリックします。
- パラメーター の下の 追加 をクリックします。 キー フィールドに
yearを入力します。 値 フィールドに2014を入力します。 - タスクの保存 をクリックします。
ジョブを実行する
ジョブをすぐに実行するには、右上隅の ![]() をクリックします。
をクリックします。
実行の詳細を表示する
-
実行 タブをクリックし 、[ 開始時刻] 列 のリンクをクリックして、表示する実行を開きます。
-
クリッククリックして、いずれかのタスクをクリックして、出力と詳細を表示します。たとえば、 filter-baby-names タスクをクリックして、フィルター タスクの出力と実行の詳細を表示します。
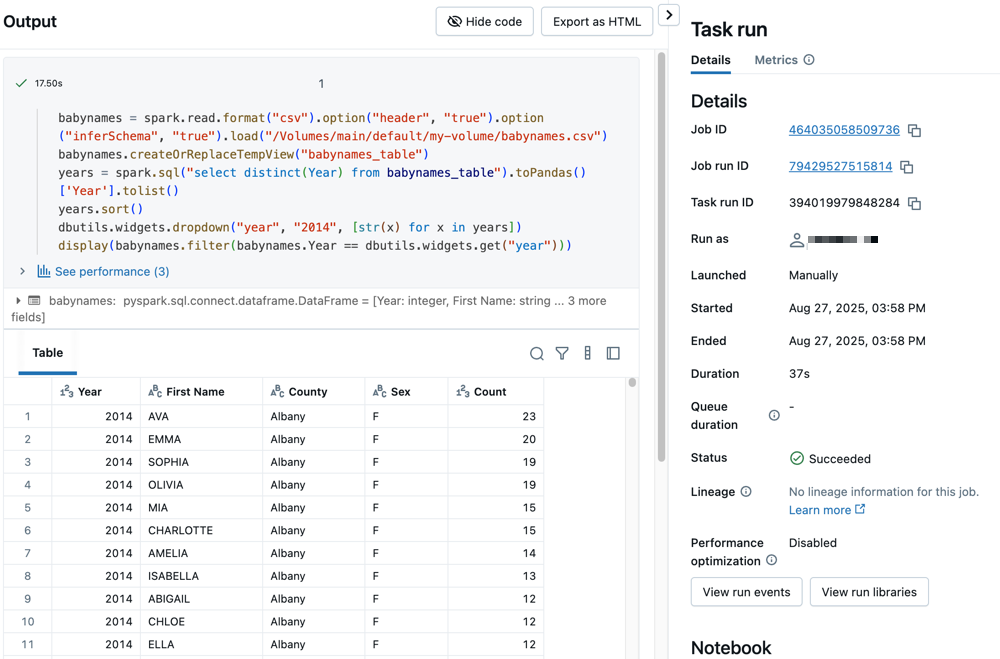
異なるパラメーターでの実行
ジョブを再実行し、別の年の赤ちゃんの名前をフィルタリングするには、次の手順を実行します:
 [今すぐ実行] の横にある をクリックし、[ 別の設定で今すぐ実行] を選択します。
[今すぐ実行] の横にある をクリックし、[ 別の設定で今すぐ実行] を選択します。- 値 フィールドに
2015を入力します。 - 実行 をクリックします。
その他のリソース
- スケジュール、通知、パラメーターなどのジョブ設定を構成します。「LakeFlowジョブの構成と編集」を参照してください。
- 利用可能なタスクの種類を調べます。タスクの種類を参照してください。
- スケジュールに基づいて、または新しいデータが到着したときにジョブを自動的に実行します。スケジュールとトリガーを使用してジョブを自動化するを参照してください。
- ジョブの実行を監視し、アラートを設定します。Lakeflowジョブのモニタリングを参照してください。