Tutorial: Consultar e visualizar dados de um Notebook
Este tutorial mostra como usar um Databricks Notebook para consultar dados de amostra armazenados no Unity Catalog usando SQL, Python, Scala e R e, em seguida, visualizar os resultados da consulta no Notebook.
Diga ao Genie Code (modo Agente) para fazer isso por você:
Create a new notebook that queries @samples.nyctaxi.trips and displays a bar chart showing the average fare amount by trip distance, grouped by the pickup zip code.
Requisitos
Para concluir a tarefa neste artigo, o senhor deve atender aos seguintes requisitos:
- O site workspace deve ter Unity Catalog habilitado. Para obter informações sobre como começar com Unity Catalog, consulte Get começar with Unity Catalog.
- Você precisa ter permissão para usar um recurso compute existente ou criar um novo recurso compute . Consulte a seção de computação ou entre em contato com o administrador Databricks .
Etapa 1: Criar um novo Notebook
Para criar um notebook no seu workspace, clique em ![]() Novo na barra lateral e clique em Notebook . Um notebook em branco será aberto no workspace.
Novo na barra lateral e clique em Notebook . Um notebook em branco será aberto no workspace.
Para saber mais sobre como criar e gerenciar Notebooks, consulte Gerenciar Notebooks do Databricks.
Etapa 2: consultar uma tabela
Consulte a tabela samples.nyctaxi.trips no Unity Catalog usando o idioma de sua escolha. Esta tabela é um dos conjuntos de dados de amostra incluídos no catálogo samples.
- Copie e cole o código a seguir na nova célula vazia do Notebook. Este código exibe os resultados da consulta da tabela
samples.nyctaxi.tripsno Unity Catalog.
- SQL
- Python
- Scala
- R
SELECT * FROM samples.nyctaxi.trips
display(spark.read.table("samples.nyctaxi.trips"))
display(spark.read.table("samples.nyctaxi.trips"))
library(SparkR)
display(sql("SELECT * FROM samples.nyctaxi.trips"))
-
Pressione
Shift+Enterpara executar a célula e depois passar para a próxima célula.Os resultados da consulta aparecem no Notebook.
Etapa 3: exibir os dados
Exiba o valor médio da tarifa por distância da viagem, agrupado pelo CEP de coleta.
-
Perto da guia Tabela , clique em + e, em seguida, clique em Visualização .
O editor de visualização é exibido.
-
No menu suspenso Visualization Type (Tipo de visualização ), verifique se Bar está selecionado.
-
Selecione
fare_amountpara a coluna X. -
Selecione
trip_distancepara a coluna Y. -
Selecione
Averagecomo o tipo de agregação. -
Selecione
pickup_zipcomo Agrupar por coluna.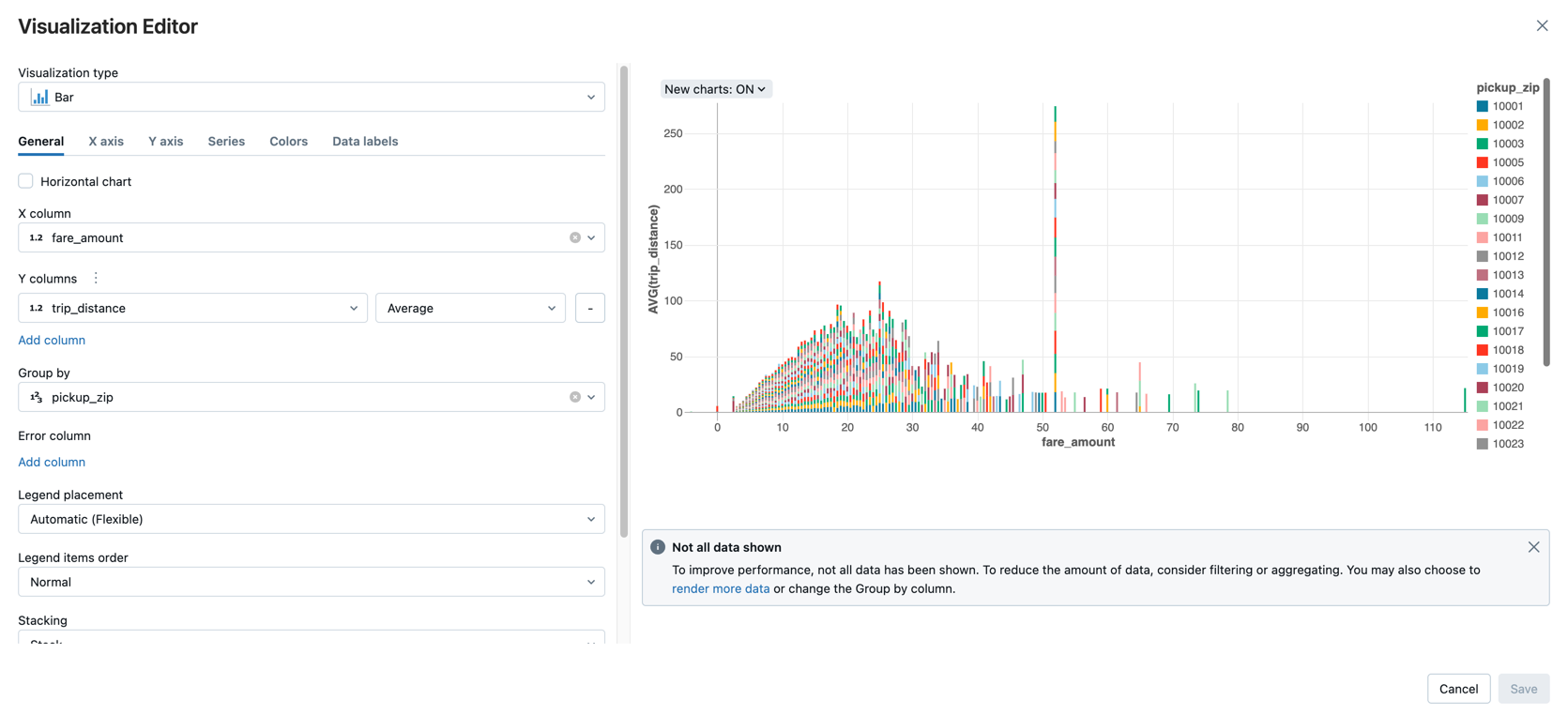
-
Clique em Salvar .
Próximas etapas
- Para saber mais sobre como adicionar dados do arquivo CSV ao Unity Catalog e visualizar dados, consulte o tutorial: Importar e visualizar dados de CSV de um Notebook.
- Para saber como carregar dados em Databricks usando Apache Spark, consulte o tutorial: Carregamento e transformação de dados usando Apache Spark DataFrames .
- Para saber mais sobre a ingestão de dados em Databricks, consulte Conectores padrão em LakeFlow Connect.
- Para saber mais sobre a consulta de dados com o Databricks, consulte Consultar dados.
- Para saber mais sobre visualizações, consulte Visualizações no Databricks Notebook e no editor SQL.
- Para saber mais sobre as técnicas de análise exploratória de dados (EDA), consulte o tutorial: EDA techniques using Databricks Notebook.