Tutorial: Importar e visualizar dados do CSV de um Notebook
Este tutorial mostra como usar um Databricks Notebook para importar dados de um arquivo CSV contendo dados de nomes de bebês de health.data.ny.gov para seu volume Unity Catalog usando Python, Scala e R. Você também aprenderá a modificar o nome de uma coluna, visualizar os dados e salvá-los em uma tabela.
Requisitos
Para concluir a tarefa neste artigo, o senhor deve atender aos seguintes requisitos:
- O seu workspace deve estar habilitado. Unity Catalog ativado. Para obter informações sobre como iniciar o uso do Unity Catalog, consulte Iniciar o uso do Unity Catalog.
- Você deve ter o privilégio
WRITE VOLUMEem um volume, o privilégioUSE SCHEMAno esquema pai e o privilégioUSE CATALOGno catálogo principal. - Você precisa ter permissão para usar um recurso compute existente ou criar um novo recurso compute . Consulte a seção de computação ou entre em contato com o administrador Databricks .
Para ver um Notebook completo para esse artigo, consulte Importar e visualizar dados do Notebook.
Etapa 1: Criar um novo Notebook
Para criar um notebook no seu workspace, clique em ![]() Novo na barra lateral e clique em Notebook . Um notebook em branco será aberto no workspace.
Novo na barra lateral e clique em Notebook . Um notebook em branco será aberto no workspace.
Para saber mais sobre como criar e gerenciar o Notebook, consulte gerenciar o Notebook.
Etapa 2: Definir variáveis
Nesta etapa, o senhor define as variáveis a serem usadas no Notebook de exemplo que criou neste artigo.
- Copie e cole o código a seguir na nova célula vazia do Notebook. Substitua
<catalog-name>,<schema-name>e<volume-name>pelos nomes de catálogo, esquema e volume de um volume do Unity Catalog. Opcionalmente, substitua o valortable_namepor um nome de tabela de sua escolha. O senhor salvará os dados do nome do bebê nessa tabela mais adiante neste artigo. - Pressione
Shift+Enterpara executar a célula e criar uma nova célula em branco.
- Python
- Scala
- R
catalog = "<catalog_name>"
schema = "<schema_name>"
volume = "<volume_name>"
download_url = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv"
file_name = "baby_names.csv"
table_name = "baby_names"
path_volume = "/Volumes/" + catalog + "/" + schema + "/" + volume
path_table = catalog + "." + schema
print(path_table) # Show the complete path
print(path_volume) # Show the complete path
val catalog = "<catalog_name>"
val schema = "<schema_name>"
val volume = "<volume_name>"
val downloadUrl = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv"
val fileName = "baby_names.csv"
val tableName = "baby_names"
val pathVolume = s"/Volumes/${catalog}/${schema}/${volume}"
val pathTable = s"${catalog}.${schema}"
print(pathVolume) // Show the complete path
print(pathTable) // Show the complete path
catalog <- "<catalog_name>"
schema <- "<schema_name>"
volume <- "<volume_name>"
download_url <- "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv"
file_name <- "baby_names.csv"
table_name <- "baby_names"
path_volume <- paste("/Volumes/", catalog, "/", schema, "/", volume, sep = "")
path_table <- paste(catalog, ".", schema, sep = "")
print(path_volume) # Show the complete path
print(path_table) # Show the complete path
Etapa 3: Importar arquivo CSV
Nesta etapa, o senhor importa um arquivo CSV contendo dados de nomes de bebês do site health.data.ny.gov para o volume do Unity Catalog.
- Copie e cole o código a seguir na nova célula vazia do Notebook. Esse código copia o arquivo
rows.csvde health.data.ny.gov para o volume do Unity Catalog usando o comando Databricks dbutuils. - Pressione
Shift+Enterpara executar a célula e depois passar para a próxima célula.
- Python
- Scala
- R
dbutils.fs.cp(f"{download_url}", f"{path_volume}" + "/" + f"{file_name}")
dbutils.fs.cp(downloadUrl, s"${pathVolume}/${fileName}")
dbutils.fs.cp(download_url, paste(path_volume, "/", file_name, sep = ""))
Etapa 4: Carregar dados CSV em um DataFrame
Nesta etapa, você criará um DataFrame chamado df a partir do arquivo CSV que você carregou anteriormente em seu volume do Unity Catalog usando o método spark.read.csv.
- Copie e cole o código a seguir na nova célula vazia do notebook. Esse código carrega dados de nomes de bebês no DataFrame
dfa partir do arquivo CSV. - Pressione
Shift+Enterpara executar a célula e depois passar para a próxima célula.
- Python
- Scala
- R
df = spark.read.csv(f"{path_volume}/{file_name}",
header=True,
inferSchema=True,
sep=",")
val df = spark.read
.option("header", "true")
.option("inferSchema", "true")
.option("delimiter", ",")
.csv(s"${pathVolume}/${fileName}")
# Load the SparkR package that is already preinstalled on the cluster.
library(SparkR)
df <- read.df(paste(path_volume, "/", file_name, sep=""),
source="csv",
header = TRUE,
inferSchema = TRUE,
delimiter = ",")
Você pode carregar dados de vários formatos de arquivo compatíveis.
Etapa 5: Visualizar dados do Notebook
Neste passo, você usa o método display() para exibir o conteúdo do DataFrame em uma tabela do notebook e, em seguida, visualizar os dados em um gráfico de nuvem de palavras no notebook.
- Copie e cole o código a seguir na nova célula vazia do notebook e, em seguida, clique em Executar célula para exibir os dados em uma tabela.
- Python
- Scala
- R
display(df)
display(df)
display(df)
-
Analise os resultados da tabela.
-
Perto da guia Tabela , clique em + e, em seguida, clique em Visualização .
-
No editor de visualização, clique em Tipo de Visualização e verifique se a nuvem de palavras está selecionada.
-
Na coluna Palavras , verifique se
First Nameestá selecionado. -
Em Limite de frequências , clique em
35.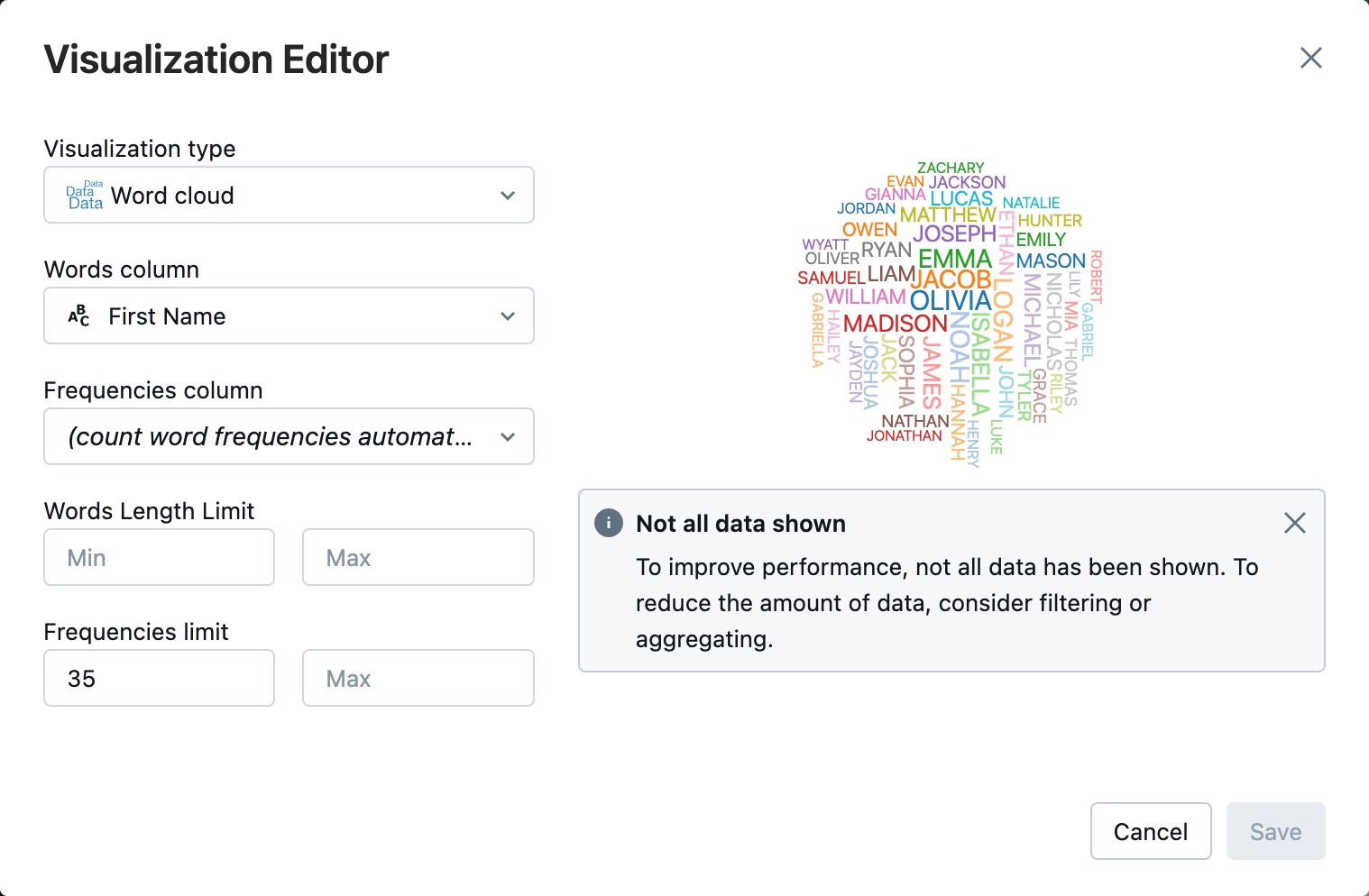
-
Clique em Salvar .
Etapa 6: Salvar o DataFrame em uma tabela
Para salvar seu DataFrame no Unity Catalog, o senhor deve ter privilégios de tabela CREATE no catálogo e no esquema. Para obter informações sobre permissões em Unity Catalog, consulte Privileges and securable objects em Unity Catalog e gerenciar privilégios em Unity Catalog.
- Copie e cole o código a seguir em uma célula vazia do Notebook. Esse código substitui um espaço no nome da coluna. Caracteres especiais, como espaços, não são permitidos nos nomes das colunas. Este código usa o método Apache Spark
withColumnRenamed().
- Python
- Scala
- R
df = df.withColumnRenamed("First Name", "First_Name")
df.printSchema
val dfRenamedColumn = df.withColumnRenamed("First Name", "First_Name")
// when modifying a DataFrame in Scala, you must assign it to a new variable
dfRenamedColumn.printSchema()
df <- withColumnRenamed(df, "First Name", "First_Name")
printSchema(df)
- Copie e cole o código a seguir em uma célula vazia do notebook. Esse código salva o conteúdo do DataFrame em uma tabela do Unity Catalog usando a variável do nome da tabela que você definiu no início deste artigo.
- Python
- Scala
- R
df.write.mode("overwrite").saveAsTable(f"{path_table}" + "." + f"{table_name}")
dfRenamedColumn.write.mode("overwrite").saveAsTable(s"${pathTable}.${tableName}")
saveAsTable(df, paste(path_table, ".", table_name), mode = "overwrite")
-
Para verificar se a tabela foi salva, clique em Catálogo na barra lateral esquerda para abrir a interface do usuário do Catalog Explorer. Abra seu catálogo e, em seguida, seu esquema, para verificar se a tabela aparece.
-
Clique em sua tabela para visualizar o esquema da tabela na guia Visão geral .
-
Clique em Dados de Amostra para visualizar 100 linhas de dados da tabela.
Importação e visualização de dados Notebook
Use um dos seguintes Notebooks para executar as etapas deste artigo. Substitua <catalog-name>, <schema-name> e <volume-name> pelos nomes de catálogo, esquema e volume de um volume do Unity Catalog. Opcionalmente, substitua o valor table_name por um nome de tabela de sua escolha.
- Python
- Scala
- R
Importar dados de CSV usando Python
Importar dados de CSV usando Scala
Importar dados de CSV usando o R
Próximas etapas
- Para saber mais sobre as técnicas de análise exploratória de dados (EDA), consulte o tutorial: EDA techniques using Databricks Notebook.
- Para aprender a criar um pipeline ETL (extração, transformação e carregamento), consulte o tutorial: Criar um pipeline ETL com o pipeline declarativo LakeFlow Spark e o tutorial: Criar um pipeline ETL com Apache Spark na plataforma Databricks .