ノートブックとSQLエディターの視覚化タイプ
このページでは、Databricks ノートブックおよび SQL エディターで使用できる視覚化の種類の概要を示し、各視覚化の種類の例を作成する方法を示します。
このページでは 、Databricks ノートブックと SQL エディター の視覚化について説明します。AI/BIダッシュボードの視覚化については、 AI/BI dashboard視覚化タイプ」を参照してください。
エリアチャート
面グラフは、折れ線グラフと棒グラフを組み合わせて、1 つ以上のグループの数値が 2 番目の変数 (通常は時間の進行) でどのように変化するかを示します。これらは、時間の経過に伴うセールスファネルの変化を示すためによく使用されます。
面グラフはバックエンド集計をサポートしており、結果セットを切り捨てることなく 64K 行を超えるデータを返すクエリをサポートします。
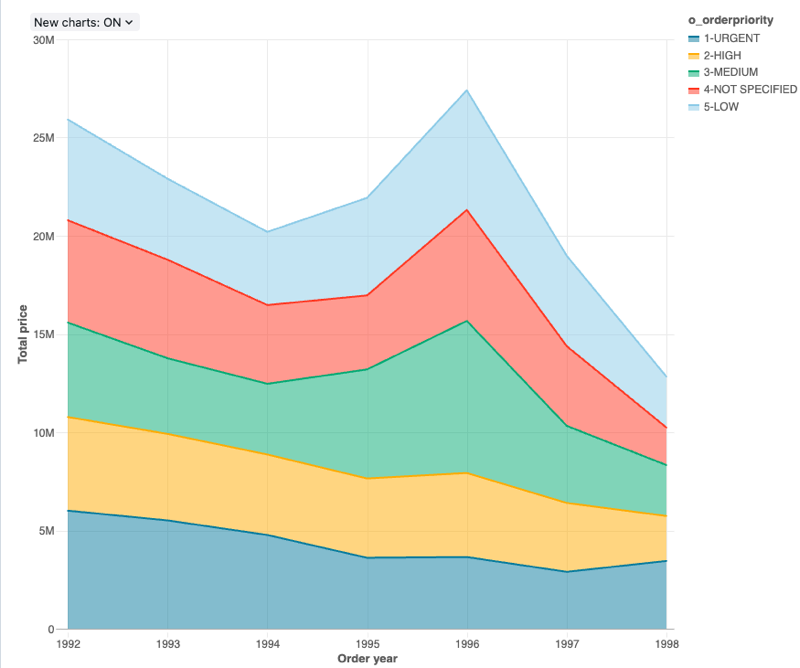
構成値 : この面グラフの視覚化では、次の値が設定されました。
-
X 列:
- データセット列:
o_orderdate - 日付レベル:
Years
- データセット列:
-
Y 列:
- データセット列:
o_totalprice - 集計の種類:
Sum
- データセット列:
-
グループ化 (データセット列):
o_orderpriority -
スタッキング:
Stack -
X 軸名 (デフォルト値を上書き):
Order year -
Y 軸の名前 (デフォルト値を上書き):
Total price
構成オプション : 面グラフの構成オプションについては、 グラフの構成オプションを参照してください。
SQL クエリ : この面グラフの視覚化では、次の SQL クエリを使用してデータ セットが生成されました。
select * from samples.tpch.orders
棒グラフ
棒グラフは、時間の経過に伴うメトリクスの変化を表し、 円 グラフと同様に比例性を示します。
棒グラフはバックエンド集計をサポートしており、結果セットを切り捨てることなく 64K 行を超えるデータを返すクエリをサポートします。
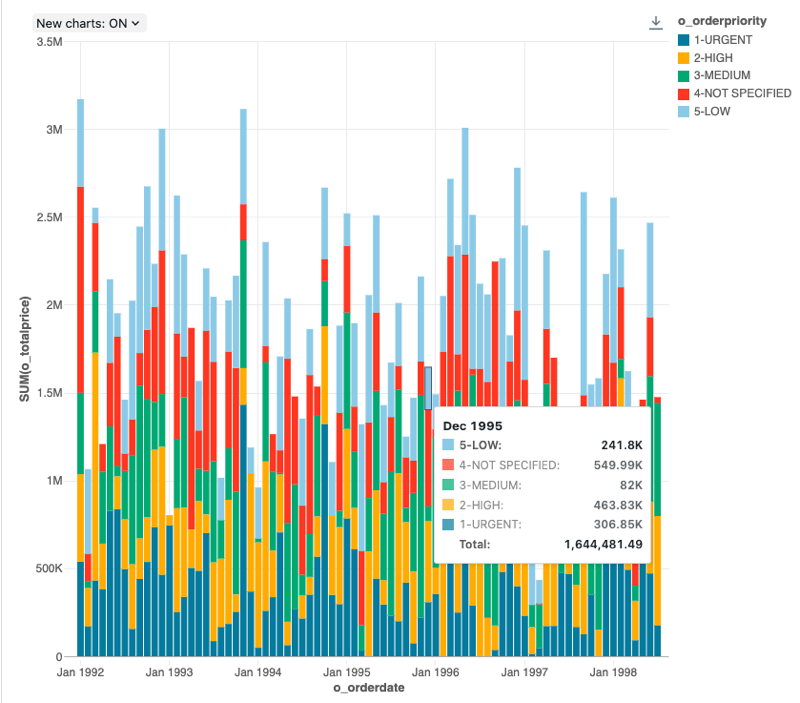
構成値 : この棒グラフの視覚化では、次の値が設定されました。
-
X 列:
- データセット列:
o_orderdate - 日付レベル:
Months
- データセット列:
-
Y 列:
- データセット列:
o_totalprice - 集計の種類:
Sum
- データセット列:
-
グループ化 (データセット列):
o_orderpriority -
スタッキング:
Stack -
X 軸名 (デフォルト値を上書き):
Order month -
Y 軸の名前 (デフォルト値を上書き):
Total price
構成オプション : 棒グラフの構成オプションについては、 グラフの構成オプションを参照してください。
SQL クエリ : この棒グラフの視覚化では、次の SQL クエリを使用してデータ セットが生成されました。
select * from samples.tpch.orders
バブルチャート
バブルチャートは、各ポイントマーカーのサイズが関連するメトリクスを反映している散布図です。
バブル チャートはバックエンド集計をサポートしており、結果セットを切り捨てることなく 64K 行を超えるデータを返すクエリをサポートします。
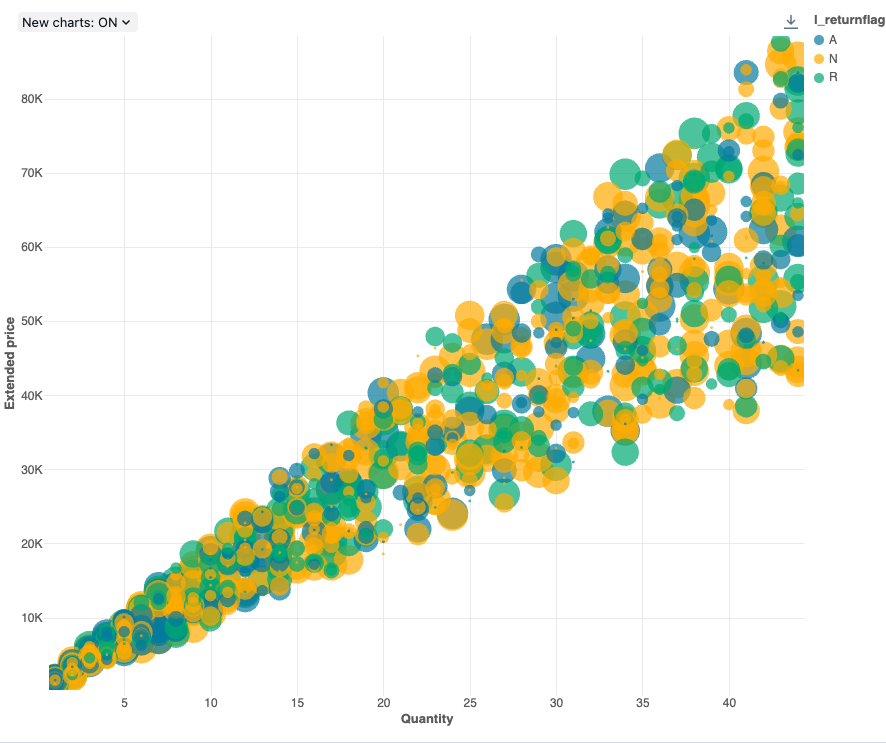
構成値 : このバブル チャートの視覚化では、次の値が設定されました。
- X (データセット列):
l_quantity - Y 列 (データセット列):
l_extendedprice - グループ化 (データセット列):
l_returnflag - バブルサイズ列(データセット列):
l_tax - バブルサイズ係数:20
- バブル サイズに比例します。
Area - X 軸名 (デフォルト値を上書き):
Quantity - Y 軸の名前 (デフォルト値を上書き):
Extended price
構成オプション : バブル・チャートの構成オプションについては、 チャートの構成オプションを参照してください。
SQL クエリ : このバブル チャートの視覚化では、次の SQL クエリを使用してデータ セットが生成されました。
select * from samples.tpch.lineitem where l_quantity < 45
ボックスチャート
ボックス チャートの視覚化には、数値データの分布の概要が表示され、必要に応じてカテゴリ別にグループ化されます。 ボックス チャートの視覚化を使用すると、カテゴリ間の値の範囲をすばやく比較し、値の局所性、広がり、歪度グループを四分位数で視覚化できます。 各ボックスの暗い線は四分位範囲を示しています。 ボックス プロットの視覚化の解釈の詳細については、Wikipedia の 「ボックス チャート」の記事 を参照してください。
ボックス チャートは、最大 64,000 行の集計のみをサポートします。 データセットが 64,000 行を超える場合、データは切り捨てられます。
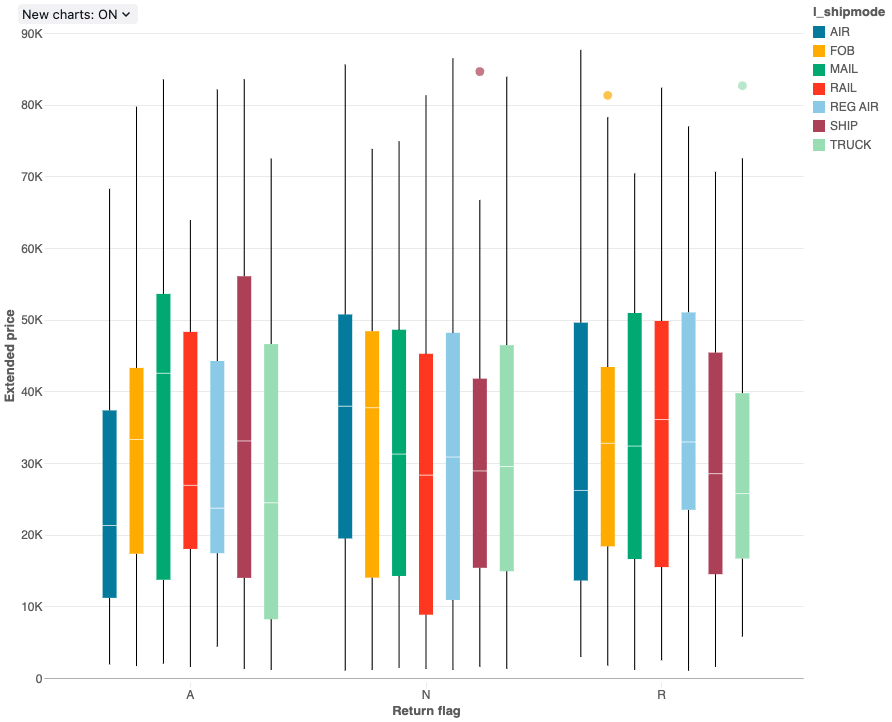
構成値 : このボックス チャートの視覚化では、次の値が設定されました。
- X 列 (データセット列):
l_returnflag - Y 列 (データセット列):
l_extendedprice - グループ化 (データセット列):
l_shipmode - X 軸名 (デフォルト値を上書き):
Return flag - Y 軸の名前 (デフォルト値を上書き):
Extended price
設定オプション :ボックスチャートの設定オプションについては、ボックスチャートの設定オプションを参照してください。
SQL クエリ : このボックス チャートの視覚化では、次の SQL クエリを使用してデータ セットが生成されました。
select * from samples.tpch.lineitem
コホート分析
コホート分析では、あらかじめ決められたグループ (コホート) が一連のステージを進行するにつれて、その結果が調べられます。 コホートの視覚化は、日付のみに集計されます (月単位の集計が可能です)。 結果セット内の他のデータの集計は行いません。 他のすべての集計は、クエリ自体内で行われます。
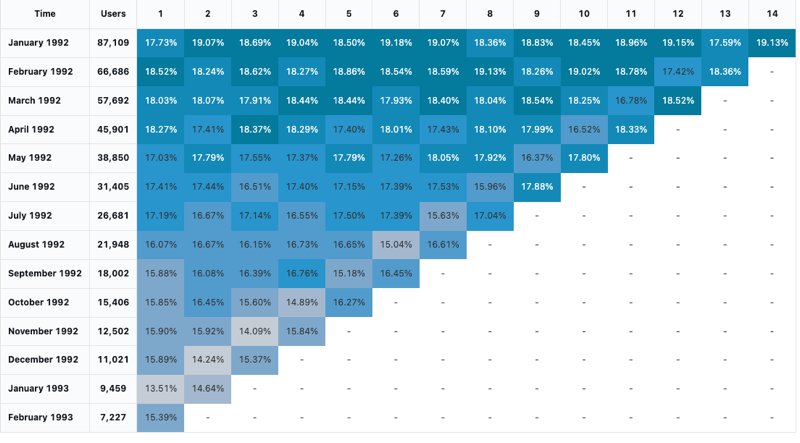
設定値 : このコホートの視覚化では、次の値が設定されました。
- 日付 (バケット) (データベース列):
cohort_month - ステージ (データベース列):
months - バケットのポピュレーション サイズ (データベース列):
size - ステージ値 (データベース列):
active - 時間間隔:
monthly
設定オプション :コホート設定オプションについては、コホートチャート設定オプションを参照してください。
SQL クエリ : このコホートの視覚化では、次の SQL クエリを使用してデータ セットが生成されました。
-- match each customer with its cohort by month
with cohort_dates as (
SELECT o_custkey, min(date_trunc('month', o_orderdate)) as cohort_month
FROM samples.tpch.orders
GROUP BY 1
),
-- find the size of each cohort
cohort_size as (
SELECT cohort_month, count(distinct o_custkey) as size
FROM cohort_dates
GROUP BY 1
)
-- for each cohort and month thereafter, find the number of active customers
SELECT
cohort_dates.cohort_month,
ceil(months_between(date_trunc('month', samples.tpch.orders.o_orderdate), cohort_dates.cohort_month)) as months,
count(distinct samples.tpch.orders.o_custkey) as active,
first(size) as size
FROM samples.tpch.orders
left join cohort_dates on samples.tpch.orders.o_custkey = cohort_dates.o_custkey
left join cohort_size on cohort_dates.cohort_month = cohort_size.cohort_month
WHERE datediff(date_trunc('month', samples.tpch.orders.o_orderdate), cohort_dates.cohort_month) != 0
GROUP BY 1, 2
ORDER BY 1, 2
コンボグラフ
コンボ チャートは、 折れ線 グラフと 横棒 グラフを組み合わせて、時間の経過に伴う変化を比例して表示します。
コンボグラフはバックエンド集計をサポートしており、結果セットを切り捨てることなく 64K 行を超えるデータを返すクエリをサポートします。
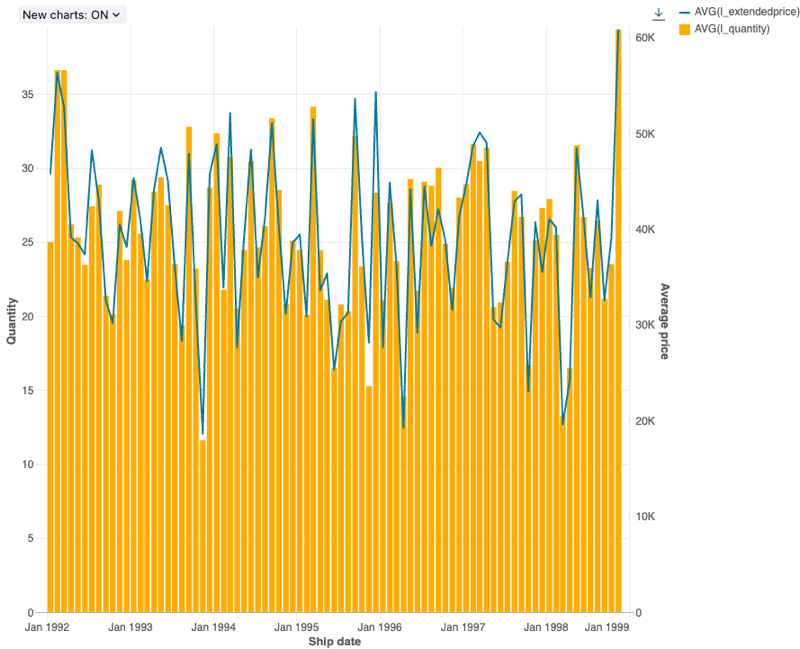
構成値 : このコンボ グラフの視覚化では、次の値が設定されました。
-
X 列:
- データセット列:
l_shipdate - 日付レベル:
Months
- データセット列:
-
Y 列:
- 最初のデータセット列:
l_extendedprice - 集計の種類: 平均
- 2 番目のデータセット列:
l_quantity - 集計の種類: 平均
- 最初のデータセット列:
-
X 軸名 (デフォルト値を上書き):
Ship date -
左Y軸の名前(デフォルト値を上書き):
Quantity -
右 Y 軸の名前 (デフォルト値を上書き):
Average price -
シリーズ:
- Order1 (データセット列):
AVG(l_extendedprice) - Y軸:右
- タイプ: Line
- Order2 (データセット列):
AVG(l_quantity) - Y軸:左
- タイプ: バー
- Order1 (データセット列):
構成オプション : コンボ・グラフ構成オプションについては、 グラフ構成オプションを参照してください。
SQL クエリ : このコンボ チャートの視覚化では、次の SQL クエリを使用してデータ セットが生成されました。
select * from samples.tpch.lineitem
カウンター表示
カウンターは 1 つの値を目立つように表示し、それらをターゲット値と比較するオプションもあります。 カウンターを使用するには、 Value Column と TargetColumn のカウンター ビジュアリゼーションに表示するデータ行を指定します。
カウンターは、最大 64,000 行の集計のみをサポートします。 データセットが 64,000 行を超える場合、データは切り捨てられます。

構成値 : このカウンターの視覚化では、次の値が設定されました。
-
値列
- データセット列:
avg(o_totalprice) - 行数: 1
- データセット列:
-
ターゲット列:
- データセット列:
avg(o_totalprice) - 行数: 2
- データセット列:
-
フォーマットターゲット値: 有効
SQL クエリ : このカウンターの視覚化では、次の SQL クエリを使用してデータ セットが生成されました。
select o_orderdate, avg(o_totalprice)
from samples.tpch.orders
GROUP BY 1
ORDER BY 1 DESC
ファネルの視覚化
ファネルの可視化は、さまざまな段階でのメトリクスの変化を分析するのに役立ちます。 ファネルを使用するには、 step 列と value 列を指定します。
ファネルは、最大 64,000 行の集計のみをサポートします。 データセットが 64,000 行を超える場合、データは切り捨てられます。
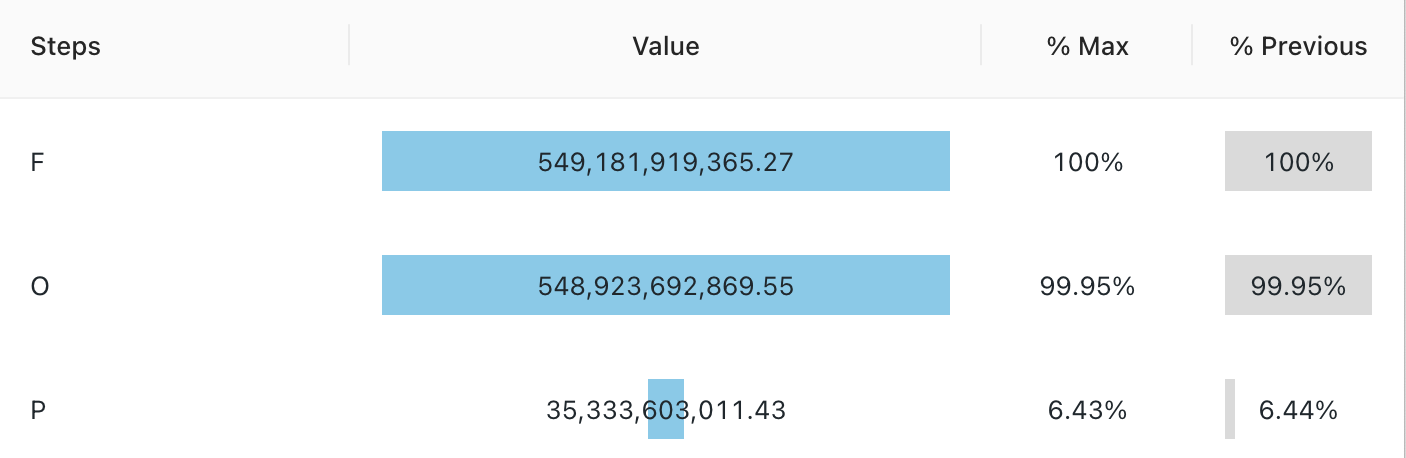
設定値 : このファネルのビジュアライゼーションでは、次の値が設定されました。
- ステップ列 (データセット列):
o_orderstatus - 値列 (データセット列):
Revenue
SQL クエリ : このファネルの視覚化では、次の SQL クエリを使用してデータ セットが生成されました。
SELECT o_orderstatus, sum(o_totalprice) as Revenue
FROM samples.tpch.orders
GROUP BY 1
ヒートマップチャート
ヒートマップ チャートは、棒グラフ、積み上げ、バブル チャートの機能をブレンドし、色を使用して数値データを視覚化できます。 ヒートマップの一般的なカラー パレットでは、オレンジや赤などの暖色系の色を使用して最大値が表示され、青や紫などの寒色系の色を使用して最小値が表示されます。
たとえば、次のヒートマップについて考えてみます。このヒートマップは、各日に最も頻繁に発生するタクシー乗車距離を視覚化し、その結果を曜日、距離、および合計料金でグループ化します。
ヒートマップチャートはバックエンド集計をサポートしており、結果セットを切り捨てることなく64K行を超えるデータを返すクエリをサポートします。
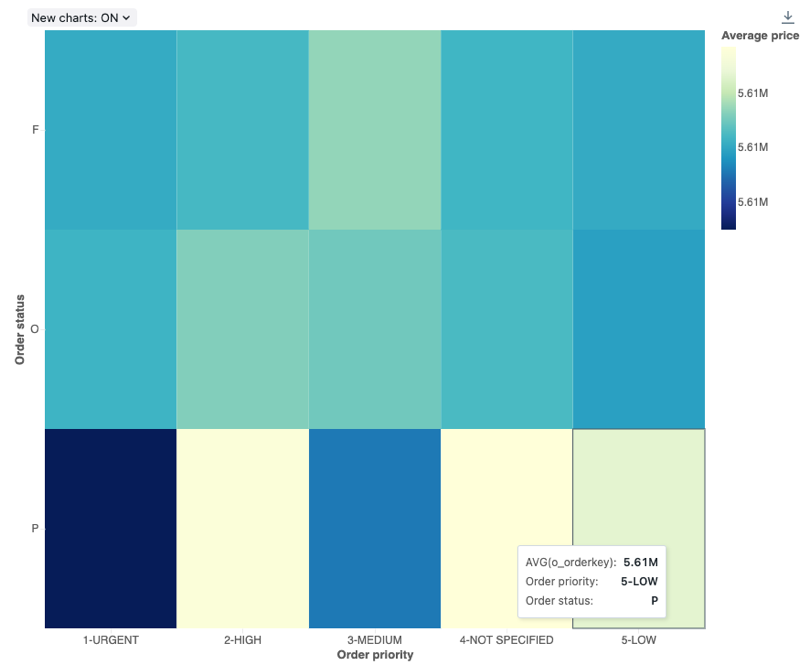
構成値 : このヒートマップ グラフの視覚化では、次の値が設定されました。
-
X 列 (データセット列):
o_orderpriority -
Y 列 (データセット列):
o_orderstatus -
カラーカラム:
- データセット列:
o_totalprice - 集計の種類:
Average
- データセット列:
-
X 軸名 (デフォルト値を上書き):
Order priority -
Y 軸名(デフォルト値を上書き):
Order status -
色の名前 (デフォルト値を上書き):
Average price -
配色 (デフォルト値を上書き):
YIGnBu
設定オプション : ヒートマップ設定オプションについては、 ヒートマップチャート設定オプションを参照してください。
SQL クエリ : このヒートマップ チャートの視覚化では、次の SQL クエリを使用してデータ セットが生成されました。
select * from samples.tpch.orders
ヒストグラム チャート
ヒストグラムは、データセットで特定の値が発生する頻度をプロットします。 ヒストグラムは、データセットの値が少数の範囲に集まっているのか、それともより広がっているのかを理解するのに役立ちます。 ヒストグラムは、個別のバー (ビンとも呼ばれます) の数を制御する棒グラフとして表示されます。
ヒストグラム グラフはバックエンド集計をサポートしており、結果セットを切り捨てることなく 64K 行を超えるデータを返すクエリをサポートします。
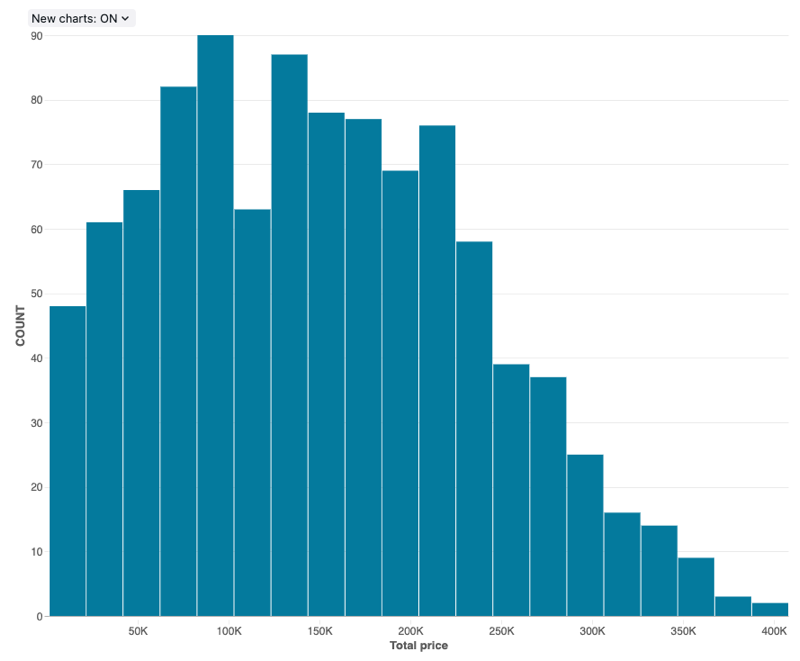
構成値 : このヒストグラム グラフの視覚化では、次の値が設定されました。
- X 列 (データセット列):
o_totalprice - ビンの数:20
- X 軸名 (デフォルト値を上書き):
Total price
構成オプション : ヒストグラム・チャートの構成オプションについては、 ヒストグラム・チャートの構成オプションを参照してください。
SQL クエリ : このヒストグラム グラフの視覚化では、次の SQL クエリを使用してデータ セットが生成されました。
select * from samples.tpch.orders
折れ線グラフ
折れ線グラフは、時間の経過に伴う 1 つ以上のメトリクスの変化を示します。
折れ線グラフはバックエンド集計をサポートしており、結果セットを切り捨てることなく 64K 行を超えるデータを返すクエリをサポートします。
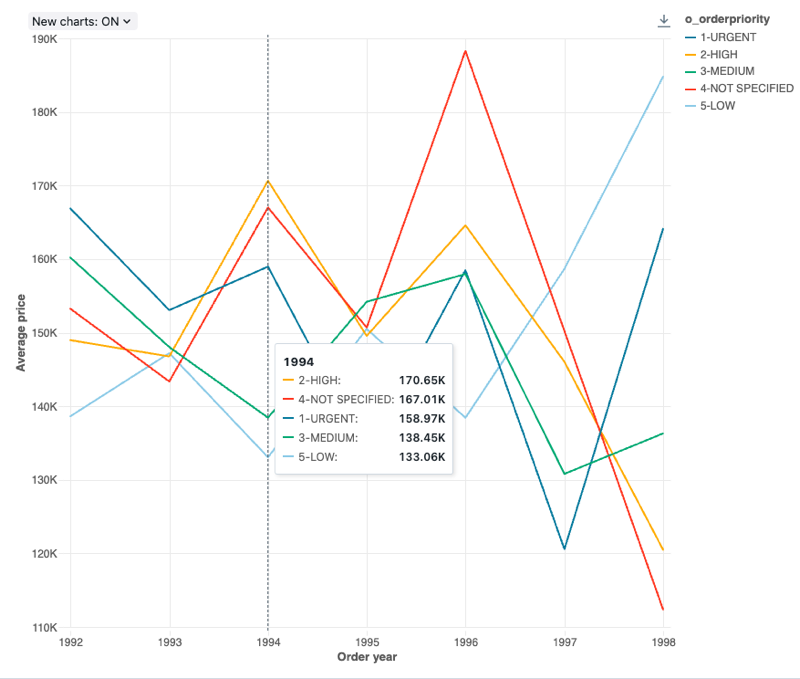
構成値 : この折れ線グラフの視覚化では、次の値が設定されました。
-
X 列:
- データセット列:
o_orderdate - 日付レベル:
Years
- データセット列:
-
Y 列:
- データセット列:
o_totalprice - 集計の種類:
Average
- データセット列:
-
グループ化 (データセット列):
o_orderpriority -
X 軸名 (デフォルト値を上書き):
Order year -
Y 軸の名前 (デフォルト値を上書き):
Average price
構成オプション : 折れ線グラフの構成オプションについては、「 グラフの構成オプション」を参照してください。
SQL クエリ : この折れ線グラフの視覚化では、次の SQL クエリを使用してデータ セットが生成されました。
select * from samples.tpch.orders
地図 (コロプレス) の視覚化
コロプレスのビジュアライゼーションでは、国や州などの地理的地域は、各キー列の集計値に従って色付けされます。 クエリは、地理的な場所を名前で返す必要があります。
コロプレスの視覚化では、結果セット内のデータの集計は行われません。 すべての集計は、クエリ自体内でコンピュートする必要があります。
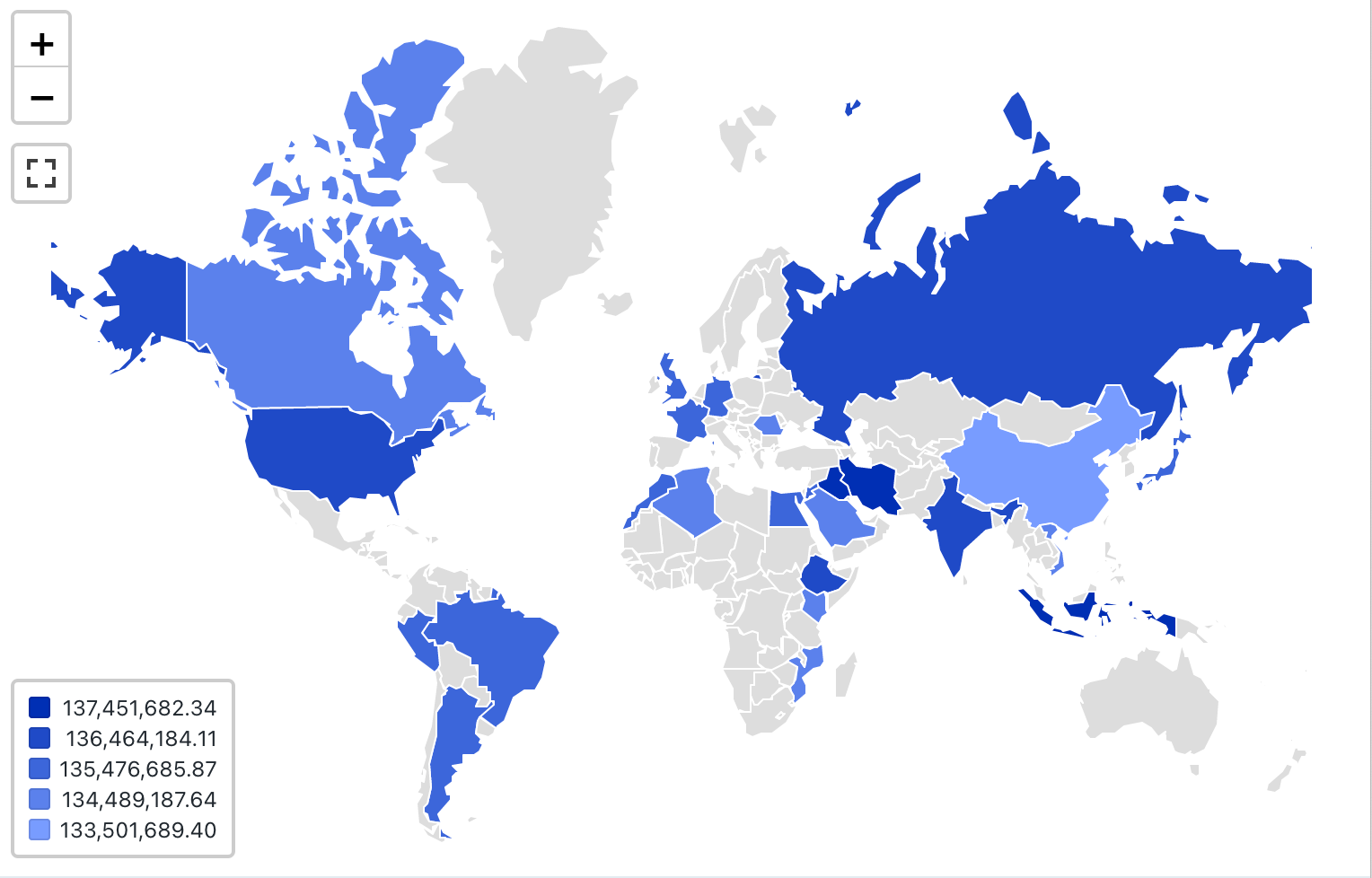
設定値 :このコロプレスの視覚化では、次の値が設定されました:
- マップ(データセット列):
Countries - 地理的列 (データセット列):
Country - 地理的タイプ:ショートネーム
- 値列 (データセット列):
Revenue - クラスタリングモード:等距離
構成オプション : コロプレス構成オプションについては、 コロプレス構成オプションを参照してください。
SQL クエリ : このコロプレスの視覚化では、次の SQL クエリを使用してデータ セットが生成されました。
SELECT
initcap(n_name) as Country,
sum(c_acctbal)
FROM samples.tpch.customer
join samples.tpch.nation where n_nationkey = c_nationkey
GROUP BY 1
地図(マーカー)の視覚化
マーカーの視覚化では、マーカーはマップ上の一連の座標に配置されます。 クエリ結果は、緯度と経度のペアを返す必要があります。
Marker は、結果セット内のデータの集計を行いません。 すべての集計は、クエリ自体内でコンピュートする必要があります。
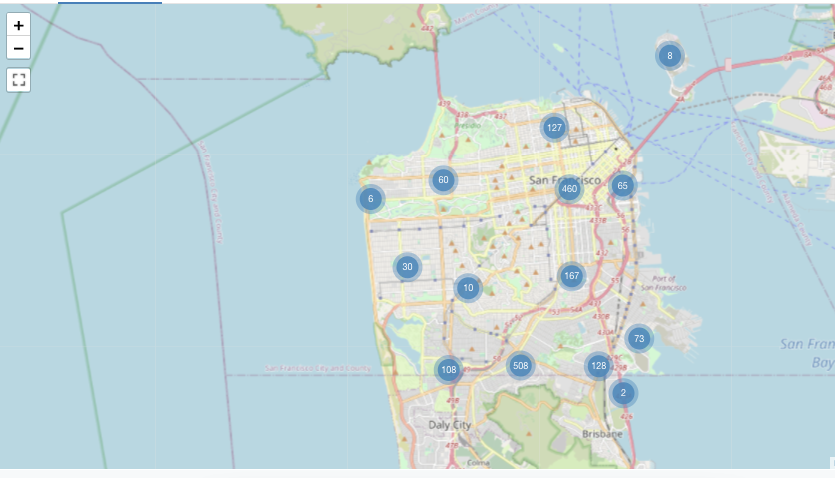
このマーカーの例は、 Databricks サンプル データセットでは使用できません。 コロプレスの設定オプションについては、 マーカーの設定オプションを参照してください。
円グラフ
チャートは、メトリクス間の比例関係を示しています。 時系列データを伝達するための ものではありません 。
円グラフはバックエンド集計をサポートしており、結果セットを切り捨てることなく 64K 行を超えるデータを返すクエリをサポートします。
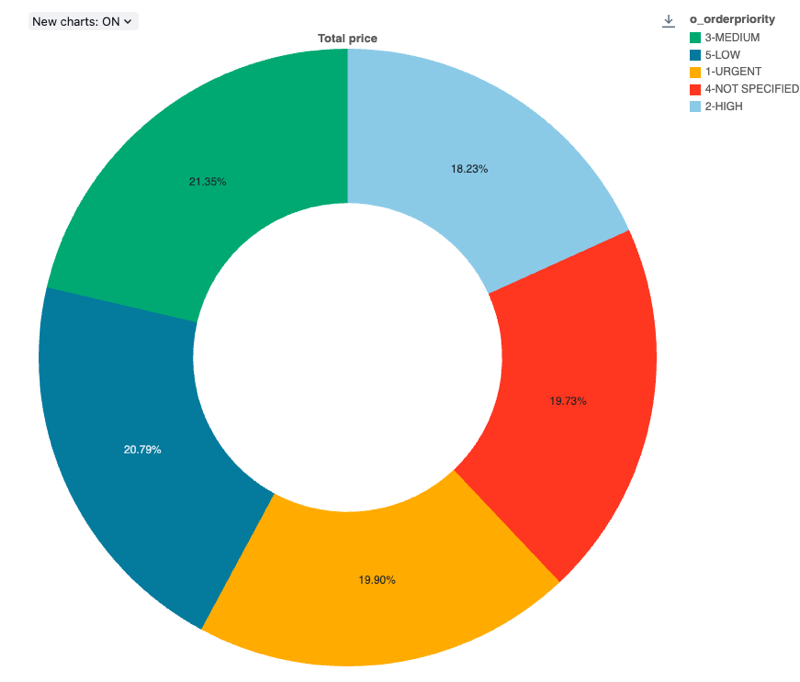
構成値 : この円グラフの視覚化では、次の値が設定されました。
-
X 列 (データセット列):
o_orderpriority -
Y 列:
- データセット列:
o_totalprice - 集計の種類:
Sum
- データセット列:
-
ラベル (オーバーライド デフォルト値):
Total price
構成オプション : 円グラフの構成オプションについては、 グラフの構成オプションを参照してください。
SQL クエリ : この円グラフの視覚化では、次の SQL クエリを使用してデータ セットが生成されました。
select * from samples.tpch.orders
ピボットテーブルの視覚化
ピボット テーブルの視覚化は、クエリ結果のレコードを新しい表形式表示に集計します。これは、SQL の PIVOT ステートメントや GROUP BY ステートメントに似ています。ピボットテーブルのビジュアライゼーションは、ドラッグ&ドロップフィールドを使用して設定します。
ピボットテーブルはバックエンド集計をサポートしており、結果セットを切り捨てることなく 64K 行を超えるデータを返すクエリをサポートします。 ただし、ピボット テーブル (レガシ) では、最大 64,000 行の集計のみがサポートされます。 データセットが 64,000 行を超える場合、データは切り捨てられます。
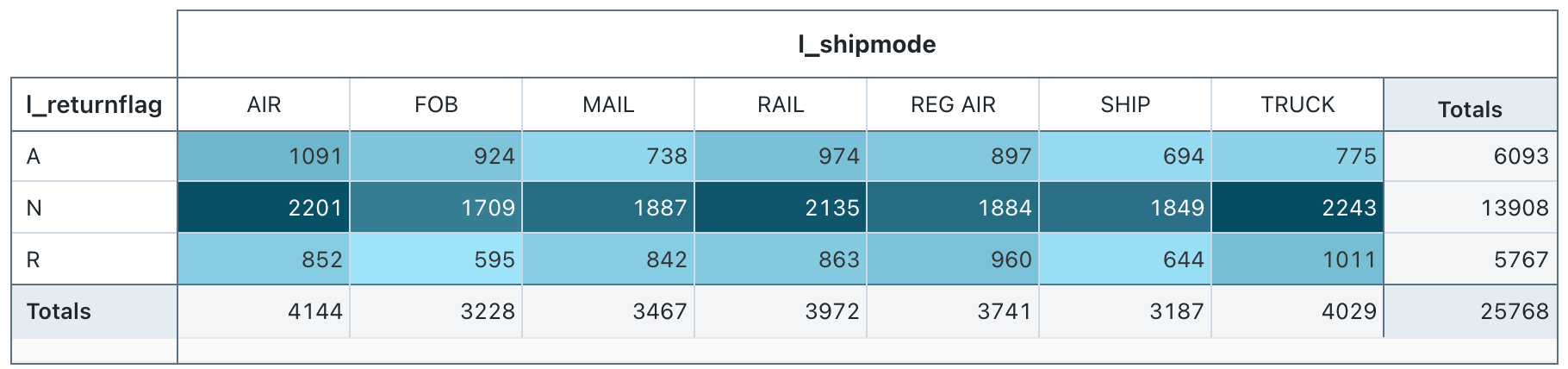
設定値 :このピボットテーブルのビジュアライゼーションでは、次の値が設定されました:
- 行の選択 (データセット列):
l_returnflag - 列の選択 (データセット列):
l_shipmode - セル
- データセット列:
l_quantity - 集計の種類: 合計
- 値によるセルの色付け: オン
- データセット列:
SQL クエリ : このピボット テーブルの視覚化では、次の SQL クエリを使用してデータ セットが生成されました。
select * from samples.tpch.lineitem
サンキー
サンキー図は、ある値セットから別の値セットへのフローを視覚化します。
サンキーの視覚化では、結果セット内のデータの集計は行われません。 すべての集計は、クエリ自体内でコンピュートする必要があります。

SQL クエリ : この サンキー ビジュアライゼーションでは、次の SQL クエリを使用してデータ セットが生成されました。
SELECT pickup_zip as stage1, dropoff_zip as stage2, sum(fare_amount) as value
FROM samples.nyctaxi.trips
GROUP BY 1, 2
ORDER BY 3 DESC
LIMIT 10
散布図
散布図の視覚化は、2 つの数値変数間の関係を示すためによく使用されます。 さらに、3 番目の次元を色でエンコードして、数値変数がグループ間でどのように異なるかを示すことができます。
散布図はバックエンド集計をサポートしており、結果セットを切り捨てることなく 64K 行を超えるデータを返すクエリをサポートします。
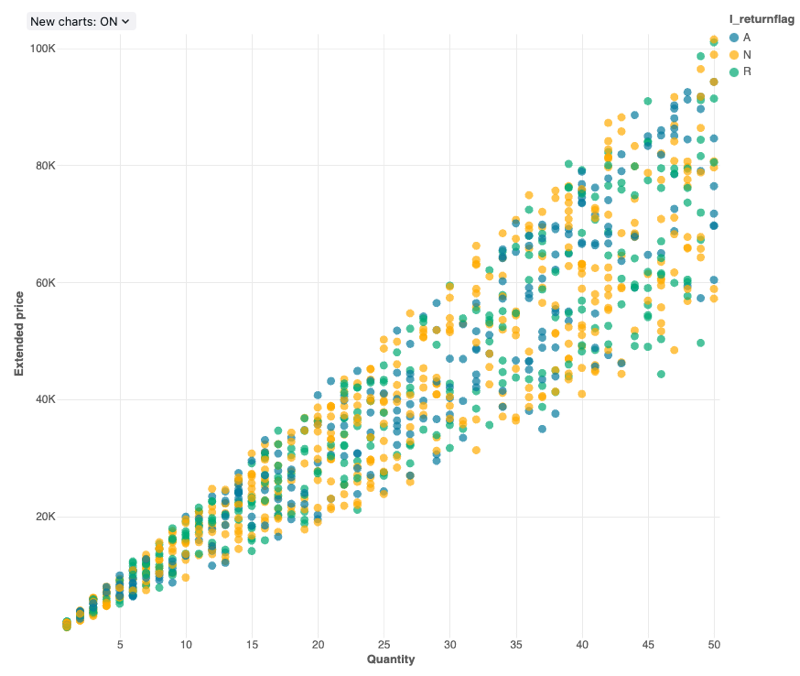
構成値 : この散布図の視覚化では、次の値が設定されました。
- X 列 (データセット列):
l_quantity - Y 列 (データセット列):
l_extendedprice - グループ化 (データセット列):
l_returnflag - X 軸名 (デフォルト値を上書き):
Quantity - Y 軸の名前 (デフォルト値を上書き):
Extended price
構成オプション : 散布図の構成オプションについては、 グラフの構成オプションを参照してください。
SQL クエリ : この散布図の視覚化では、次の SQL クエリを使用してデータ セットが生成されました。
select * from samples.tpch.lineitem
サンバーストシーケンス
サンバースト図は、同心円を使用して階層データを視覚化するのに役立ちます。
サンバースト シーケンスは、結果セット内のデータの集計を行いません。 すべての集計は、クエリ自体内でコンピュートする必要があります。
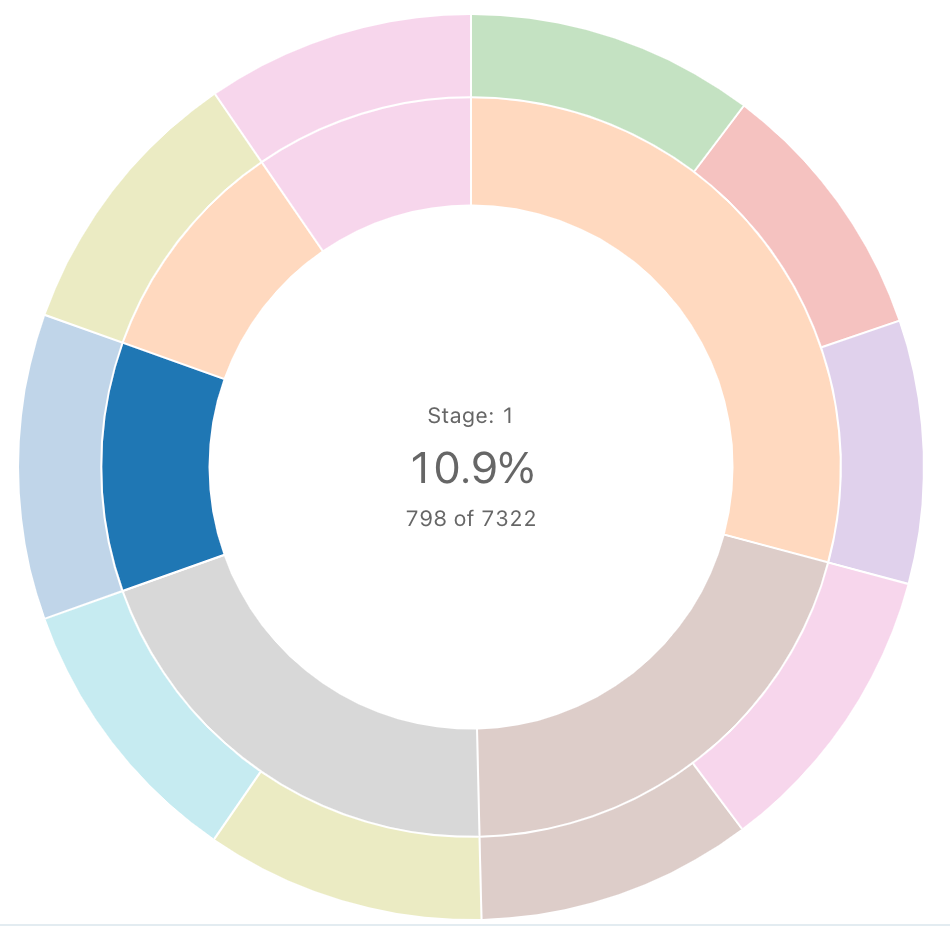
SQL クエリ : このサンバーストの視覚化では、次の SQL クエリを使用してデータセットが生成されました。
SELECT pickup_zip as stage1, dropoff_zip as stage2, sum(fare_amount) as value
FROM samples.nyctaxi.trips
GROUP BY 1, 2
ORDER BY 3 DESC
LIMIT 10
テーブル
テーブルのビジュアライゼーションでは、標準のテーブルにデータが表示されますが、データを手動で並べ替えたり、非表示にしたり、フォーマットしたりすることもできます。 テーブルの視覚化では、最大 100,000 行を表示できます。
テーブルの視覚化では、結果セット内のデータの集計は行われません。 すべての集計は、クエリ自体内でコンピュートする必要があります。
書式設定では、画像、JSON、URL などの特殊なデータ型がサポートされています。 詳細については、 テーブル設定オプションを参照してください。
ワードクラウド
ワードクラウドは、データ内で単語が発生する頻度を視覚的に表します。
ワード クラウドは、最大 64,000 行の集計のみをサポートします。 データセットが 64,000 行を超える場合、データは切り捨てられます。
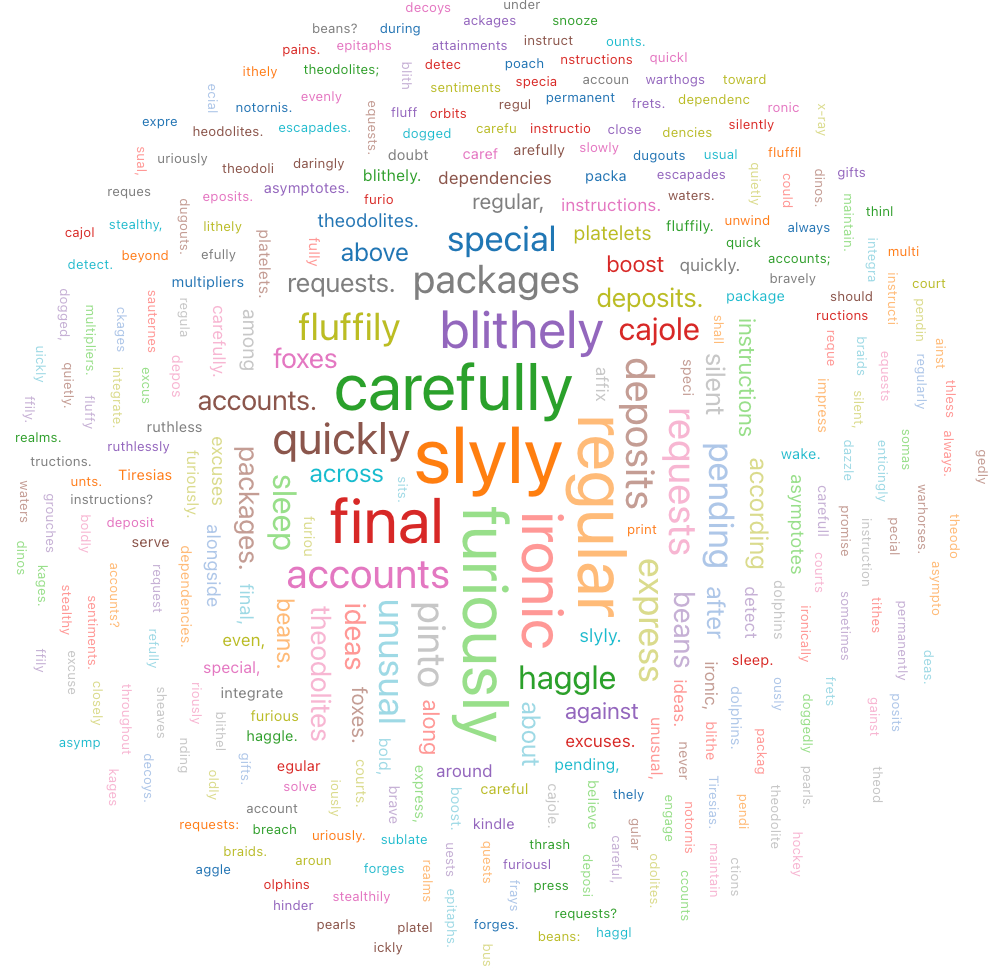
設定値 :このワードクラウドビジュアライゼーションでは、次の値が設定されました。test
- Words 列 (データセット列):
o_comment - 単語の長さ制限: 最小 = 5
- 周波数制限:最小= 2
SQL クエリ : このワード クラウド視覚化では、次の SQL クエリを使用してデータ セットが生成されました。
select * from samples.tpch.orders