Avaliação de solução de problemas (MLflow 2)
Este artigo descreve problemas que você pode encontrar ao avaliar aplicações de IA generativa utilizando o Mosaic AI Agent Evaluation e como corrigi-los.
Erros de modelo
mlflow.evaluate(..., model=<model>, model_type="databricks-agent") Invoca o modelo entregue em cada linha do conjunto de avaliação. A invocação do modelo pode falhar, por exemplo, se o modelo generativo estiver temporariamente indisponível. Se isso ocorrer, a saída incluirá as seguintes linhas, onde n é o número total de linhas avaliadas e k é o número de linhas com um erro:
**Evaluation completed**
- k/n contain model errors
Esse erro aparece na interface de usuário do MLFlow quando o senhor acessa view os detalhes de uma determinada linha do conjunto de análise.
O senhor também pode view o erro nos resultados da avaliação DataFrame. Nesse caso, você vê linhas nos resultados da avaliação contendo model_error_message. Para view esses erros, use o seguinte trecho de código:
result = mlflow.evaluate(..., model=<your model>, model_type="databricks-agent")
eval_results_df = result.tables['eval_results']
display(eval_results_df[eval_results_df['model_error_message'].notna()][['request', 'model_error_message']])

Se o erro for recuperável, você poderá executar novamente a avaliação somente nas linhas com falha:
result = mlflow.evaluate(..., model_type="databricks-agent")
eval_results_df = result.tables['eval_results']
# Filter rows where 'model_error_message' is not null and select columns required for evaluation.
input_cols = ['request_id', 'request', 'expected_retrieved_context', 'expected_response']
retry_df = eval_results_df.loc[
eval_results_df['model_error_message'].notna(),
[col for col in input_cols if col in eval_results_df.columns]
]
retry_result = mlflow.evaluate(
data=retry_df,
model=<your model>,
model_type="databricks-agent"
)
retry_result_df = retry_result.tables['eval_results']
merged_results_df = eval_results_df.set_index('request_id').combine_first(
retry_result.tables['eval_results'].set_index('request_id')
).reset_index()
# Reorder the columns to match the original eval_results_df column order
merged_results_df = merged_results_df[eval_results_df.columns]
display(merged_results_df)
A nova execução de mlflow.evaluate loga resultados e agrega métricas a uma nova execução do MLflow. O DataFrame mesclado gerado acima pode ser visto no notebook.
Erros do juiz
mlflow.evaluate(..., model_type="databricks-agent") avalia os resultados do modelo utilizando juízes incorporados e, opcionalmente, seus juízes personalizados. Os juízes podem deixar de avaliar uma linha de dados de entrada, por exemplo, devido a TOKEN_RATE_LIMIT_EXCEEDED ou MISSING_INPUT_FIELDS.
Se um juiz não avaliar uma linha, a saída conterá as seguintes linhas, onde n é o número total de linhas avaliadas e k é o número de linhas com um erro:
**Evaluation completed**
- k/n contain judge errors
Esse erro será exibido na interface do usuário do MLflow. Ao clicar em uma avaliação específica, os erros dos juízes serão exibidos sob seus nomes de avaliação correspondentes.

Nesse caso, você vê linhas nos resultados da avaliação contendo <judge_name>/error_message, por exemplo, response/llm_judged/faithfulness/error_message. Você pode visualizar esses erros utilizando o seguinte trecho de código:
result = mlflow.evaluate(..., model=<your model>, model_type="databricks-agent")
eval_results_df = result.tables['eval_results']
llm_judges_error_columns = [col for col in eval_results_df.columns if 'llm_judged' in col and 'error_message' in col]
columns_to_display = ['request_id', 'request'] + llm_judges_error_columns
# Display the filtered DataFrame
display(eval_results_df[eval_results_df[llm_judges_error_columns].notna().any(axis=1)][columns_to_display])
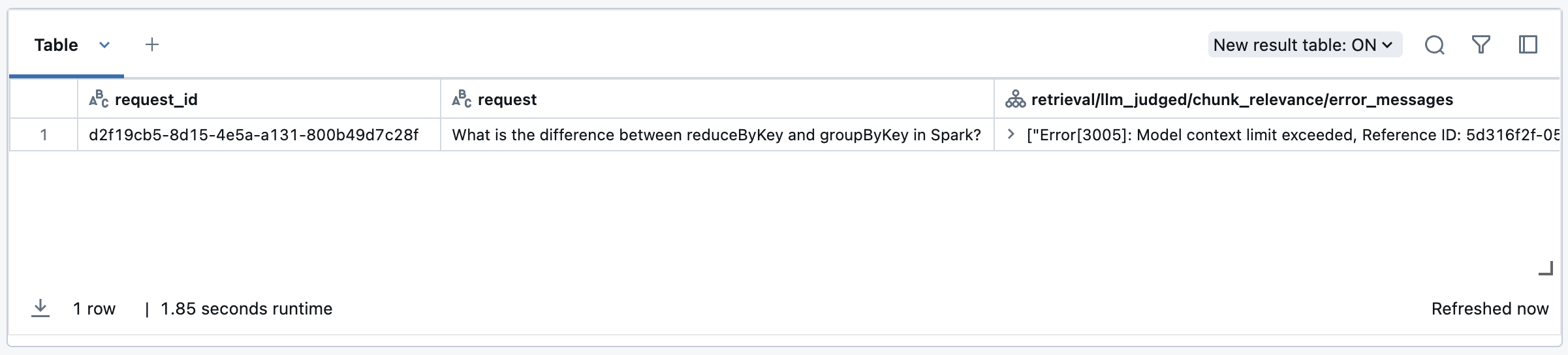
Depois que o erro for resolvido ou se for recuperável, você poderá executar novamente a avaliação somente nas linhas com falhas seguindo este exemplo:
result = mlflow.evaluate(..., model_type="databricks-agent")
eval_results_df = result.tables['eval_results']
llm_judges_error_columns = [col for col in eval_results_df.columns if 'llm_judges' in col and 'error_message' in col]
input_cols = ['request_id', 'request', 'expected_retrieved_context', 'expected_response']
retry_df = eval_results_df.loc[
eval_results_df[llm_judges_error_columns].notna().any(axis=1),
[col for col in input_cols if col in eval_results_df.columns]
]
retry_result = mlflow.evaluate(
data=retry_df,
model=<your model>,
model_type="databricks-agent"
)
retry_result_df = retry_result.tables['eval_results']
merged_results_df = eval_results_df.set_index('request_id').combine_first(
retry_result_df.set_index('request_id')
).reset_index()
merged_results_df = merged_results_df[eval_results_df.columns]
display(merged_results_df)
A nova execução de mlflow.evaluate loga resultados e agrega métricas a uma nova execução do MLflow. O DataFrame mesclado gerado acima pode ser visto no notebook.
Erros comuns
Se você continuar a encontrar esses códigos de erro, entre em contato com a equipe da sua conta do Databricks. A lista a seguir contém definições de códigos de erro comuns e como resolvê-los
Código de erro | O que significa | Resolução |
|---|---|---|
1001 | Campos de entrada ausentes | Revise e atualize os campos de entrada obrigatórios. |
1002 | Campos ausentes em alguns prompts de disparo | Revise e atualize os campos de entrada obrigatórios dos poucos exemplos fornecidos. Consulte Criar alguns exemplos simples. |
1005 | Campos inválidos em alguns prompts de disparo | Revise e atualize os campos de entrada obrigatórios dos poucos exemplos fornecidos. Consulte Criar alguns exemplos simples. |
3001 | Tempo limite de dependência | Revise o log e tente executar novamente seu agente. Entre em contato com sua account Databricks se o problema com tempo limite persistir. |
3003 | Limite da taxa de dependência excedido | Entre em contato com a equipe da sua conta da Databricks. |
3004 | Limite de taxa de token excedido | Entre em contato com a equipe da sua conta da Databricks. |
3006 | parceiros-powered AI recurso estão desativados. | Habilitar parceiros-powered AI recurso. Veja informações sobre os modelos que alimentam os juízes do LLM. |