Unity Catalog マネージドテーブル向け予測的最適化
予測的最適化は、Databricks上のUnity Catalog マネージドテーブル (Delta Lake および Iceberg) で OPTIMIZE、VACUUM、および ANALYZE を自動的に実行します。これにより、手動によるメンテナンスやパフォーマンスの問題追跡に費やす時間をなくします。
予測的最適化は、2024年11月11日以降に作成されたアカウントでデフォルトで有効になります。Databricksは既存のアカウントに段階的に展開しています。このロールアウトは2026年8月までに完了予定です。アカウントがすでに有効になっているかを確認するには、予測的最適化が有効になっているかどうかを確認するを参照してください。
予測的最適化を有効にすると、 Databricks は自動的に次の処理を行います。
- メンテナンス操作の恩恵を受けるテーブルを識別し、それらの操作を実行するキューに追加します。
- データがマネージドテーブルに書き込まれるときに統計を収集します。
これにより、不要なメンテナンスの実行がなくなり、パフォーマンスを手動で追跡およびトラブルシューティングする負担も軽減されます。
Databricks 、すべてのUnity Catalogマネージド テーブルに対して予測的最適化を推奨します。 たとえば、自動リキッドクラスタリングでは、データ使用パターンに基づいてデータ レイアウトをインテリジェントに最適化します。 「テーブルにリキッドクラスタリングを使用する」を参照してください。
予測的最適化 はどのような操作を実行しますか?
予測的最適化Unity Catalogマネージドテーブルに対して次の操作を実行します。
オペレーション | 説明 |
|---|---|
| 有効なテーブルのインクリメンタル・クラスタリングをトリガーします。 テーブルにリキッドクラスタリングを使用するを参照してください。 ファイルサイズを最適化することで、クエリのパフォーマンスを向上させます。 データファイルレイアウトの最適化を参照してください。 |
| テーブルで参照されなくなったデータファイルを削除することにより、ストレージコストを削減します。 「 vacuumを使用した未使用のデータファイルの削除」を参照してください。 |
| テーブルをスキャンし、統計を収集してクエリパフォーマンスを向上させます。ANALYZE TABLE … COMPUTE STATISTICSを参照してください。予測的最適化によって収集された統計を削除するには、ANALYZE TABLE … DROP STATISTICSを参照してください。 |
OPTIMIZE 予測的最適化によって実行される場合、 ZORDERは実行されません。 Z-Orderを使用するテーブルでは、予測的最適化はZ-orderedファイルを無視します。
自動リキッドクラスタリングが有効になっている場合、予測的最適化では、データのクラスタリングの前に新しいクラスタリングキーが選択されることがあります。 自動リキッドクラスタリングを参照してください。
VACUUM保持期間はdelta.deletedFileRetentionDurationテーブル プロパティによって決定され、デフォルトでは 7 日間に設定されます。VACUUM 、そのウィンドウ内の Delta テーブル バージョンによって参照されなくなったデータ ファイルを削除します。データを長期間保持するには (たとえば、拡張タイムトラベルをサポートするため)、予測的最適化を有効にする前にこのプロパティを設定します。
ALTER TABLE table_name SET TBLPROPERTIES ('delta.deletedFileRetentionDuration' = '30 days');
コンピュートと課金
予測的最適化 ジョブのサーバレス コンピュートを使用した実行ANALYZE 、 OPTIMIZE 、およびVACUUMオペレーション。 あなたのアカウントには、サーバレス ジョブSKUを使用してこのコンピュートに対して請求されます。
Databricksマネージドサービスの価格をご覧ください。 「システム テーブルによる予測的最適化の追跡」を参照してください。
前提条件
予測的最適化を使用するには、次の要件を満たす必要があります。
- Databricks ワークスペースは、 サポートされているリージョン のPremium プラン以上 である必要があります。
- SQLウェアハウスまたはDatabricks Runtime 12.2 LTS以降を使用する必要があります。
- マネージドテーブル Unity Catalog のみがサポートされています。
予測的最適化の有効化
予測的最適化は、アカウント、カタログ、スキーマ、またはテーブルに対して有効にできます。すべてのUnity Catalogマネージドテーブルは、デフォルトでアカウントの値を継承します。アカウントのデフォルトは、カタログ、スキーマ、またはテーブルのレベルで上書きできます。
予測的最適化を有効または無効にするには、次の権限が必要です。
Unity Catalog オブジェクト | 権限 |
|---|---|
アカウント | アカウント管理者 |
カタログ | カタログの所有者、またはカタログに対する |
スキーマ | スキーマ所有者、またはスキーマに対して |
テーブル | テーブルの所有者、またはテーブルに対する |
アカウントで予測的最適化を有効化、無効化する
アカウント管理者は、アカウント内のすべてのメタストアに対して予測的最適化を有効にすることができます。 カタログとスキーマはデフォルトでこの設定を継承しますが、どちらのレベルでも上書きできます。
- アカウント コンソールに移動します。
- 設定 、 機能の有効化 の順に移動します。
- [予測的最適化] の横にある必要なオプション (たとえば、 [有効] ) を選択します。
- 予測的最適化をサポートしていないリージョンのメタストアは有効になっていません。
- アカウントレベルで予測的最適化を無効にしても、特に有効にしたカタログまたはスキーマでは無効になりません。
カタログ、スキーマ、またはテーブルの予測的最適化を有効または無効にする
予測的最適化では、継承モデルを使用します。カタログで有効にすると、そのカタログ内のスキーマが設定を継承し、有効なスキーマ内のテーブルも同様に継承します。この動作を上書きするために、カタログ、スキーマ、またはテーブルで予測的最適化を明示的に有効または無効にすることができます。
アカウントレベルで有効にする前に、カタログ、スキーマ、またはテーブルレベルで予測的最適化を無効にできます。後からアカウントレベルで予測的最適化が有効にされたとしても、それを無効にしていたオブジェクトに対してはブロックされたままになります。
親オブジェクトからの継承を有効、無効、またはリセット予測的最適化を行うには、次の構文を使用します。
ALTER CATALOG [catalog_name] { ENABLE | DISABLE | INHERIT } PREDICTIVE OPTIMIZATION;
ALTER { SCHEMA | DATABASE } schema_name { ENABLE | DISABLE | INHERIT } PREDICTIVE OPTIMIZATION;
ALTER TABLE table_name { ENABLE | DISABLE | INHERIT } PREDICTIVE OPTIMIZATION;
See ALTER TABLE.
予測的最適化が有効かどうかを確認する
Predictive Optimizationフィールドは、予測的最適化が有効かどうかを示すUnity Catalogプロパティです。 設定が親オブジェクトから継承されている場合、フィールド値はこれを示します。
ステータスを確認するには、次の構文を使用します。
DESCRIBE (CATALOG | SCHEMA | TABLE) EXTENDED name
予測的最適化がテーブルをスキップした理由を確認する
Databricks Runtime 18以降では、予測的最適化がマネージドテーブルを評価した後、Catalog Explorerの 履歴 タブを使用して、操作がスキップされた理由を確認できます。結果が表示されるまで最大24時間かかる場合があります。
カタログエクスプローラーの履歴タブを使用します。
Catalog Explorer のテーブルの [ 履歴 ] タブでスキップの理由を表示できます。[ 操作 ] 列では、 Auto ラベルは操作が実行されたことを示し、 Not applied ラベルは操作がスキップされたことを示します。 Auto ラベルには、予測的最適化や、ストリーミングの自動圧縮などのその他の自動操作が含まれます。
スキップ理由を表示するには、 操作 列の 未適用 ラベルが付いた行をクリックします。
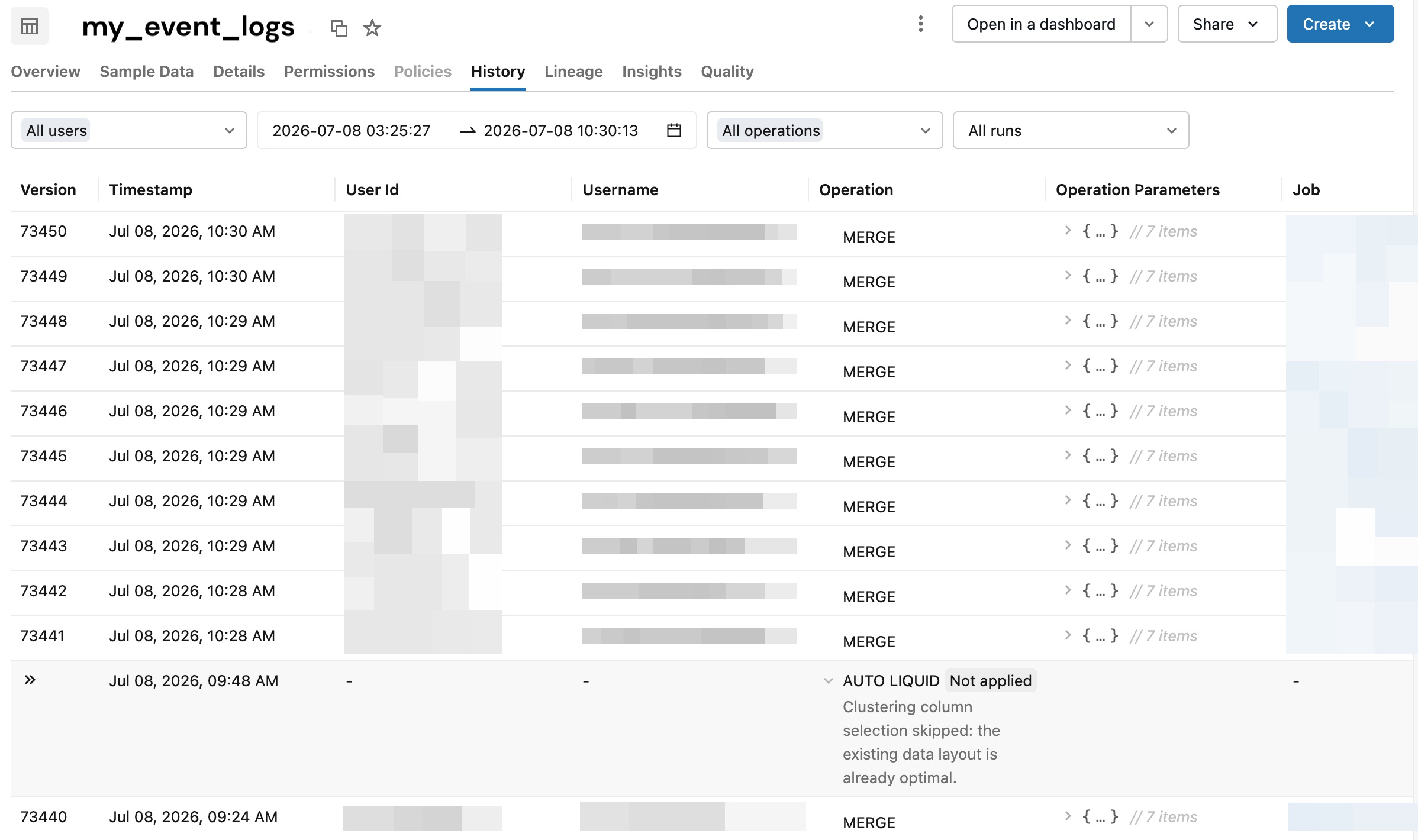
次の表は、カタログエクスプローラーに表示される自動操作タイプについて説明しています:
カタログエクスプローラー操作 | 説明 |
|---|---|
| クエリのパフォーマンスを向上させるためのファイルの圧縮、または増分リキッドクラスタリング |
| リキッドクラスタリングキーの評価または進化 |
| テーブルによって参照されなくなったデータファイルの削除 |
システムテーブルによる予測的最適化の追跡
Databricks は、予測的最適化操作、コスト、および影響に対する可観測性のためのシステムテーブル system.storage.predictive_optimization_operations_historyを提供します。 予測的最適化 システムテーブル リファレンスを参照してください。
制限
予測的最適化は、次のテーブル タイプでは実行されません。
- OpenSharingの受信者としてワークスペースに読み込まれたテーブル
- 外部テーブル