Databricks Connect for R
Este artigo aborda a integração sparklyr com Databricks Connect para Databricks Runtime 13.0 e acima. Essa integração não é fornecida pela Databricks nem tem suporte direto da Databricks.
Em caso de dúvidas, acesse o Posit comunidade.
Para relatar problemas, acesse a seção Problemas do repositório sparklyr no GitHub.
Para obter mais informações, consulte Databricks Connect v2 na documentação sparklyr.
Databricks Connect permite que o senhor conecte IDEs populares, como RStudio Desktop, servidores de notebook e outros aplicativos personalizados ao Databricks clustering. Consulte O que é o Databricks Connect?
Databricks Connect tem compatibilidade limitada com Apache Spark MLlibpois o Spark MLlib usa RDDs, enquanto o Databricks Connect suporta apenas o DataFrame API. Para usar todas as Sparklyr Spark MLlib funções do, use o Databricks Notebook ou a db_repl função do pacote brickster.
Este artigo demonstra como começar rapidamente com Databricks Connect para R usando sparklyr e RStudio Desktop.
- Para obter informações sobre o Databricks Connect para Python, consulte Databricks Connect para Python.
- Para obter informações sobre o Databricks Connect para Scala, consulte Databricks Connect para Scala.
tutorial
No seguinte tutorial o senhor cria um projeto em RStudio, instala e configura Databricks Connect para Databricks Runtime 13.3 LTS e acima, e executa um código simples em compute em seu Databricks workspace a partir de RStudio. Para obter informações complementares sobre este tutorial, consulte a seção "Databricks Connect" do Spark Connect e Databricks Connect v2 no site sparklyr.
Este tutorial usa o RStudio Desktop e o Python 3.10. Se ainda não os tiver instalado, instale o R e o RStudio Desktop e o Python 3.10.
Requisitos
Para completar este tutorial, você deve atender aos seguintes requisitos:
- Seu destino Databricks workspace e o clustering devem atender aos requisitos de configuração de computação para Databricks Connect.
- O senhor deve ter seu ID de cluster disponível. Para obter o ID do cluster, no site workspace, clique em compute na barra lateral e, em seguida, clique no nome do cluster. Na barra de endereços do navegador da Web, copie as sequências de caracteres entre
clusterseconfigurationno URL.
Etapa 1: Criar tokens de acesso pessoal
Atualmente, a autenticação do Databricks Connect for R é compatível apenas com os tokens de acesso pessoal da Databricks.
Este tutorial usa a Databricks autenticação de tokens de acesso pessoal para autenticação com seu Databricks workspace.
Se o senhor já tiver tokens de acesso pessoal Databricks, pule para a Etapa 2. Se não tiver certeza de que já possui tokens de acesso pessoal Databricks, siga esta etapa sem afetar nenhum outro acesso pessoal Databricks tokens no seu usuário account.
Para criar um access token pessoal, siga os passos em Criar access tokens pessoais para usuários workspace.
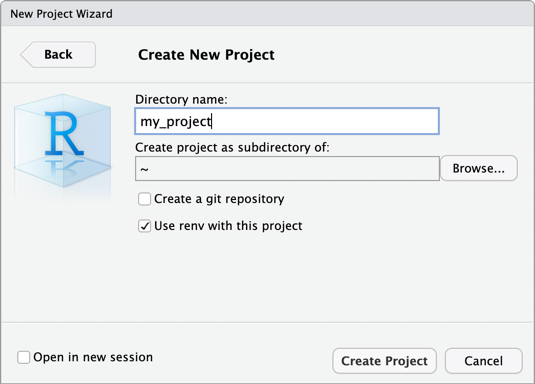
Etapa 2: criar o projeto
- RStudio Desktop.
- No menu principal, clique em Arquivo > Novo projeto .
- Selecione Novo diretório .
- Selecione Novo projeto .
- Em Nome do diretório e Criar projeto como subdiretório de , insira o nome do novo diretório do projeto e onde criar esse novo diretório do projeto.
- Selecione Usar renv com este projeto . Se for solicitado que o senhor instale uma versão atualizada do pacote
renv, clique em Yes . - Clique em Criar projeto .
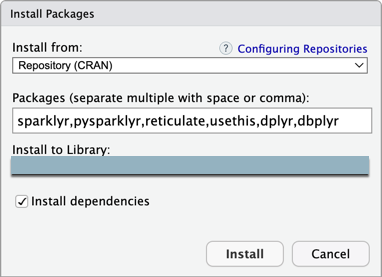
Etapa 3: Adicionar o pacote Databricks Connect e outras dependências
-
No menu principal do RStudio Desktop, clique em Tools > Install pacote .
-
Deixar Instalar do conjunto para o Repositório (CRAN) .
-
Para o pacote , insira a seguinte lista de pacotes que são pré-requisitos para o pacote Databricks Connect e este tutorial:
sparklyr,pysparklyr,reticulate,usethis,dplyr,dbplyr -
Deixe o Install to biblioteca configurado para seu ambiente virtual do R.
-
Certifique-se de que Instalar dependências esteja selecionado.
-
Clique em Instalar .
-
Quando o senhor for solicitado no Console view (view > Move Focus to Console ) a prosseguir com a instalação, digite
Y. Os pacotessparklyrepysparklyre suas dependências estão instalados em seu ambiente virtual do R. -
No painel Console , use
reticulatepara instalar o Python executando o seguinte comando. (O Databricks Connect for R requer a instalação prévia doreticulatee do Python). No comando a seguir, substitua3.10pela versão maior e menor da versão Python que está instalada no cluster Databricks. Para encontrar essa versão maior e menor, consulte a seção "Ambiente do sistema" das notas sobre a versão da versão do seu cluster Databricks Runtime em Databricks Runtime notas sobre a versão versões e compatibilidade.reticulate::install_python(version = "3.10") -
No painel Console , instale o pacote Databricks Connect executando o seguinte comando. No comando a seguir, substitua
13.3pela versão Databricks Runtime que está instalada em seu cluster Databricks. Para encontrar essa versão, na página de detalhes do seu clustering em Databricks workspace, em Configuration tab, consulte a caixa Databricks Runtime Version .pysparklyr::install_databricks(version = "13.3")Se o senhor não souber a versão do Databricks Runtime para o seu clustering ou não quiser procurá-la, poderá executar o seguinte comando e
pysparklyrconsultará o clustering para determinar a versão correta do Databricks Runtime a ser usada:pysparklyr::install_databricks(cluster_id = "<cluster-id>")Se quiser que o projeto se conecte posteriormente a um clustering diferente que tenha a mesma versão do Databricks Runtime que o que o senhor acabou de especificar,
pysparklyrusará o mesmo ambiente Python. Se o novo clustering tiver uma versão diferente do Databricks Runtime, o senhor deverá executar o comandopysparklyr::install_databricksnovamente com a nova versão do Databricks Runtime ou ID do clustering.
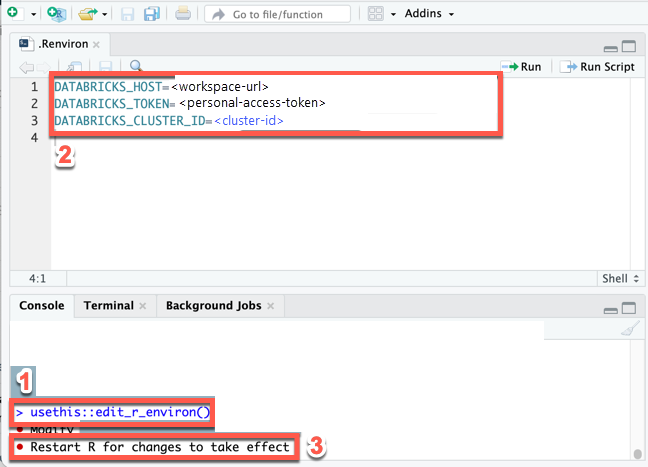
Etapa 4: Definir a variável de ambiente para o URL workspace, tokens de acesso e ID de clustering
Databricks não recomenda que o senhor codifique valores confidenciais ou variáveis, como o URL Databricks workspace , os tokens de acesso pessoal Databricks ou o ID de agrupamento Databricks nos scripts R. Em vez disso, armazene esses valores separadamente, por exemplo, na variável local de ambiente. Este tutorial usa o suporte integrado do RStudio Desktop para armazenar variáveis de ambiente em um arquivo .Renviron.
-
Crie um
.Renvironarquivo para armazenar a variável de ambiente, se esse arquivo ainda não existir, e abra-o para edição: no RStudio Console do Desktop, execute o seguinte comando:usethis::edit_r_environ() -
No arquivo
.Renvironque aparece (veja > Move Focus to Source ), insira o seguinte conteúdo. Neste conteúdo, substitua os seguintes espaços reservados:- Substitua
<workspace-url>pelo URL da instânciaworkspace, por exemplo,https://dbc-a1b2345c-d6e7.cloud.databricks.com. - Substitua
<personal-access-token>pelos tokens de acesso pessoal Databricks da Etapa 1. - Substitua
<cluster-id>pela ID de clustering dos requisitos deste tutorial.
DATABRICKS_HOST=<workspace-url>
DATABRICKS_TOKEN=<personal-access-token>
DATABRICKS_CLUSTER_ID=<cluster-id> - Substitua
-
Salve o arquivo
.Renviron. -
Carregue a variável de ambiente no R: no menu principal, clique em Session > Restart R .
Etapa 5: adicionar código
-
No menu principal do RStudio Desktop, clique em File > New File > R Script .
-
Insira o código a seguir no arquivo e salve-o ( Arquivo > Salvar ) como
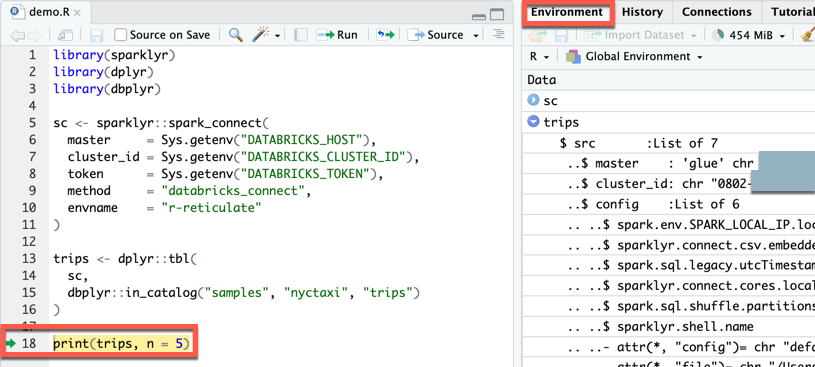
demo.R:Rlibrary(sparklyr)
library(dplyr)
library(dbplyr)
sc <- sparklyr::spark_connect(
master = Sys.getenv("DATABRICKS_HOST"),
cluster_id = Sys.getenv("DATABRICKS_CLUSTER_ID"),
token = Sys.getenv("DATABRICKS_TOKEN"),
method = "databricks_connect",
envname = "r-reticulate"
)
trips <- dplyr::tbl(
sc,
dbplyr::in_catalog("samples", "nyctaxi", "trips")
)
print(trips, n = 5)
Etapa 6: execução do código
-
Na área de trabalho do RStudio, na barra de ferramentas do arquivo
demo.R, clique em Source .
-
No console , as primeiras cinco linhas da tabela
tripsaparecem. -
No site Connections view (view > Show Connections ), o senhor pode explorar os catálogos, esquemas, tabelas e visualizações disponíveis.
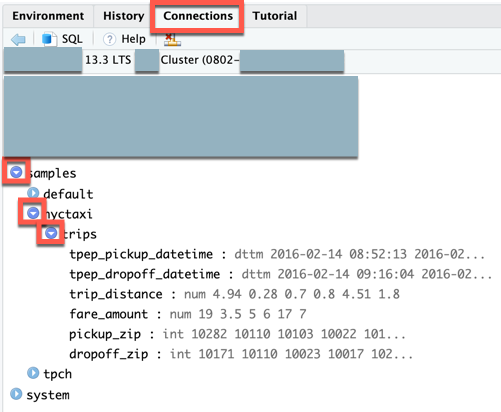
Etapa 7: depurar o código
- No arquivo
demo.R, clique na medianiz ao lado deprint(trips, n = 5)para definir um ponto de interrupção. - Na barra de ferramentas do arquivo
demo.R, clique em Código-fonte . - Quando o código pausa a execução no ponto de interrupção, o senhor pode inspecionar a variável no Environment view (view > Show Environment ).
- No menu principal, clique em Debug > Continue .
- No console , as primeiras cinco linhas da tabela
tripsaparecem.